SQL练习题
练习一
准备数据
建表语句
CREATE TABLE students
(sno VARCHAR(3) NOT NULL,
sname VARCHAR(4) NOT NULL,
ssex VARCHAR(2) NOT NULL,
sbirthday DATETIME,
class VARCHAR(5));
CREATE TABLE courses
(cno VARCHAR(5) NOT NULL,
cname VARCHAR(10) NOT NULL,
tno VARCHAR(10) NOT NULL);
CREATE TABLE scores
(sno VARCHAR(3) NOT NULL,
cno VARCHAR(5) NOT NULL,
degree NUMERIC(10, 1) NOT NULL);
CREATE TABLE teachers
(tno VARCHAR(3) NOT NULL,
tname VARCHAR(4) NOT NULL, tsex VARCHAR(2) NOT NULL,
tbirthday DATETIME NOT NULL, prof VARCHAR(6),
depart VARCHAR(10) NOT NULL);插入数据
INSERT INTO STUDENTS (sno, sname, ssex, sbrithday, class) VALUES (108 ,'曾华' ,'男' ,'1977-09-01',95033);
INSERT INTO STUDENTS (sno, sname, ssex, sbrithday, class) VALUES (105 ,'匡明' ,'男' ,'1975-10-02',95031);
INSERT INTO STUDENTS (sno, sname, ssex, sbrithday, class) VALUES (107 ,'王丽' ,'女' ,'1976-01-23',95033);
INSERT INTO STUDENTS (sno, sname, ssex, sbrithday, classS) VALUES (101 ,'李军' ,'男' ,'1976-02-20',95033);
INSERT INTO STUDENTS (sno, sname, ssex, sbrithday, class) VALUES (109 ,'王芳' ,'女' ,'1975-02-10',95031);
INSERT INTO STUDENTS (sno, sname, ssex, sbrithday, class) VALUES (103 ,'陆君' ,'男' ,'1974-06-03',95031);
INSERT INTO COURSES(cno, cname, tno) VALUES ('3-105' ,'计算机导论',825);
INSERT INTO COURSES(cno, cname, tno) VALUES ('3-245' ,'操作系统' ,804);
INSERT INTO COURSES(cno, cname, tno) VALUES ('6-166' ,'数据电路' ,856);
INSERT INTO COURSES(cno, cname, tno) VALUES ('9-888' ,'高等数学' ,100);
INSERT INTO SCORES(sno, cno, degree) VALUES (103,'3-245',86);
INSERT INTO SCORES(sno, cno, degree) VALUES (105,'3-245',75);
INSERT INTO SCORES(sno, cno, degree) VALUES (109,'3-245',68);
INSERT INTO SCORES(sno, cno, degree) VALUES (103,'3-105',92);
INSERT INTO SCORES(sno, cno, degree) VALUES (105,'3-105',88);
INSERT INTO SCORES(sno, cno, degree) VALUES (109,'3-105',76);
INSERT INTO SCORES(sno, cno, degree) VALUES (101,'3-105',64);
INSERT INTO SCORES(sno, cno, degree) VALUES (107,'3-105',91);
INSERT INTO SCORES(sno, cno, degree) VALUES (108,'3-105',78);
INSERT INTO SCORES(sno, cno, degree) VALUES (101,'6-166',85);
INSERT INTO SCORES(sno, cno, degree) VALUES (107,'6-166',79);
INSERT INTO SCORES(sno, cno, degree) VALUES (108,'6-166',81);
INSERT INTO TEACHERS(tno, tname, tsex, tbirthday, prof, depart) VALUES (804,'李诚','男','1958-12-02','副教授','计算机系');
INSERT INTO TEACHERS(tno, tname, tsex, tbirthday, prof, depart) VALUES (856,'张旭','男','1969-03-12','讲师','电子工程系');
INSERT INTO TEACHERS(tno, tname, tsex, tbirthday, prof, depart) VALUES (825,'王萍','女','1972-05-05','助教','计算机系');
INSERT INTO TEACHERS(tno, tname, tsex, tbirthday, prof, depart) VALUES (831,'刘冰','女','1977-08-14','助教','电子工程系');练习题
查询student表中的所有记录的sname、ssex和class列。
解答:
SELECT sname, ssex, class FROM students;查询教师所有的单位,即不重复的depart列。
解答:
SELECT DISTINCT depart FROM teachers;查询students表的所有记录。
解答:
SELECT * FROM students;查询scores表中成绩在60到80之间的所有记录。
解答:
# 方法一 SELECT * FROM scores WHERE degree >= 60 AND degree <= 80; # 方法二 SELECT * FROM scores WHERE degree BETWEEN 60 AND 80;★查询scores表中成绩为85,86或88的记录。
解答:
# 方法一 SELECT * FROM scores WHERE degree IN (85, 86, 88); # 方法二 SELECT * FROM scores WHERE degree = 85 OR degree = 86 OR degree = 88;查询students表中**“95031”班或性别为“女”**的同学记录。
解答:
SELECT * FROM students WHERE class = '95031' OR ssex = '女';以class降序查询students表的所有记录。
解答:
SELECT * FROM students ORDER BY class DESC;★以cno升序、degree降序查询scores表的所有记录。
解答:
SELECT * FROM scores ORDER BY con, degree DESC;查询student表中“95031”班的学生人数。
解答:
SELECT COUNT(*) AS stu_num FROM students WHERE class = '95031';★★★查询scores表中的最高分的学生学号和课程号。
解答:子查询
SELECT sno, cno FROM scores WHERE degree = (SELECT MAX(degree) FROM scores);★查询scores表中‘3-105’号课程的平均分。
解答:
SELECT AVG(degree) FROM scores WHERE cno = '3-105';★★★查询scores表中至少有5名学生选修的并以3开头的课程的平均分数。
解答:分组(HAVING子句用于过滤分组)
# 方法一 SELECT cno, AVG(degree) AS avg_degree FROM scores WHERE cno LIKE '3%' GROUP BY cno HAVING COUNT(*) >= 5; # 方法二 SELECT cno, AVG(degree) AS avg_degree FROM scores GROUP BY cno HAVING COUNT(*) >= 5 AND cno LIKE '3%';★★★查询scores表中最低分大于70,最高分小于90的sno列。
解答:
SELECT sno FROM scores GROUP BY sno HAVING MIN(degree) > 70 AND MAX(degree) < 90;★★查询所有学生的sname、cno和degree列。
解答:
- 外部联结(OUTER JOIN, OUTER可省略)
- 内部联结(INNER JOIN)
# 方法一:外部联结, LEFT JOIN 左边的表 所有记录都会列出 SELECT stu.sname, sco.cno, sco.degree FROM students AS stu LEFT JOIN scores AS sco ON stu.sno = sco.sno ORDER BY sname; # 方法二:内部联结, INNER JOIN 只返回两个表中联结字段相等的行 SELECT stu.sname, sco.cno, sco.degree FROM students AS stu INNER JOIN scores AS sco ON stu.sno = sco.sno ORDER BY sname;★查询所有学生的sno、cname和degree列。
解答:外部联结
SELECT s.sno, c.cname, s.degree FROM scores AS s LEFT JOIN courses AS c ON s.cno = c.cno ORDER BY sno;★★★查询所有学生的sname、cname和degree列。
解答:外部联结
SELECT st.sname, c.cname, sc.degree FROM students AS st LEFT JOIN scores AS sc ON st.sno = sc.sno LEFT JOIN courses AS c ON sc.cno = c.cno ORDER BY sname;★★★查询“95033”班所选课程的平均分。
解答:
SELECT cname, AVG(degree) FROM students AS st INNER JOIN scores AS sc ON st.sno = sc.sno INNER JOIN courses AS c ON sc.cno = c.cno WHERE class = '95033' GROUP BY c.cno ORDER BY cname;★★★假设使用如下命令建立了一个grade表:
CREATE TABLE grade(low INT(3), upp INT(3), rank CHAR(1)); INSERT INTO grade VALUES(90,100,'A'); INSERT INTO grade VALUES(80,89,'B'); INSERT INTO grade VALUES(70,79,'C'); INSERT INTO grade VALUES(60,69,'D'); INSERT INTO grade VALUES(0,59,'E'); COMMIT;现查询所有同学的sno、cno和rank列。
解答:
SELECT sno, cno, rank FROM scores INNER JOIN grade ON scores.degree BETWEEN grade.low AND grade.upp ORDER BY sno;★★★查询选修“3-105”课程的成绩高于“109”号同学成绩的所有同学的记录。
解答:
- 自联结
SELECT sname, s1.degree FROM scores AS s1 INNER JOIN scores AS s2 ON s1.cno = s2.cno AND s1.degree > s2.degree INNER JOIN students AS st ON s1.sno = st.sno WHERE s1.cno = '3-105' AND s2.sno = '109' ORDER BY s1.degree;★★★查询scores中选学一门以上课程的同学中分数为非最高分成绩的记录。
解答:
- 条件:
- 选学一门以上课程
- 列出这些同学的所有非最高分成绩
SELECT scores.sno, cno, degree, max_degree FROM scores INNER JOIN (SELECT sno, MAX(degree) AS max_degree FROM scores GROUP BY sno HAVING COUNT(*) > 1) AS max ON scores.sno = max.sno AND degree < max_degree ORDER BY sno;- 条件:
查询成绩高于学号为“109”、课程号为“3-105”的成绩的所有记录。
解答:
SELECT st.sname, s1.cno, s1.degree FROM scores AS s1 INNER JOIN scores AS s2 ON s1.cno = s2.cno AND s1.degree > s2.degree INNER JOIN students AS st ON s1.sno = st.sno WHERE s1.cno = '3-105' AND s2.sno = '109' ORDER BY s1.degree;★★★查询和学号为108的同学同年出生的所有学生的sno、sname和sbirthday列。
解答:函数
YEAR(d)SELECT s1.sno, s1.sname, s1.sbirthday FROM students AS s1 INNER JOIN students AS s2 ON YEAR(s1.sbirthday) = YEAR(s2.sbirthday) WHERE s2.sno = '108' ORDER BY sbirthday;查询“张旭“教师任课的学生成绩。
解答:
SELECT sno, degree FROM scores INNER JOIN courses ON scores.cno = courses.cno INNER JOIN teachers ON courses.tno = teachers.tno WHERE teachers.tname = '张旭' ORDER BY degree;查询选修某课程的同学人数多于5人的教师姓名。
解答:
SELECT tname FROM scores AS s INNER JOIN courses AS c ON s.cno = c.cno INNER JOIN teachers AS t ON t.tno = c.tno GROUP BY c.cno HAVING COUNT(c.cno) > 5;查询95033班和95031班全体学生的记录。
解答:
SELECT * FROM students WHERE class IN ('95033', '95031') ORDER BY class;查询有85分以上成绩的课程cno。
解答:DISTINCT关键字
SELECT DISTINCT c.cno FROM scores WHERE degree > 85;查询出“计算机系“教师所教课程的成绩表。
解答:
SELECT t.tname, s.cno, cname, sno, degree FROM scores AS s INNER JOIN courses AS c ON s.cno = c.cno INNER JOIN teachers AS t ON t.tno = c.tno WHERE t.depart = '计算机系' ORDER BY t.tname, cname, degree DESC;查询“计算机系”中与“电子工程系“的教师不同职称教师的tname和prof。
解答:
SELECT tname, prof FROM teachers WHERE depart = '计算机系' AND prof NOT IN (SELECT prof FROM teachers WHERE depart = '电子工程系');查询选修编号为“3-105”课程且成绩至少高于任意选修编号为“3-245”的同学的成绩的cno、sno和degree。
解答:
SELECT cno, sno, degree FROM scores WHERE cno = '3-105' AND degree > (SELECT MIN(degree) FROM scores WHERE cno = '3-245') ORDER BY degree DESC;查询选修编号为”3-105“且成绩高于所有选修编号为”3-245“课程的同学的cno、sno和degree。
解答:
SELECT cno, sno, degree FROM scores WHERE cno = '3-105' AND degree > (SELECT MAX(degree) FROM scores WHERE cno = '3-245') ORDER BY degree DESC;查询所有教师和同学的name、sex和birthday。
解答:组合查询UNION
- UNION中每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
- 列数据类型必须兼容。类型不必完全相同,但必须是DBMS可以隐含地转换的类型(如不同的数值类型或不同的日期类型)。
SELECT tname AS name, tsex AS sex, tbirthday AS birthday FROM teachers UNION SELECT sname AS name, ssex AS sex, sbirthday AS birthday FROM students ORDER BY birthday;查询所有“女”教师和“女”同学的name、sex和birthday。
解答:
SELECT tname AS name, tsex AS sex, tbirthday AS birthday FROM teachers AS t WHERE t.tsex = '女' UNION SELECT sname AS name, ssex AS sex, sbirthday AS birthday FROM students AS s WHERE s.ssex = '女' ORDER BY birthday;★★★查询成绩比该课程平均成绩低的同学的成绩表。
解答:
SELECT s1.*, avg_degree FROM scores AS s1 INNER JOIN ( SELECT cno, AVG(degree) AS avg_degree FROM scores GROUP BY cno) AS s2 ON s1.cno = s2.cno AND s1.degree < s2.avg_degree;查询所有任课教师的tname和depart。
解答:
SELECT DISTINCT tname, depart FROM courses AS c INNER JOIN teachers AS t ON c.tno = t.tno ORDER BY tname; SELECT tname, depart FROM teachers WHERE tno IN( SELECT tno FROM courses) ORDER BY tname;★查询所有未讲课的教师的Tname和Depart。
解答:
SELECT tname, depart FROM teachers WHERE tno NOT IN( SELECT tno FROM courses) ORDER BY tname;★★查询至少有2名男生的班号。
解答:
SELECT class FROM students WHERE ssex = '男' GROUP BY class HAVING COUNT(*) >= 2;★查询students表中**不姓“王”**的同学记录。
解答:
- LIKE操作符
- 通配符%
SELECT * FROM students WHERE sname NOT LIKE '王%';★★查询students表中每个学生的姓名和年龄。
解答:
- 当前日期函数CURDATE()
- 当前日期和时间函数NOW()
SELECT sname, TIMESTAMPDIFF(YEAR, sbirthday, CURDATE()) AS age FROM students;★★查询students表中最大和最小的sbirthday日期值。
解答:
SELECT DATE(MAX(Sbirthday)) AS max_birthday, DATE(MIN(Sbirthday)) AS min_birthday, FROM Students;以班号和年龄从大到小的顺序查询students表中的全部记录。
解答:
SELECT * FROM students ORDER BY class DESC, TIMESTAMPDIFF(YEAR, sbirthday, CURDATE()) DESC;查询“男”教师及其所上的课程。
解答:
SELECT tname, cname FROM teachers AS t INNER JOIN courses AS c ON t.tno = c.tno WHERE tsex='男' ORDER BY tname;★查询最高分同学的sno、cno和degree列。
解答:
SELECT sno, cno, degree FROM scores GROUP BY cno HAVING degree=MAX(degree);查询和“李军”同性别的所有同学的sname。
解答:
# 方法一 子查询 SELECT sname FROM students WHERE ssex = ( SELECT ssex FROM students WHERE sname = '李军'); # 方法二 联结表 SELECT s1.Sname FROM students AS s1 INNER JOIN students AS s2 ON s1.ssex=s2.ssex WHERE s2.sname = '李军';★★查询和“李军”同性别并同班的同学sname。
解答:
SELECT sname FROM students AS s1 INNER JOIN students AS s2 ON s1.ssex = s2.ssex AND s1.class = s2.class WHERE s2.sname = '李军';查询所有选修“计算机导论”课程的**“男”**同学的成绩表。
解答:
SELECT sname, degree FROM scores AS s1 INNER JOIN courses AS c ON s1.cno = c.cno INNER JOIN students AS s2 ON s1.sno = s2.sno WHERE c.cname = '计算机导论' AND s2.ssex = '男' ORDER BY degree DESC;
练习二
准备数据
建表语句
CREATE TABLE userinfo (
userId int(11) NOT NULL,
sex varchar(2),
birth date,
PRIMARY KEY (userId)
) ENGINE = InnoDB;
CREATE TABLE orderinfo (
orderId int(11) NOT NULL,
userId int(11) NOT NULL,
isPaid varchar(10),
price float(11, 2),
paidTime timestamp(0) NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP(0),
PRIMARY KEY (orderId)
) ENGINE = InnoDB;导入数据
获取链接:用户消费行为分析数据;提取码:yu63
数据文件
user_info_utf.csvorder_info_utf.csv
通过navicat,选择对应的数据库表,选择导入:
导入类型:CSV File
- 导入从:选择需要导入的数据文件
- 编码:UTF-8(默认)
记录分隔符:CRLF(默认)
- 字段名行:若数据文件不包含数据表的列名,则输入0(默认为第1行);
- 第一个数据行:若文件不包含数据表的列名,则输入1(默认为第2行);
- 日期排序:注意年月日的顺序
确认目标表
确认对应的目标字段
将记录添加到目标表/删除目标表中原数据,用导入的记录代替
开始执行
练习题
统计不同月份的下单人数
SELECT MONTH(paidTime), COUNT(DISTINCT userId) FROM orderinfo WHERE isPaid = '已支付' GROUP BY MONTH(paidTime);统计用户三月份的复购率和回购率(三月份购买的用户,四月份也购买)
# 复购率 SELECT COUNT(cnt) AS 下单用户数, COUNT(IF(cnt > 1, 1, NULL)) AS 复购用户数 FROM (SELECT userId, COUNT(userId) as cnt FROM orderinfo WHERE isPaid = '已支付' AND MONTH(paidTime) = 3 GROUP BY userId) AS t; # 3月份的回购率 SELECT t1.m, COUNT(t1.m), COUNT(t2.m) FROM (SELECT userId, DATE_FORMAT(paidTime, '%Y-%m-01') AS m FROM orderinfo WHERE isPaid = '已支付' GROUP BY userId, DATE_FORMAT(paidTime, '%Y-%m-01')) AS t1 LEFT JOIN (SELECT userId, DATE_FORMAT(paidTime, '%Y-%m-01') AS m FROM orderinfo WHERE isPaid = '已支付' GROUP BY userId, DATE_FORMAT(paidTime, '%Y-%m-01')) AS t2 ON t1.userId = t2.userId AND t1.m = DATE_ADD(t2.m, INTERVAL -1 MONTH) GROUP BY t1.m;统计男女用户的消费频次(平均数)是否有差异
SELECT sex, AVG(cnt)
FROM (SELECT o.userId, sex, COUNT(*) AS cnt # count(*)的作用为 统计消费次数
FROM orderinfo AS o
INNER JOIN (SELECT *
FROM userinfo
WHERE sex != '') AS t
ON o.userId = t.userId
GROUP BY o.userId, sex) AS t2
GROUP BY sex;统计多次消费的用户,第一次和最后一次消费间隔是多少
SELECT userId, DATEDIFF(MAX(paidTime), MIN(paidTime)) FROM orderinfo WHERE isPaid = '已支付' GROUP BY userId HAVING COUNT(*) > 1;统计不同年龄段,用户的消费金额是否有差异?
SELECT ageGroup, AVG(cnt) FROM (SELECT o.userId, ageGroup, count(o.userId) AS cnt FROM orderinfo AS o INNER JOIN (SELECT userId, CEIL((YEAR(NOW()) - YEAR(birth)) / 10) AS ageGroup FROM userinfo WHERE birth > '1901-00-00') AS t ON o.userId = t.userId WHERE isPaid = '已支付' GROUP BY o.userId, ageGroup) AS t2 GROUP BY ageGroup;统计消费的二八法则,消费的top20%用户,贡献了多少额度
SELECT COUNT(userId), SUM(total) FROM (SELECT userId, SUM(price) AS total FROM orderinfo AS o WHERE isPaid = '已支付' GROUP BY userId ORDER BY total DESC LIMIT 17000) AS t;
练习三
准备数据
CREATE TABLE datafrog_test1
(userid VARCHAR(20),
changjing VARCHAR(20),
int_time VARCHAR(20)
);
INSERT INTO datafrog_test1
VALUES (1,1001,1400),
(2,1002,1401),
(1,1002,1402),
(1,1001,1402),
(2,1003,1403),
(2,1004,1404),
(3,1003,1400),
(4,1004,1402),
(4,1003,1403),
(4,1001,1403),
(4,1002,1404),
(5,1002,1402),
(5,1002,1403),
(5,1001,1404),
(5,1003,1405);问题
求用户id对应的前两个不同场景。(场景重复的话,选场景的第一个访问时间,场景不足两个也输出其场景)
解答
Leetcode 上的SQL题
LIMIT/OFFSETIFNULL()/ISNULL()函数CREATE FUNCTIONLIMIT/OFFSET之后不能包含运算表达式
-
- 窗口函数——
DENSE_RANK():有并列名次的行,不占用下一名次的位置
- 窗口函数——
-
- 窗口函数——
DENSE_RANK() - MySQL如果要 将保留字转义 用作列名,可以在关键字之前和之后使用撇号。例如**`Rank`**
- 窗口函数——
-
SELECT DISTINCT Num AS ConsecutiveNums FROM (SELECT Num, COUNT(*) AS num_cnt FROM (SELECT id, num, (ROW_NUMBER() OVER (ORDER BY id) - ROW_NUMBER() OVER (PARTITION BY num ORDER BY id)) AS orde FROM logs) AS W GROUP BY num, orde) AS S WHERE num_cnt >= 3; -
- 空值的筛选为
IS NULL/IS NOT NULL,不是= NULL
- 空值的筛选为
-
- 每个组内比较,使用子查询
-
- 子查询
- EXISTS 和 IN的运用(EXISTS 更高效)
-
- 时间处理函数
DATE_ADD()
- 时间处理函数
-
BETWEEN ... AND ...- IF表达式
- ROUND函数舍入小数
COUNT函数/AVG函数
-
- UNION和OR的选择
-
CASE... WHEN
牛客网上的SQL题
不让使用ORDER BY排序时,利用子查询和
MAX()-
- 嵌套查询
-
- 窗口函数
- 排序细节
-
- 使用INNER JOIN而不是LEFT JOIN
- 一个部门里可能有多个manager,所以用
NOT IN比用!=更合理
⭐获取员工其当前的薪水比其manager当前薪水还高的相关信息
- 创建两张表(一张记录当前所有员工的工资,另一张只记录部门经理的工资)进行比较
-
- 题意模糊:应该为给出薪水与去年相比丈夫超过5000的员工编号
- 使用INNER JOIN而不是LEFT JOIN
- 时间线的判断方法很有参考价值
查找描述信息中包含robot的电影对应的分类名称以及电影数目,而且还需要该分类对应电影数量>=5部
- 筛选方法
-
- 创建表的时候,有些地方必须加括号
-
- MySQL插入数据,如果数据已存在则忽略的语句是
INSERT IGNORE table_name VALUES(...);
- MySQL插入数据,如果数据已存在则忽略的语句是
对first_name创建唯一索引uniq_idx_firstname
- 创建索引
-
- 创建视图
针对上面的salaries表emp_no字段创建索引idx_emp_no
- 强制索引(MySQL 为 FORCE INDEX)
-
- 此触发器必须按照AFTER INSERT执行,因为在BEFORE INSERT语句执行之前,新的行数据还没有生成。
- 通常,将BEFORE用于数据验证和净化
- 此触发器必须按照AFTER INSERT执行,因为在BEFORE INSERT语句执行之前,新的行数据还没有生成。
-
DELETE FROM table_name WHERE xxx- [将所有to_date为9999-01-01的全部更新为NULL](https://www.nowcoder.com/practice/859f28f43496404886a77600ea68ef59?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - ```sql UPDATE table_name SET xxx WHERE xxx;
将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005
REPLACE(s, s1, s2)函数
-
- 修改表名的两种方式
RENAME TABLE table_name1 TO table_name2;ALTER TABLE table_name1 RENAME TO table_name2;
- 修改表名的两种方式
在audit表上创建外键约束,其emp_no对应employees_test表的主键id
ALTER TABLE table_name ADD [CONSTRAINT fk_name] -- CONSTRAINT fk_name 定义外键名,可不定义 FOREIGN KEY (xx) REFERENCES another_table (xx);- [将所有获取奖金的员工当前的薪水增加10%](https://www.nowcoder.com/practice/d3b058dcc94147e09352eb76f93b3274?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - MySQL不支持`*=`这样的简化字符使用 - [使用含有关键字exists查找未分配具体部门的员工的所有信息](https://www.nowcoder.com/practice/c39cbfbd111a4d92b221acec1c7c1484?tpId=82&tags=&title=&diffculty=0&judgeStatus=&rp=1) - EXISTS和IN的选择 - EXISTS的用法 - [获取有奖金的员工相关信息](https://www.nowcoder.com/practice/5cdbf1dcbe8d4c689020b6b2743820bf?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - CASE语句 - [统计salary的累计和running_total](https://www.nowcoder.com/practice/58824cd644ea47d7b2b670c506a159a6?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - 窗口函数 - [对于employees表中,给出奇数行的first_name](https://www.nowcoder.com/practice/e3cf1171f6cc426bac85fd4ffa786594?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - 窗口函数 - [刷题通过的题目排名](https://www.nowcoder.com/practice/cd2e10a588dc4c1db0407d0bf63394f3?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - 窗口函数 - 排序 - [异常的邮件概率](https://www.nowcoder.com/practice/d6dd656483b545159d3aa89b4c26004e?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - COUNT函数非NULL的都会计数 - [牛客每个人最近的登录日期(三)](https://www.nowcoder.com/practice/16d41af206cd4066a06a3a0aa585ad3d?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - 在执行乘法`*`前,**注意括号的使用** - `WHERE XX IN XXX`**可以用于对一个组合的查询** - ⭐[牛客每个人最近的登录日期(四)](https://www.nowcoder.com/practice/e524dc7450234395aa21c75303a42b0a?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - 解法一:LEFT JOIN + IFNULL函数 - 笛卡尔积**如果WHERE不满足,整个所生成的元组就不会显示**,**如果要显示的话,就必须使用JOIN连接** - 解法二:窗口函数 + SUM函数 - ⭐⭐[牛客每个人最近的登录日期(五)](https://www.nowcoder.com/practice/ea0c56cd700344b590182aad03cc61b8?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) - ⭐[牛客每个人最近的登录日期(六)](https://www.nowcoder.com/practice/572a027e52804c058e1f8b0c5e8a65b4?tpId=82&tags=&title=&diffculty=0&judgeStatus=0&rp=1) --- ## 最近登陆时间,增量更新: table_1是一个按天分区的 用户日志表,每次一个用户登陆都会新加一行: day timestamp uid 2018-08-01 2018-08-01 11:00:00 1 2018-08-01 2018-08-01 14:00:00 1 需要根据table_1新建一个table_2: Day uid latest_login_time 2018-08-01 1 2018-08-01 14:00:00 每天新增一个昨日的分区的全量用户表,其中latest_login_time是自用户登录起最近一次登录的时间 ```sql CREATE TABLE tabel2 ( day DATE NOT NULL, uid INT NOT NULL, `latest login time` TIMESTAMP ); INSERT INTO table2(day, uid, `latest login time`) SELECT day, uid, MAX(`timestamp`) FROM table_1 WHERE DATEDIFF(CURDATE(), day) = 1 -- 昨天 GROUP BY uid;
累计用户数计算
table a是一个用户注册时间的记录表,一个用户只有一条数据,a表如下:
create_time uid
2018-08-01 14:07:09 111
2018-08-02 14:07:09 134
需要计算8月份累计注册用户数(从8月1日开始累计计算,8月1日为8月1日注册用户数,8月2日为8月1日-2日两天的注册用户数),计算结果格式如下:
时间 累计用户数
2018-08-01 2000000
2018-08-02 2100000
…………….
2018-08-31 10000000
SELECT DATE(create_time) AS 时间,
COUNT(uid) OVER (ORDER BY creat_time) AS 累计用户数
FROM `table a`
WHERE YEAR(create_time) = 2018 AND MONTH(create_time) = 8;连续访问天数
table a 是一个用户登陆时间记录表,每登陆一次会记录一条记录,a表如下:
log_time uid
2018-07-01 12:00:00 123
2018-07-01 13:00:00 123
2018-07-02 14:08:09 456
需要计算出7月1日登陆的用户,在后续连续登陆7天,14天,30天的人数
计算结果格式如下:
7月1日登陆总用户数 连续登陆7天用户数 连续登陆14天用户数 。。。。
1000 500 200
SELECT COUNT(table_a.uid) AS '7月1日登录总用户数', COUNT(table_b.uid) AS '连续登录7天的用户数', COUNT(table_c.uid) AS '连续登录14天的用户数'
FROM (SELECT DISTINCT uid
FROM consecutive_task
WHERE DATE(login_time) = '2018-07-01') table_a
LEFT JOIN (SELECT uid, (login_date - rank_num) AS rnk
FROM (SELECT uid, login_date, (ROW_NUMBER() OVER (PARTITION BY uid
ORDER BY login_date)) AS rank_num
FROM (SELECT uid, DATE(login_time) AS login_date
FROM consecutive_task
WHERE DATE(login_time) BETWEEN '2018-07-01' AND '2018-07-07'
GROUP BY uid, login_date) b1 ) b2
GROUP BY uid, rnk
HAVING COUNT(rnk) = 7) table_b
ON table_a.uid = table_b.uid
LEFT JOIN (SELECT uid, (login_date - rank_num) AS rnk
FROM (SELECT uid, login_date, (ROW_NUMBER() OVER (PARTITION BY uid
ORDER BY login_date)) AS rank_num
FROM (SELECT uid, DATE(login_time) AS login_date
FROM consecutive_task
WHERE DATE(login_time) BETWEEN '2018-07-01' AND '2020-07-14'
GROUP BY uid, login_date) c1 ) c2
GROUP BY uid, rnk
HAVING COUNT(rnk) = 14) table_c
ON table_a.uid = table_c.uid;新增用户的近7日留存率
table1:用户新增表,一个设备首次激活都新加一行:
timestamp,device 【新增的日期,新增的设备】
table2: 是一个按天分区的用户活跃表,每次一个用户登陆都会新加一行:
day,device 【活跃的日期,活跃的设备】
需要计算用户新增用户的留存数,留存率【1-7日】
计算结果格式如下:
新增日期 新增设备数 次日留存数 次日留存率 2日留存数 2日留存率 ….
timestamp 1000 500 50% 450 45%
SELECT a.first AS 新增日期, COUNT(DISTINCT a.device) AS 新增设备数,
COUNT(DISTINCT IF(first - b.day = 1, a.device, NULL)) AS 次日留存数,
CONCAT(ROUND(COUNT(DISTINCT IF(first - b.day = 1, a.device, NULL)) / COUNT(DISTINCT a.device) * 100, 0), '%') AS 次日留存率
FROM (SELECT a.device, DATE(a.timestamp) AS first, b.day
FROM table1 a LEFT JOIN table2 b
ON a.device = b.device) c
GROUP BY a.first; -- 按 新增用户的日期 分组计算日活用户签到,开宝箱,阅读行为的用户各自占比
table1: 是一个按天分区的用户活跃表,每次一个用户登陆都会新加一行:
day,uid 【活跃的日期,活跃的用户id】
table2:是一个按天分区的用户行为表,每一种行为都会新加一行:
day ,uid,type 【日期,用户id,type类型:1表示签到,2表示开宝箱,3表示阅读】
需要计算,签到占日活的比例,开宝箱占日活的比例,阅读占日活的比例
计算结果格式如下:
日期 活跃用户数 签到占日活的比例 开宝箱占日活的比例 阅读占日活的比例
SELECT day AS 日期, COUNT(DISTINCT uid) AS 活跃用户数,
COUNT(IF(type = 1, 1, NULL)) / COUNT(uid) AS 签到占日活的比例,
COUNT(IF(type = 2, 1, NULL)) / COUNT(uid) AS 开宝箱占日活的比例,
COUNT(IF(type = 3, 1, NULL)) / COUNT(uid) AS 阅读占日活的比例
FROM (SELECT a.*, b.type
FROM table_1 AS a LEFT JOIN table_2 AS b
ON a.uid = b.uid AND a.day = b.day) c
GROUP BY day;练习四
准备数据
CREATE TABLE Employee
(
id INT(20),
name VARCHAR(20),
salary INT(20),
departmentid INT(20)
);
INSERT INTO Employee
VALUES (1,"Joe",70000,1),
(2,"Henry",80000,2),
(3,"Sam",60000,2),
(4,"Max",90000,1);
CREATE TABLE Department
(
id INT(20),
name VARCHAR(20)
);
INSERT INTO Department
VALUES (1,"IT"),
(2,"Sales");练习题
找出每个部门工资最高的员工
SELECT d.name Department, e.name Employee, MAX(Salary) Salary
FROM Employee e LEFT JOIN Department d
ON e.departmentid = d.id
GROUP BY d.id;准备数据
CREATE TABLE customer
(
Id INT(10),
Email VARCHAR(20)
);
INSERT INTO customer
VALUES (1,'a@b.com'),
(2,'c@d.com'),
(3,'a@b.com');练习题
查找 customer 表中所有重复的电子邮箱
SELECT Email
FROM customer
GROUP BY Email
HAVING COUNT(Email)>1;准备数据
CREATE TABLE Customers
(
Id INT(10),
Name VARCHAR(20)
);
INSERT INTO Customers
VALUES (1,'Joe'),
(2,'Henry'),
(3,'Sam'),
(4,'Max');
CREATE TABLE Orders
(
Id INT(10),
CustomerId INT(10)
);
INSERT INTO Orders
VALUES (1,3),
(2,1);练习题:找出所有从不订购任何东西的客户
-- 方法一
SELECT name AS customers
FROM customers c LEFT JOIN orders o
ON c.id = o.customerId
WHERE o.id IS NULL;
-- 方法二
SELECT name AS customers
FROM customers
WHERE id NOT IN (SELECT customerid
FROM orders);准备数据
CREATE TABLE Scores
(
id VARCHAR(20),
score FLOAT(4,2)
);
INSERT INTO scores
VALUES (1,3.5),
(2,3.65),
(3,4.00),
(4,3.85),
(5,4.00),
(6,3.65);练习题:通过查询实现分数排名
-- 窗口函数 ROW_NUMBER()
SELECT score, ROW_NUMBER() OVER (ORDER BY score DESC) AS `Rank`
FROM scores
ORDER BY score DESC;
-- ROW_NUMBER() 对应 使用变量 的做法
SELECT score, @curRank=@curRank+1 AS `Rank`
FROM scores, (SELECT @RANK:=0) r
ORDER BY score DESC;
-- RANK() (有并列名次的行,会占用下一名次的位置)对应使用变量的做法
SELECT score, `rank`
FROM (SELECT score, @curRank = IF(@preScore = score, @curRank, @incRank) AS `rank`, -- 同分同排名,不同分下一排名
@incRank:=@incRank+1; -- 作用等同于 ROW_NUMBER()
@preScore:=score
FROM scores, (SELECT @curRank:=0, @preScore:=NULL, @incRank:=1) r
ORDER BY score DESC) s;
-- DENSE_RANK() 对应使用变量的做法
SELECT score, `rank`
FROM (SELECT score, @curRank=IF(@preScore=score, @curRank, @curRank+1) AS `rank`,
@preScore=score
FROM scores, (SELECT @curRank:=0, @preScore:=NULL) r
ORDER BY socre DESC) s;
-- 使用CASE WHEN更简洁
SELECT score, CASE
WHEN score=@preScore THEN @curRank
WHEN @preScore:=score THEN @curRank:=@curRank+1 -- @preScore:=score 赋值语句必为true
END AS `rank`
FROM scores, (SELECT @curRank:=0, @preScore:=NULL) r
ORDER BY score DESC;准备数据
CREATE TABLE seat
(
id INT(20),
student VARCHAR(20)
);
INSERT INTO seat
VALUES (1,'Abbot'),
(2,'Doris'),
(3,'Emerson'),
(4,'Green'),
(5,'Jeames');练习题:座位id 是连续递增的,改变相邻俩学生的座位。
要求:
- 如果学生人数是奇数,则不需要改变最后一个同学的座位。
SELECT (CASE
WHEN id % 2 = 1 AND id != cnt THEN id+1 -- 奇数且不是最后一个
WHEN id % 2 = 1 AND id = cnt THEN id
ELSE id - 1 -- 偶数
END) AS id, student
FROM seat, (SELECT COUNT(*) AS cnt -- 用于判断当前是否是最后一个学生(奇数的特殊判断)
FROM seat) t
ORDER BY id;准备数据
DROP TABLE IF EXISTS Employee;
CREATE TABLE Employee
(
Id INT(10),
Name VARCHAR(20),
Salary INT(20),
ManagerId INT(10)
);
INSERT INTO Employee
VALUES (1, 'Joe', 70000, 3),
(2, 'Henry', 80000, 4),
(3, 'Sam', 60000, NULL),
(4, 'Max', 90000, NULL);练习题:编写一个 SQL 查询,获取收入超过他们经理的员工的姓名。
SELECT e1.Name
FROM Employee e1 LEFT JOIN Employee e2
ON e1.ManagerId = e2.Id
WHERE e1.Salary > e2.Salary;练习五
题目:X 市建了一个新的体育馆,每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people)。
请编写一个查询语句,找出人流量的高峰期。
要求:
- 高峰期时,至少连续三行记录中的人流量不少于100
- 每天只有一行记录,日期随着 id 的增加而增加
CREATE TABLE stadium
(
id INT(20),
visit_date DATE,
people INT(20)
);
INSERT INTO stadium
VALUES (1,'2017-01-01',10),
(2,'2017-01-02',109),
(3,'2017-01-03',150),
(4,'2017-01-04',99),
(5,'2017-01-05',145),
(6,'2017-01-06',1455),
(7,'2017-01-07',199),
(8,'2017-01-08',188);-- 方法一:朴实的自联结
SELECT DISTINCT t1.*
FROM stadium t1, stadium t2, stadium t3
WHERE (t1.people >= 100 -- 筛选表中 人流量>=100 的行
AND t2.people >= 100
AND t3.people >= 100
AND ( (t1.id - t2.id = 1 -- 错位联结,从t1的id开始连续3天有人流高峰
AND t1.id - t3.id = 2
AND t2.id - t3.id = 1
)
OR (t2.id - t1.id = 1 -- 补充 t1之后只有1天人流高峰,但之前也有连续高峰 的情况
AND t2.id - t3.id = 2
AND t1.id - t3.id = 1)
OR (t3.id - t2.id = 1 -- 补充t1为人流高峰最后一天 的情况
AND t2.id - t1.id = 1
AND t3.id - t1.id = 2)
)
)
ORDER BY t1.id;
-- 方法二:MySQL 8.0 之后开始支持 WITH AS 语句(子查询部分,作用类似于一个视图,但with as 属于一次性的,而且必须和其他sql一起使用才行) WITH子句的查询必须用括号括起来
WITH t1 AS
(SELECT id, visit_date, people,
(id - ROW_NUMBER() OVER (ORDER BY id)) rk
FROM stadium
WHERE people >= 100)
SELECT id, visit_date, people
FROM t1
WHERE rk IN (SELECT rk
FROM t1
GROUP BY rk
HAVING COUNT(*) >= 3); 挑战题
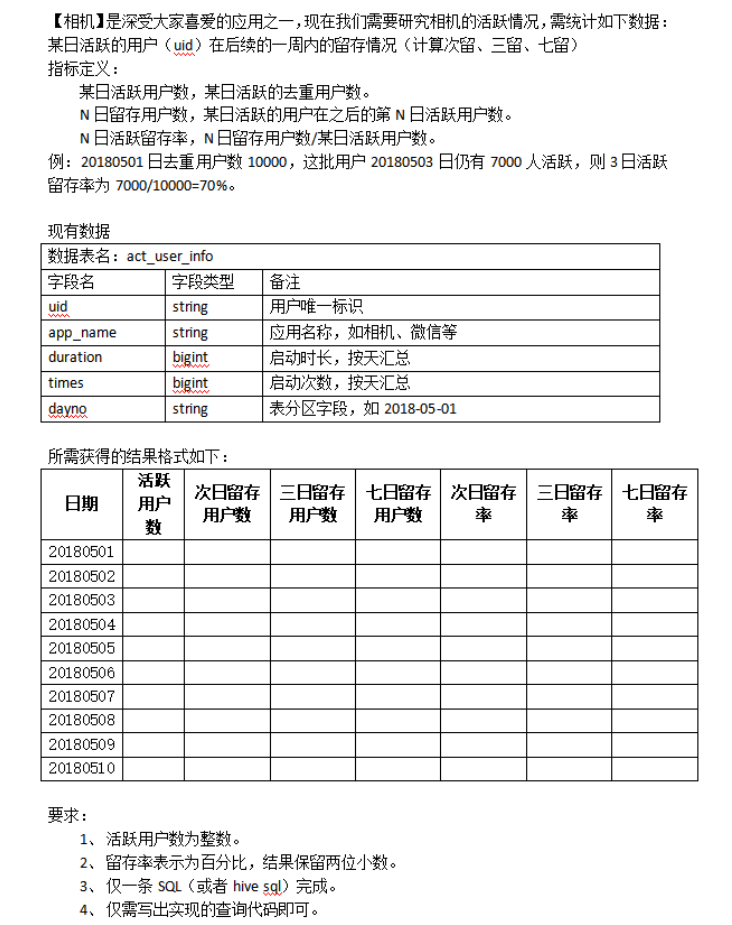
SELECT 日期, COUNT(DISTINCT a.uid) 活跃用户数, COUNT(DISTINCT IF(day-first=1, a.uid, NULL)) 次日留存用户数,
COUNT(DISTINCT IF(day-first=3), a.uid, NULL) 三日留存用户数,
COUNT(DISTINCT IF(day-first=7), a.uid, NULL) 七日留存用户数,
CONCAT(ROUND(COUNT(DISTINCT IF(day-first=1, a.uid, NULL)) / COUNT(DISTINCT a.uid), 2), '%') 次日留存率, CONCAT(ROUND(COUNT(DISTINCT IF(day-first=3, a.uid, NULL)) / COUNT(DISTINCT a.uid), 2), '%') 三日留存率, CONCAT(ROUND(COUNT(DISTINCT IF(day-first=7, a.uid, NULL)) / COUNT(DISTINCT a.uid), 2), '%') 七日留存率
FROM (SELECT uid, DATE_FORMAT(dayno, '%Y-%m-%d') AS first
FROM act_user_info
WHERE app_name = '相机') a LEFT JOIN (SELECT uid, DATE_FORMAT(dayno, '%Y-%m-%d') AS day
FROM act_user_info
WHERE app_name = '相机') b
ON a.uid = b.uid
GROUP BY first;PDD笔试题
2. 用户行为分析
表1——用户行为表tracking_log,大概字段有(user_id‘用户编号’,opr_id‘操作编号’,log_time‘操作时间’)
- 统计每天符合以下条件的用户数:A操作之后是B操作,AB操作必须相连
-- 使用窗口函数
SELECT DATE(log_time), COUNT(DISTINCT user_id)
FROM (SELECT DATE(log_time), user_id, opr_id,
LEAD(opr_id, 1) OVER() AS pre_opr
FROM tracking_log) table_1
WHERE opr_id='A' AND pre_opr='B'
GROUP BY DATE(log_time);
-- 使用用户变量
SELECT DATE(log_time), COUNT(DISTINCT user_id)
FROM (SELECT DATE(log_time), user_id,
(CASE
WHEN @pre_opr='A' AND opr_id='B' THEN @isJoin:=True AND @pre_opr:=opr_id
ELSE @pre_opr:=opr_id
END) isJoin
FROM tracking_log, (SELECT @pre_opr:=NULL, @isJoin:=FALSE) a) table_1
WHERE isJoin=True
GROUP BY DATE(log_time);3. 用户新增留存分析
表1——用户登陆表user_log,大概字段有(user_id‘用户编号’,log_time‘登陆时间’)
- 获取每日新增用户数,以及第2天、第30天的回访比例
SELECT COUNT(user_id) 新增用户数,
(COUNT(DISTINCT IF(DATEDIFF(DATE(log_time), 注册日期)=1, u1.user_id, NULL)) / COUNT(user_id)) AS 第2天回访比例,
(COUNT(DISTINCT IF(DATEDIFF(DATE(log_time), 注册日期)=29, u1.user_id, NULL)) / COUNT(user_id)) AS 第30天回访比例
FROM (SELECT user_id, DATE(MIN(log_time)) AS 注册日期
FROM user_log
GROUP BY user_id) u1 LEFT JOIN user_log u2
ON u1.user_id = u2.user_id
GROUP BY 注册日期;4. 贝叶斯公式的应用
SELECT Partition_date,
(CASE
WHEN DATEDIFF(t2.Partition_date, t1.Partition_date)=1 THEN COUNT(DISTINCT t1.user_id)
END) AS '流失1天',
(CASE
WHEN DATEDIFF(t2.Partition_date, t1.Partition_date)=2 THEN COUNT(DISTINCT t1.user_id)
END) AS '流失2天',
(CASE
WHEN DATEDIFF(t2.Partition_date, t1.Partition_date)=3 THEN COUNT(DISTINCT t1.user_id)
END) AS '流失3天',
(CASE
WHEN DATEDIFF(t2.Partition_date, t1.Partition_date)>=30 THEN COUNT(DISTINCT t1.user_id)
END) AS '流失30天以上'
FROM (SELECT user_id, Partition_date
FROM user_active
WHERE daily_active_status_map=1) t1 LEFT JOIN (SELECT user_id, Partition_date
FROM usre_active
WHERE daily_active_status_map=1) t2
ON t1.user_id=t2.user_id
WHERE t2.user_id IS NULL
GROUP BY Partition_date
ORDER BY Partition_date DESC;