Redis
什么是Redis
Redis是基于C语言开发的NoSQL数据库,它是一种存储KV键值对数据的内存数据库,因此读写速度非常快,被广泛应用于分布式缓存方向。
Redis内置了多种数据类型实现:
- 5种基础数据类型
- String
- List
- Set
- Hash
- Zset (有序集合)
- 3种特殊数据类型
- HyperLogLog(基数统计)
- Bitmap(位图)
- Geospatial (地理位置)
Reids还支持事务、持久化(将内存数据保存在磁盘中,重启时可以再次加载使用)、Lua脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
基本操作
Redis是一个键值数据库,因此,可以像Map一样的操作方式,通过键值对向Redis数据库中添加数据(操作起来类似于向一个HashMap中存放数据)。
在Redis下,数据库是由一个整数索引标识,而不是由一个数据库名称。 默认情况下,我们连接Redis数据库之后,会使用0号数据库,我们可以通过Redis配置文件中的参数来修改数据库总数,默认为16个。可以通过select语句进行切换:
select 序号;- 向redis数据库中添加数据
set <key> <value>
-- 批量添加
mset [<key> <value>] ...所有存入的数据,默认以字符串的形式保存。键值具有一定的命名规范,以方便快速定位数据属于哪一个部分,比如用户数据:
-- 使用冒号进行板块分割,如下表示 设置某用户ID的name属性的值
set user:info:某用户ID:name hunter- 通过键值获取存入的值
get <key>- redis在存值时,支持设置数据的过期时间:
set <key> <value> EX 秒
set <key> <value> PX 毫秒也可以单独为其他的键值对设置过期时间:
expire <key> 秒通过如下命令查询还有多少时间过期:
-- 秒级 显示
ttl <key>
-- 毫秒级 显示
pttl <key>
-- 设置为不过期
persist <key>- 删除数据
-- 可批量删除
del [<key>] ...- 查看键值
-- 查看所有键值
keys *
-- 查询键是否存在
exists <key>
-- 随机拿一个键
randomkey- 移动数据
move <key> 数据库号- 修改键名
rename <key> <new key name>
-- 会检查新的名称是否已经存在
renamex <key> <new key name>- 如果存放的是数字,可以进行自增自减操作
-- 等价于a = a + 1
incr <key>
-- 等价于a = a + b
incrby <key> b
-- 等价于a = a - 1
decr <key>- 查看值的数据类型
type <key>数据结构与对象
简单动态字符串 (SDS, Simple Dynamic String)
struct sdshdr {
// 记录buf数组中已使用字节的数量
// 等于SDS所保存字符串的长度
int len;
// 记录buf数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};SDS遵循C字符串以空字符结尾的惯例,保存空字符的1字节空间不计算在SDS的len属性里面,并且为空字符分配额外的1字节空间,以及添加空字符到字符串末尾等操作,都是由SDS函数自动完成的,所以这个空字符对于SDS的使用者来说是完全透明的。遵循空字符结尾这一惯例的好处是,SDS可以直接重用一部分C字符串函数库里面的函数。
常数复杂度获取字符串长度
通过使用SDS而不是C字符串,Redis将获取字符串长度所需的复杂度从$O(N)$降低到了$O(1)$,这确保了获取字符串长度的工作不会成为Redis的性能瓶颈。
杜绝缓冲区溢出
SDS的空间分配策略杜绝了发生缓冲区溢出的可能性。当SDS API需要对SDS进行修改时,API会先检查SDS的空间是否满足修改所需的要求,如果不满足的话,API会自动将SDS的空间扩展至执行修改所需的大小,然后才执行实际的修改操作。
减少修改字符串时带来的内存重分配次数
空间预分配
- 如果对SDS进行修改之后,SDS的长度(也即是len属性的值)小于1MB,那么程序分配和len属性同样大小的未使用空间,这时SDS len属性的值将和free属性的值相同。
- 如果对SDS进行修改之后,SDS的长度将大于等于1MB,那么程序会分配1MB的未使用空间。
惰性空间释放
当SDS的API需要缩短SDS保存的字符串时,程序不立即回收缩短后多出来的字节,而是使用free属性将这些字节的数量记录起来,并等待将来使用。与此同时,SDS也提供了相应的API真正地释放SDS的未使用空间,所以不用担心惰性空间释放策略会造成内存浪费。
二进制安全
虽然数据库一般用于保存文本数据,但使用数据库来保存二进制数据的场景也不少见,因此,为了确保Redis可以适用于各种不同的使用场景,所有SDS API都会以处理二进制的方式来处理SDS存放在buf数组里的数据,程序不会对其中的数据做任何限制、过滤、或者假设,数据在写入时是什么样的,它被读取时就是什么样。这也是我们将SDS的buf属性称为字节数组的原因——Redis不是用这个数组来保存字符,而是用它来保存一系列二进制数据。
使用SDS来保存之前提到的特殊数据格式就没有任何问题,因为SDS使用len属性的值而不是空字符来判断字符串是否结束。但SDS一样遵循C字符串以空字符结尾的惯例,这是为了让那些保存文本数据的SDS可以重用一部分<string.h>库定义的函数。
链表
链表在Redis中的应用非常广泛,比如列表键的底层实现之一就是链表。当一个列表键包含了数量比较多的元素,又或者列表中包含的元素都是比较长的字符串时,Redis就会使用链表作为列表键的底层实现。
除了列表键之外,发布与订阅、慢查询、监视器等功能也用到了链表,Redis服务器本身还使用链表来保存多个客户端的状态信息,以及使用链表来构建客户端输出缓冲区(output buffer)。
每个链表节点使用adlist.h/listNode结构来表示:
typedef struct listNode {
// 前置节点
struct listNode * prev;
// 后置节点
struct listNode * next;
// 节点的值
void * value;
}listNode;虽然仅仅使用多个listNode结构就可以组成链表,但使用adlist.h/list来持有链表的话,操作起来会更方便:
typedef struct list {
// 表头节点
listNode * head;
// 表尾节点
listNode * tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr,void *key);
} list;list结构为链表提供了表头指针head、表尾指针tail,以及链表长度计数器len,而dup、free和match成员则是用于实现多态链表所需的类型特定函数:
- dup函数用于复制链表节点所保存的值;
- free函数用于释放链表节点所保存的值;
- match函数则用于对比链表节点所保存的值和另一个输入值是否相等。
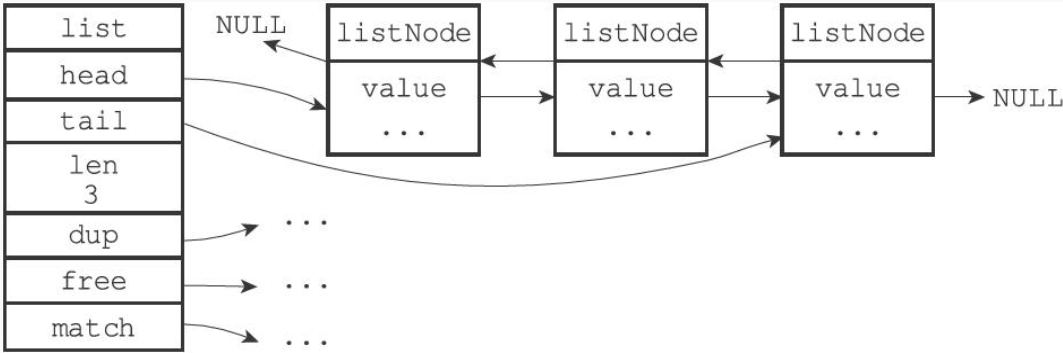
Redis的链表实现的特性可以总结如下:
- 双端:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都是O(1)。
- 无环:表头节点的prev指针和表尾节点的next指针都指向NULL,对链表的访问以NULL为终点。
- 带表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点和表尾节点的复杂度为O(1)。
- 带链表长度计数器:程序使用list结构的len属性来对list持有的链表节点进行计数,程序获取链表中节点数量的复杂度为O(1)。
- 多态:链表节点使用
void*指针来保存节点值,并且可以通过list结构的dup、free、match三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。
字典
字典是用于保存键值对的抽象数据结构。字典在Redis中的应用相当广泛,比如对数据库的增、删、查、改操作构建在对字典的操作之上。
除了用来表示数据库之外,字典还是哈希键的底层实现之一,当一个哈希键包含的键值对比较多,又或者键值对中的元素都 是比较长的字符串时,Redis就会使用字典作为哈希键的底层实现。
Redis的字典使用哈希表作为底层实现,每个哈希表节点保存了字典中的一个键值对。
哈希表
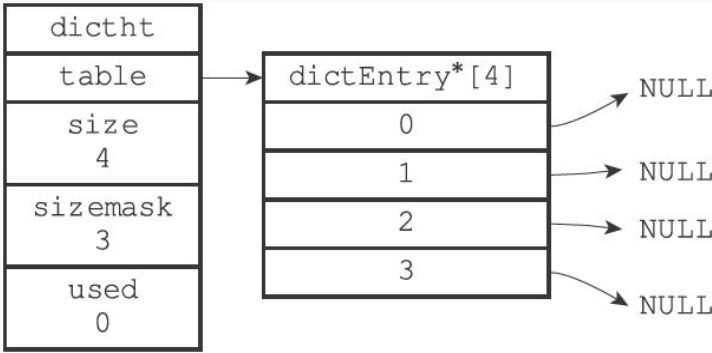
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于size-1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;- table属性是一个数组,数组中的每个元素都是一个指向
dict.h/dictEntry结构的指针,每个dictEntry结构保存着一个键值对。 - sizemask和哈希值一起决定一个键应该被放到table数组的哪个索引上面。
一个空的哈希表:
哈希表节点
typedef struct dictEntry {
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
} v;
//指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;next属性是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一起,以此来解决键冲突(collision)的问题。
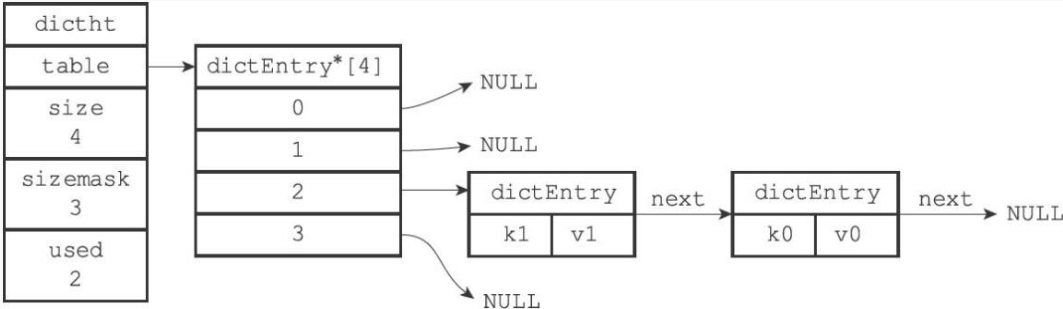
字典的结构
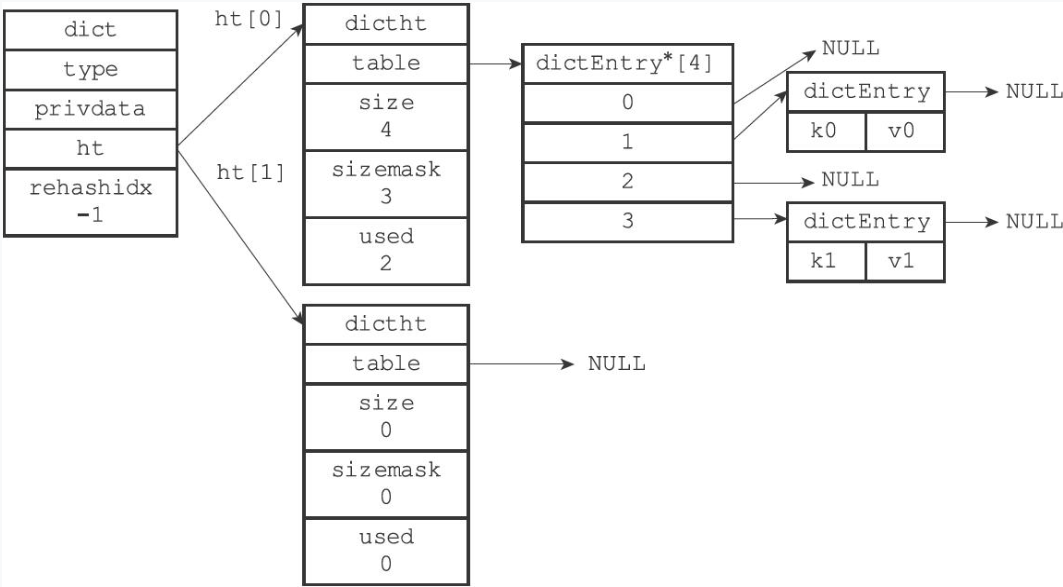
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash索引
// 当rehash不在进行时,值为-1
in trehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;- type属性是一个指向dictType结构的指针,每个dictType结构保存了一簇用于操作特定类型键值对的函数,Redis会为用途不同的字典设置不同的类型特定函数。
- privdata属性则保存了需要传给那些类型特定函数的可选参数。
- ht属性是一个包含两个项的数组,数组中的每个项都是一个
dictht哈希表,一般情况下,字典只使用ht[0]哈希表,ht[1]哈希表只会在对ht[0]哈希表进行rehash时使用。
普通状态下,没有进行rehash的字典:
当字典被用作数据库的底层实现,或者哈希键的底层实现时,Redis使用MurmurHash2算法来计算键的哈希值。这种算法的优点在于,即使输入的键是有规律的,算法仍能给出一个很好的随机分布性,并且算法的计算速度也非常快。
解决键冲突
Redis的哈希表使用**链地址法(separate chaining)**来解决键冲突,每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来,这就解决了键冲突的问题。
因为dictEntry节点组成的链表没有指向链表表尾的指针,所以为了速度考虑,程序总是将新节点添加到链表的表头位置(复杂度为$O(1)$)。
rehash
随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(load factor)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。这个工作通过执行rehash操作来完成。
- 为字典的ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及ht[0]当前包含的键值对数量(也即是ht[0].used属性的值)
- 扩展操作,那么ht[1]的大小为第一个≥
ht[0].used*2的$2^n$; - 收缩操作,那么ht[1]的大小为第一个≥
ht[0].used的$2^n$。 - 将保存在ht[0]中的所有键值对rehash到ht[1]上面,即重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
- 当ht[0]包含的所有键值对都迁移到了ht[1]之后(ht[0]变为空表),释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备。
为了避免rehash对服务器性能造成影响,rehash动作不是一次性、集中式地完成,而是分多次、渐进式地完成的。因为在进行渐进式rehash的过程中,字典会同时使用ht[0]和ht[1]两个哈希表,所以在渐进式rehash进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行。例如,要在字典里面查找一个键的话,程序会先在ht[0]里面进行查找,如果没找到的话,就会继续到ht[1]里面进行查找,诸如此类。
另外,在渐进式rehash执行期间,新添加到字典的键值对一律会被保存到ht[1]里面,而ht[0]则不再进行任何添加操作,这一措施保证了ht[0]包含的键值对数量会只减不增,并随着rehash操作的执行而最终变成空表。
跳跃表 skiplist
跳表是一种链表+多级索引的有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。 跳表支持平均$O(logN)$、最坏$O(N)$复杂度的节点查找,还可以通过顺序操作来批量处理节点。
和链表、字典等数据结构被广泛地应用在Redis内部不同,Redis只在两个地方用到了跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构。
跳跃表示例:
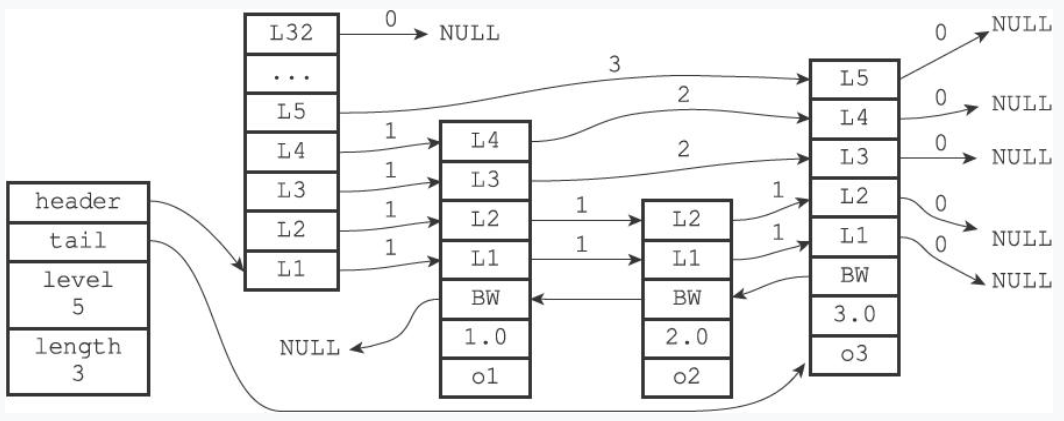
zskiplist结构
- header
- tail
- level:记录目前跳跃表内,层数最大的节点的层数(不包括表头节点)
- length:记录跳跃表的长度(不包括表头节点)
zskiplistNode结构
level:每个层都带有两个属性:前进指针和跨度。
- 前进指针指向位于表尾方向的其他节点。
- 跨度记录了指向节点与当前节点的距离。指向NULL的所有前进指针的跨度都为0,因为它们没有连向任何节点。
当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。
backward指针:指向前一个节点。
score:节点按各自保存的分值从小到大排列。
obj:成员对象。是指向一个字符串对象的指针。
表头节点也有backward指针、score和成员对象,不过表头节点的这些属性都不会被用到,所以图中省略了这些部分,只显示了表头节点的各个层。
跳跃表节点
typedef struct zskiplistNode {
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
} zskiplistNode;层
每次创建一个新跳跃表节点的时候,程序都根据幂次定律(power law,越大的数出现的概率越小)随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的“高度”。
跨度实际用来计算排位。
在查找某个节点的过程中,将沿途访问过的所有层的跨度累计,得到的结果就是目标节点在跳表中的排位。
在同一个跳跃表中,各个节点保存的成员对象必须是唯一的,但是多个节点保存的分值可以相同:分值相同的节点将按照成员对象在字典序中的大小来进行排序,成员对象较小的节点会排在前面(靠近表头的方向),而成员对象较大的节点则会排在后面(靠近表尾的方向)。
整数集合 intset
整数集合是集合键的底层实现之一。当一个集合只包含整数值元素并且元素数量不多时,Redis就会使用整数集合作为集合键的底层实现。它可以保存类型为int16_t、int32_t或者int64_t的整数值,并且保证集合中不会出现重复元素。
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;contents数组是整数集合的底层实现
整数集合的每个元素都是contents数组的一个数组项,按值从小到大排列。
虽然intset结构将contents属性声明为int8_t类型的数组,但实际上contents数组并不保存任何int8_t类型的值,contents数组的真正类型取决于encoding属性的值:
- encoding属性的值为
INTSET_ENC_INT16,那么contents就是一个int16_t类型的数组 - encoding属性的值为
INTSET_ENC_INT32,那么contents就是一个int32_t类型的数组 - encoding属性的值为
INTSET_ENC_INT64,那么contents就是一个int64_t类型的数组
- encoding属性的值为
升级
每当我们要将一个新元素添加到整数集合里面,并且新元素的类型比整数集合现有所有元素的类型都要长时,整数集合需要先进行升级(upgrade),然后才能将新元素添加到整数集合里面。
- 根据新元素的类型,扩展整数集合底层数组的空间大小,并为新元素分配空间。
- 底层数组现有的所有元素都转换成与新元素相同的类型,并将类型转换后的元素放置到正确的位上,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变 。
- 将新元素添加到底层数组里面。
因为每次向整数集合添加新元素都可能会引起升级,而每次升级都需要对底层数组中已有的所有元素进行类型转换,所以向整数集合添加新元素的时间复杂度为$O(N)$。
整数集合的升级策略有两个好处,一个是提升整数集合的灵活性(可以添加新类型),另一个是尽可能地节约内存(只有必要时才会升级)。
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
压缩列表 ziplist
压缩列表(ziplist)是列表键和哈希键的底层实现之一。
- 当一个列表键只包含少量列表项(< 512),并且每个列表项要么就是小整数值,要么就是长度比较短的字符串(< 64字节),Redis就会使用压缩列表来做列表键的底层实现。
- 当一个哈希键只包含少量键值对,并且每个键值对的键和值要么就是小整数值,要么就是长度比较短的字符串,Redis就会使用压缩列表来做哈希键的底层实现。
压缩列表是由一系列特殊编码的连续内存块组成的顺序型数据结构。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。

| 属性 | 类型 | 用途 |
|---|---|---|
| zlbytes | unit32_t | 记录压缩列表占用的内存。 在对压缩列表进行内存重分配,或者计算zlend位置时使用。 |
| zltail | unit32_t | 记录压缩列表表尾节点距离起始地址有多少字节。 程序无需遍历整个压缩列表就可以确定表尾节点的地址。 |
| zllen | unit16_t | 记录了压缩列表包含的节点数量。 该属性值 < UNIT16_MAX 时,就是压缩列表包含节点的数量。 该属性值 = UNIT16_MAX时,节点的数量需要遍历压缩列表才能得出。 |
| entryX | 列表节点 | 节点的长度由节点保存的内容决定。 |
| zlend | unit8_t | 特殊值0xFF,用于标记压缩列表的末端。 |
压缩列表节点的构成
| previous_entry_length | encoding | content |
|---|
previous_entry_length,记录了前一个节点的长度,以字节为单位。
压缩列表可以根据这个属性,从表尾向表头遍历。
encoding,记录了节点的content属性保存的数据类型和长度。
content,保存节点的值,可以是字节数组或整数。
连锁更新
Redis将在特殊情况下产生的连续多次空间扩展操作称之为连锁更新。
因为连锁更新在最坏情况下需要对压缩列表执行N次空间重分配操作,而每次空间重分配的最坏复杂度为$O(N)$,所以连锁更新的最坏复杂度为$O(N^2)$。
尽管连锁更新的复杂度较高,但它真正造成性能问题的几率很低:
- 首先,压缩列表里要恰好有多个连续的、长度介于250字节至253字节之间的节点,连锁更新才有可能被引发,在实际中,这种情况并不多见。
- 其次,即使出现连锁更新,但只要被更新的节点数量不多,就不会对性能造成任何影响:比如说,对三五个节点进行连锁更新是绝对不会影响性能的。
因为以上原因,ziplistPush等命令的平均复杂度仅为$O(N)$,在实际中,我们可以放心地使用这些函数,而不必担心连锁更新会影响压缩列表的性能。
对象
Redis没有直接使用上述的数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统。这个系统包含字符串对象(String)、列表对象(List)、哈希对象(Hash)、集合对象(Set)和有序集合(Zset)对象这五种类型的对象,每种对象都至少用到了一种前面介绍的数据结构。
通过这五种不同类型的对象,Redis可以在执行命令之前,根据对象的类型来判断一个对象是否可以执行给定的命令。另外,可以针对不同的使用场景,为对象设置多种不同的数据结构实现,从而优化对象在不同场景下的使用效率。
除此之外,Redis的对象系统还实现了基于引用计数技术的内存回收机制,当程序不再使用某个对象的时候,这个对象所占用的内存就会被自动释放;另外,Redis还通过引用计数技术实现了对象共享机制,这一机制可以在适当的条件下,通过让多个数据库键共享同一个对象来节约内存。
最后,Redis的对象带有访问时间记录信息,该信息可以用于计算数据库键的空转时长,在服务器启用了maxmemory功能的情况下,空转时长较大的那些键可能会优先被服务器删除。
对象的类型与编码
每次在Redis的数据库中新创建一个键值对时,我们至少会创建两个对象,一个对象用作键值对的键(键对象),另一个对象用作键值对的值(值对象)。
Redis中的每个对象都由一个redisObject结构表示,该结构中和保存数据有关的三个属性分别是type属性、encoding属性和ptr属性:
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;type
类型常量 对象的名称 REDIS_STRING 字符串对象 REDIS_LIST 列表对象 REDIS_HASH 哈希对象 REDIS_SET 集合对象 REDIS_ZSET 有序集合对象 对于Redis数据库保存的键值对来说,键总是一个字符串对象,而值则可以是字符串对象、列表对象、哈希对象、集合对象或者有序集合对象的其中一种。因此,当称呼一个数据库键为“字符串键”时,实际指的是数据库键所对应的值为字符串对象。
查看命令为
TYPE objNameencoding
encoding记录了对象使用了什么数据结构作为对象的底层实现:
编码常量 编码对应的底层数据结构 REDIS_ENCODING_INT long类型的整数 REDIS_ENCODING_EMBSTR embstr编码的简单动态字符串 REDIS_ENCODING_RAW 简单动态字符串 REDIS_ENCODING_HT 字典 REDIS_ENCODING_LINKEDLIST 双端链表 REDIS_ENCODING_ZIPLIST 压缩列表 REDIS_ENCODING_INTSET 整数集合 REDIS_ENCODING_SKIPLIST 跳跃表和字典 每种类型的对象都至少使用了两种不同的编码:
- string
- REDIS_ENCODING_INT
- REDIS_ENCODING_EMBSTR
- REDIS_ENCODING_RAW
- list
- REDIS_ENCODING_ZIPLIST
- REDIS_ENCODING_LINKEDLIST
- hash
- REDIS_ENCODING_ZIPLIST
- REDIS_ENCODING_HT
- set
- REDIS_ENCODING_INTSET
- REDIS_ENCODING_HT
- zset
- REDIS_ENCODING_ZIPLIST
- REDIS_ENCODING_SKIPLIST
查看命令为
OBJECT ENCODING objName- string
字符串对象
字符串对象的编码可以是int、raw或者embstr。
- 如果字符串对象保存的是整数值,并且这个整数值可以用long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void转换成long),并将字符串对象的编码设置为*int。
- 如果字符串对象保存的是字符串值,并且这个字符串值的长度>32字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为raw。
- 如果字符串对象保存的是字符串值,并且这个字符串值的长度≤32字节,那么字符串对象将使用embstr编码的方式来保存这个字符串值。
embstr编码和raw编码一样,都使用redisObject结构和sdshdr结构来表示字符串对象。但raw编码会调用2次内存分配函数来分别创建redisObject结构和sdshdr结构,而embstr编码则通过调用1次内存分配函数来分配一块连续的空间,空间中依次包含redisObject和sdshdr两个结构。

最后要说的是,可以用long double类型表示的浮点数,在Redis中也是作为字符串值来保存的。如果我们要保存一个浮点数到字符串对象里面,那么程序会先将这个浮点数转换成字符串值,然后再保存转换所得的字符串值。在有需要的时候,程序会将字符串值转换回浮点数值,执行某些操作,然后再将所得的浮点数值转换回字符串值,并继续保存在字符串对象里面。
对于int编码的字符串对象来说,如果我们向对象执行了一些命令,使得这个对象保存的不再是整数值,而是一个字符串值,那么字符串对象的编码将从int变为raw。
例如通过
APPEND命令,向保存整数值的字符串对象追加字符串值。为Redis没有为embstr编码的字符串对象编写任何相应的修改程序,所以embstr编码的字符串对象实际上是只读的。当我们对embstr编码的字符串对象执行任何修改命令时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。
字符串对象是Redis五种类型的对象中唯一一种会被其他四种类型对象嵌套的对象。
字符串相关命令
| 命令 | 举例 |
|---|---|
| SET | SET msg “hello world” |
| GET | GET msg |
| APPEND | APPEND msg “ again” |
| INCRBY | SET num 1 INCRBY num |
| DECRBY | DECRBY num |
| STRLEN | STRLEN msg |
列表对象
列表对象的编码可以是ziplist或者linkedlist。列表中存放一系列的字符串,它支持随机访问,支持双端操作,就像我们使用Java中的LinkedList一样。
当列表对象同时满足2个条件时,使用ziplist编码:
- 列表对象保存的所有字符串元素,长度都 < 64字节。
- 列表对象保存的元素数量 ≤ 512个。
两个条件的上限值是可以修改的,具体请看配置文件中关于list-max-ziplist-value选项和list-max-ziplist-entries选项的说明。
列表相关命令
| 命令 | 含义 |
|---|---|
| LPUSH <key> <element> | 将元素推入到压缩列表的表头 |
| RPUSH <key> <element> | 将元素推入到压缩列表的表尾 |
| LINSERT <key> before/after <指定元素> <element> | 在指定元素前面/后面插入元素 |
| LPOP <key> | 返回表头节点,并删除 |
| RPOP <key> | 返回表尾节点,并删除 |
| LRANGE <key> start stop | 获取指定范围内的元素 |
| LINDEX <key> <下标> | 返回指定下标保存的元素 |
| LLEN | 列表的长度 |
| RPOPPUSH 当前数组 目标数组 | 从前一个数组的最后取一个数出来放到另一个数组的头部,并返回元素 |
| BLPOP <key>… timeout | 如果列表中没有元素,那么就等待,如果指定时间(秒)内被添加了数据,那么就执行pop操作,如果超时就作废,支持同时等待多个列表,只要其中一个列表有元素了,那么就能执行 |
哈希对象
哈希对象的编码可以是ziplist或者hashtable。
// Redis默认存String类似于这样:
Map<String, String> hash = new HashMap<>();
// Redis存Hash类型的数据类似于这样:
Map<String, Map<String, String>> hash = new HashMap<>();ziplist编码的哈希对象,每当有新的键值对要加入时,程序会先将保存了键的压缩列表节点推入到压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾,因此保存了键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后。
当哈希对象同时满足如下两个条件时,哈希对象使用ziplist编码:
- 保存的所有键值对,键和值的字符串长度都**< 64字节**。
- 保存的键值对数量**≤ 512个**。
两个条件的上限值是可以修改的,具体请看配置文件中关于hash-max-ziplist-value选项和hash-max-ziplist-entries选项的说明。
哈希相关命令
| 命令 | 含义 |
|---|---|
| HSET <key> [<字段> <值>]… | 添加键值对 |
| HGET <key> <字段> | 根据键,返回值节点 |
| HGETALL <key> | 一次性返回所有的字段和值 |
| HEXISTS <key> <字段> | 根据指定键,查找是否存在键值对 |
| HDEL <key> | 删除Hash中的某个字段 |
| HLEN <key> | 获取键值对的数量 |
| HVALS <key> | 获取所有字段的值 |
集合对象
集合对象的编码可以是intset或者hashtable。
- intset编码的集合对象,包含的所有元素都被保存在整数集合里面。
- hashtable编码的集合对象,字典的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为NULL。
当集合对象同时满足如下两个条件时,使用inset编码:
- 保存的元素都是整数值
- 保存的元素数量**≤512个**。
第二个条件的上限值是可以修改的,具体请看配置文件中关于set-max-intset-entries选项的说明。
集合相关命令
| 命令 | 含义 |
|---|---|
| SADD <key> [<value>] … | 添加元素到集合中 |
| SCARD <key> | 返回集合对象的元素数量 |
| SISMEMBER <key> <value> | 查找元素是否存在 |
| SMEMBERS <key> | 返回所有集合元素 |
| SRANDMEMBER <key> | 随机返回一个元素 |
| SPOP <key> | 随机返回一个元素,并删除 |
| SREM <key> [<value>] … | 批量删除指定的元素 |
| SDIFF <key1> <key2> | 集合之间的差集 |
| SINTER <key1> <key2> | 集合之间的交集 |
| SUNION <key1> <key2> | 集合之间的并集 |
| SDIFFSTORE 目标 <key1> <key2> | 将集合之间的差集存到目标集合中 |
| SINTERSTORE 目标 <key1> <key2> | 将集合之间的交集存到目标集合中 |
| SUNIONSTORE 目标 <key1> <key2> | 将集合之间的并集存到目标集合中 |
| SMOVE <key> 目标 value | 移动指定值到另一个集合中 |
有序集合对象
有序集合的编码可以是ziplist或者skiplist。
当有序集合对象同时满足以下两个条件时,使用 ziplist:
- ZSet 保存的元素数量 ≤ 128 个;
- 每个元素的长度 ≤ 64 字节。
ziplist编码的有序集合对象,每个集合元素使用2个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)。
压缩列表内的集合元素按分值从小到大进行排序,分值较小的元素被放置在靠近表头的方向,而分值较大的元素则被放置在靠近表尾的方向。
skiplist编码的有序集合对象,使用一个zset结构作为底层实现。
typedef struct zset { zskiplist *zsl; dict *dict; } zset;- zsl跳跃表按分值从小到大保存了所有集合元素,每个跳跃表节点都保存了一个集合元素
- dict字典为有序集合创建了一个从成员到分值的映射。通过这个字典,程序可以用$O(1)$复杂度查找给定成员的分值。
有序集合每个元素的成员都是一个字符串对象,而每个元素的分值都是一个double类型的浮点数。虽然zset结构同时使用跳跃表和字典来保存有序集合元素,但这两种数据结构都会通过指针来共享相同元素的成员和分值,所以不会产生任何重复成员或者分值,也不会因此而浪费额外的内存。
有序集合相关命令
| 命令 | 含义 |
|---|---|
| ZADD <key> [<value> <score>] … | 将成员和分值添加到有序集合中 |
| ZCARD <key> | 获取集合元素的数量 |
| ZCOUNT <key> start stop | 统计分值在给定范围内节点的数量 |
| ZRANGE <key> start stop | 从表头向表尾遍历有序集合,返回给定索引范围内的所有元素 |
| ZRANGEBYSCORE <key> start stop [withscores] [limit] | 通过分数段查看 |
| ZREVRANGE | 从表尾向表头遍历有序集合,返回给定索引范围内的所有元素 |
| ZRANK <key> <value> | 获取指定成员对应元素的排名 |
| ZREM <key> [<value>] … | 删除指定对象 |
| ZSCORE | 查找指定成员的分值 |
对象共享
对象的引用计数属性除了用于内存回收,还带有对象共享的作用。
以Redis 3.0来说,Redis在初始化服务器时,会创建1万个字符串对象,包含了从0到9999的所有整数值,当服务器需要用到值为0到9999的字符串对象时,服务器就会使用这些共享对象,而不是新创建对象。创建共享字符串对象的数量可以通过修改redis.h/REDIS_SHARED_INTEGERS常量来修改。
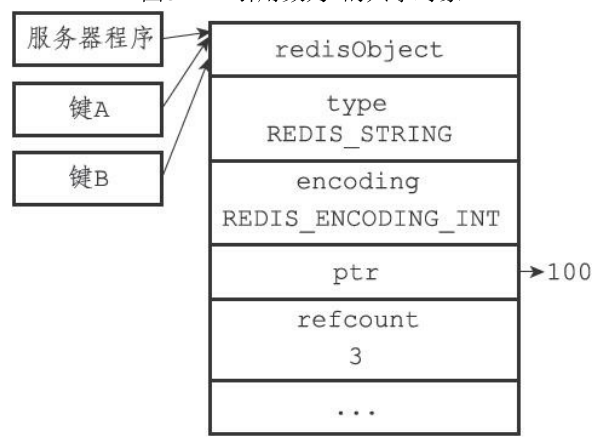
这些共享对象不单单只有字符串键可以使用,那些在数据结构中嵌套了字符串对象的对象(linkedlist编码的列表对象、hashtable编码的哈希对象、hashtable编码的集合对象,以及zset编码的有序集合对象)都可以使用这些共享对象。
由于只有在共享对象和目标对象完全相同的情况下,程序才会将共享对象用作键的值对象,而一个共享对象保存的值越复杂,验证共享对象和目标对象是否相同所需的复杂度就会越高,消耗的CPU时间也会越多,因此,Redis只对包含整数值的字符串对象进行共享。
对象的空转时长
redisObject结构还包含一个lru属性,记录了最后一次被程序访问的时间。OBJECT IDLETIME命令可以打印指定键的空转时长,通过当前时间 - 键的值对象的lru时间得出。OBJECT IDLETIME命令的实现比较特叔,在访问键的值对象时,不会修改值对象的lru属性。
如果服务器打开了maxmemory选项,并且用于回收内存的算法为volatile-lru或者allkeys-lru,那么当服务器占用的内存数超过maxmemory设置的上限值时,空转时长较高的键会被优先释放,从而回收内存。
位图对象
Bitmap 存储的是连续的二进制数字(0 和 1),只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。可以把BitMap看作一个bit数组,数组的下标就是偏移量offset。BitMap内存开销小,效率高且操作简单。
使用场景:统计用户活跃状态(是否登录、签到)
Redis为什么速度快?
Redis基于内存,内存的访问速度是磁盘的上千倍。
Redis基于Reactor模式,设计开发了一套高效的事件处理模型,主要是单线程事件循环和IO多路复用。
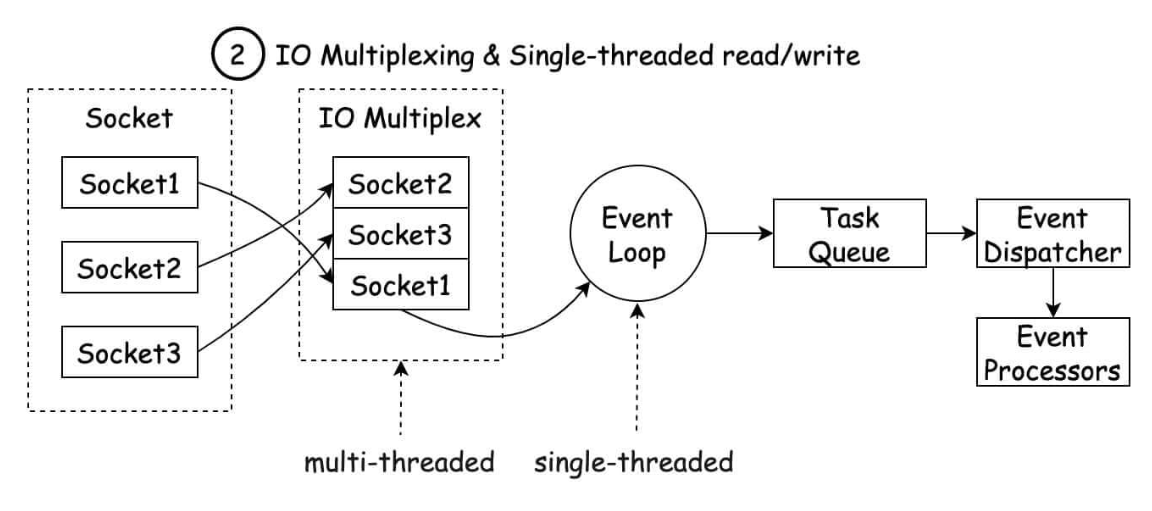
Redis内置了多种优化过后的数据类型/结构实现,性能非常高。
Redis持久化机制
使用缓存的时候,我们经常需要对内存中的数据进行持久化,也就是将内存中的数据写入到硬盘中。大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了做数据同步(比如 Redis 集群的主从节点通过 RDB 文件同步数据)。
Redis 支持 3 种持久化方式:
- 快照(snapshotting,RDB)
- 只追加文件(append-only file, AOF)
- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
RDB 持久化
Redis 可以通过创建快照来获得存储在内存里面的数据在 某个时间点 上的副本。Redis 创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用。
快照持久化是 Redis 默认采用的持久化方式,在 redis.conf 配置文件中默认有此下配置:
# 在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令(单独一个子进程后台执行)创建快照。
save 900 1
# 在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。
save 300 10
# 在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令
save 60 10000 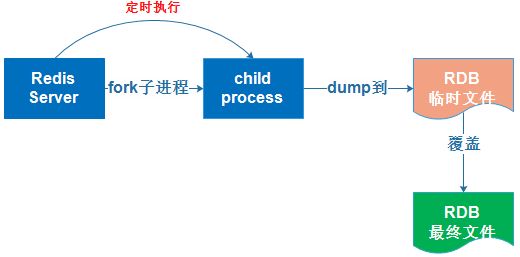
AOF持久化
与快照持久化相比,AOF (append only file)持久化的实时性更好。Redis 6.0 之后默认开启了AOF持久化,可以通过 appendonly 参数开启:
appendonly yes开启 AOF 持久化后,每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 server.aof_buf 中,然后再写入到 AOF 文件中(此时还在系统内核缓存区未同步到磁盘),最后再根据持久化方式( fsync策略)的配置来决定何时将系统内核缓存区的数据同步到硬盘中的。
只有同步到磁盘中才算持久化保存了,否则依然存在数据丢失的风险,比如说:系统内核缓存区的数据还未同步,磁盘机器就宕机了,那这部分数据就算丢失了。
AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 appendonly.aof。

Redis线程模型
对于读写命令来说,Redis 一直是单线程模型。在 Redis 4.0 版本之后引入了多线程来执行一些大键值对的异步删除操作, Redis 6.0 版本之后引入了多线程来处理网络请求(提高网络 IO 读写性能)。
内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接 Out of memory。
Redis 中除了字符串类型有自己独有设置过期时间的命令
setex外,其他方法都需要依靠expire命令来设置过期时间 。另外,persist命令可以移除一个键的过期时间。很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 Token 可能只在 1 天内有效。
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
常见的缓存更新策略
Cache Aside Pattern 旁路缓存模式
比较适合读比较多的场景。
Cache Aside Pattern中,服务端需要同时维系数据库和缓存,并且以db为准。
写步骤:
更新db
直接删除cache
Cache Aside Pattern 旁路缓存模式下,写数据的时候,为什么选择删除cache,而不是更新cache?
对服务端造成资源浪费
删除cache更直接,如果频繁修改db,就会导致需要频繁更新cache,而cache中的数据可能都没有被访问到。
产生数据不一致问题
并发场景下,更新cache产生数据不一致问题的概率会更大。
在写数据的过程中,可以先删除cache,后更新db吗?
不行,可能会造成数据库和缓存数据不一致。
- 请求1先把cache中的A数据删除;
- 请求2从db中读取数据;
- 请求1再把db中的A数据更新。
在写数据的过程中,先更新db,后删除cache就没问题了吗?
还是可能出现数据不一致的问题,不过概率很小,因为缓存写入速度比数据库写入速度快很多。
- 请求1从db中读取数据 (说明此时cache没有缓存该数据)
- 请求2更新db中的数据,删除缓存
- 请求1将读取的数据写入cache (步骤2很难比步骤3快,因为写数据库一般会先加锁)
读步骤:
- 从cache中读,读取到直接返回
- cache中读取不到,就从db读
- 把db中读取到的数据放到cache中
Cache Aside Pattern 旁路缓存模式 的缺陷:
首次请求的数据一定不在cache中。
可以将热点数据提前放入cache。
如果写操作比较频繁,会导致cache中的数据被频繁删除,影响缓存命中率。
数据库和缓存数据强一致
加一个锁/分布式锁,更新db的时候,同样更新cache,保证不存在线程安全问题。
短暂地允许数据库和缓存数据不一致
更新db的时候,同样更新cache,给缓存加一个比较短的过期时间,即使数据不一致,影响也比较小。
Read/Write Through Pattern 读写穿透模式
读写穿透模式中,服务端把cache视为主要数据存储,从中读取数据并将数据写入其中。cache服务负责将此数据读取和写入db,从而减轻应用程序的职责。
这个模式在平时开发过程中非常少见,大概率是因为Redis没有提供cache将数据写入db的功能。
Read-Through Pattern实际只是在Cache Aside Pattern之上进行了封装。在Cache
Aside Pattern下,发生读请求的时候,如果cache中不存在对应的数据,是由客户端自己负责把数据写入cache,而Read Through Pattern则是cache服务自己来写入缓存的,这对客户端是透明的。
Write Behind Pattern 异步缓存写入模式
Write Behind Pattern 异步缓存写入模式 和 Read/Write Through Pattern 读写穿透模式很相似,两者都是由cache服务负责cache和db的读写。
但是读写穿透模式同步更新cache和db,而异步缓存写入模式只是更新缓存,不直接更新db,改为异步批量的方式更新db。
这对数据一致性带来了更大的挑战,比如cache数据可能还没异步更新db,但cache服务就挂掉了。
这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少。比如消息队列中消息的异步写入磁盘、MySQL的Innodb Buffer Pool机制都用到了这种策略。
Write Behind Pattern下db的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
事务和锁机制
# 开启事务
multi
# 输入完所有要执行的命令后,可以立即执行事务
exec
# 可以中途取消事务
discard实际上整个事务是创建了一个命令队列,它不像MySQL那种在事务中也能单独得到结果,而是我们提前将所有的命令装在队列中,但是并不会执行,而是等提交事务的时候再统一执行。
Redis中有乐观锁,不同于MySQL的锁是悲观锁。
- 悲观锁:时刻认为别人会来抢占资源,禁止一切外来访问,直到释放锁,具有强烈的排他性质。
- 乐观锁:并不认为会有人来抢占资源,所以会直接对数据进行操作,在操作时再去验证是否有其他人抢占资源。
# 监视一个目标,如果执行事务之前被监视目标发生了修改,则取消本次事务
watch
# 取消监视
unwatch使用Java与Redis交互
<!-- Jedis is a blazingly small and sane Redis java client. -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.2.0</version>
</dependency>基本操作
public static void main(String[] args) {
// 创建Jedis对象
Jedis jedis = new Jedis("localhost", 6379);
// 使用之后关闭连接
jedis.close();
}通过Jedis对象,可以直接调用命令的同名方法来执行Redis命令:
public static void main(String[] args) {
// 直接使用try-with-resouse,省去close
try (Jedis jedis = new Jedis("192.168.10.3", 6379)) {
jedis.set("test", "hunter"); // 等同于 set test hunter 命令
System.out.println(jedis.get("test")); // 等同于 get test 命令
jedis.hset("hhh", "name", "hunter"); // 等同于 hset hhh name hunter
jedis.hset("hhh", "age", "30"); // 等同于 hset hhh age 30
jedis.hgetAll("hhh").forEach((k, v) -> System.out.println(k + ": " + v));
jedis.lpush("mylist", "111", "222", "333"); // 等同于 lpush mylist 111 222 333 命令
jedis.lrange("mylist", 0, -1)
.forEach(System.out::println); // 等同于 lrange mylist 0 -1
}
}SpringBoot整合Redis - Lettuce
SpringBoot整合的Redis框架底层不是用Jedis,而是Lettuce。Lettuce底层基于Netty,支持高级的Redis特性,比如哨兵、集群、管道、自动重新连接和Redis数据模型。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>starter提供的默认配置会去连接本地的Redis服务器,并使用0号数据库。application.yml中可以进行相应的配置:
spring:
data:
redis:
# Redis服务器地址
host: localhost
# 端口
port: 6379
# 使用几号数据库
database: 0序列化
spring-boot-starter-data-redis已经提供了两个默认的模板类:
StringRedisTemplate:当所有操作都基于字符串,或者你需要确保键和值都是字符串形式时。RedisTemplate<Object, Object>:当需要处理复杂的数据结构(如 Java 对象),或者需要使用 Redis 的各种复杂数据类型时。可以根据需要配置自定义的序列化器以优化性能和可读性。
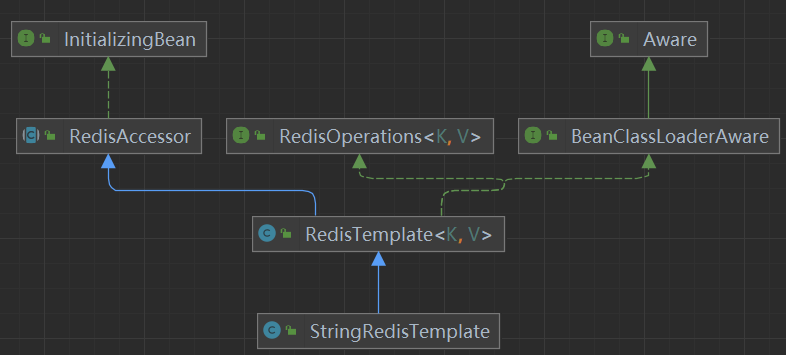
操作redis的模板类 RedisTemplate
public class RedisTemplate<K, V> extends RedisAccessor implements RedisOperations<K, V>, BeanClassLoaderAware {
...
// 序列化相关属性
@SuppressWarnings("rawtypes") private @Nullable RedisSerializer keySerializer = null;
@SuppressWarnings("rawtypes") private @Nullable RedisSerializer valueSerializer = null;
@SuppressWarnings("rawtypes") private @Nullable RedisSerializer hashKeySerializer = null;
@SuppressWarnings("rawtypes") private @Nullable RedisSerializer hashValueSerializer = null;
private RedisSerializer<String> stringSerializer = RedisSerializer.string();
// lua脚本执行器
private @Nullable ScriptExecutor<K> scriptExecutor;
// 对redis各数据结构进行操作的类
private final BoundOperationsProxyFactory boundOperations = new BoundOperationsProxyFactory();
private final ValueOperations<K, V> valueOps = new DefaultValueOperations<>(this);
private final ListOperations<K, V> listOps = new DefaultListOperations<>(this);
private final SetOperations<K, V> setOps = new DefaultSetOperations<>(this);
private final StreamOperations<K, ?, ?> streamOps = new DefaultStreamOperations<>(this,
ObjectHashMapper.getSharedInstance());
private final ZSetOperations<K, V> zSetOps = new DefaultZSetOperations<>(this);
private final GeoOperations<K, V> geoOps = new DefaultGeoOperations<>(this);
private final HashOperations<K, ?, ?> hashOps = new DefaultHashOperations<>(this);
private final HyperLogLogOperations<K, V> hllOps = new DefaultHyperLogLogOperations<>(this);
private final ClusterOperations<K, V> clusterOps = new DefaultClusterOperations<>(this);
...
}StringRedisTemplate:
public class StringRedisTemplate extends RedisTemplate<String, String> {
// 使用StringRedisSerializer 字符串序列化方式
public StringRedisTemplate() {
setKeySerializer(RedisSerializer.string());
setValueSerializer(RedisSerializer.string());
setHashKeySerializer(RedisSerializer.string());
setHashValueSerializer(RedisSerializer.string());
}
...
}RedisSerializer 序列化接口
RedisSerializer接口,用于 Redis KEY 和 VALUE 的序列化。
该接口的实现类:
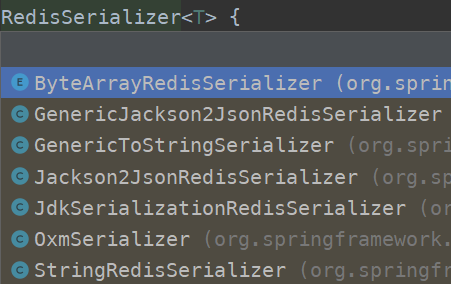
JDK 序列化方式 (默认)
绝大多数情况下,不推荐使用 JdkSerializationRedisSerializer 进行序列化,不方便人工排查数据。
String 序列化方式
JSON 序列化方式
XML 序列化方式
展示一下采用默认的JDK序列化的存储效果:
@SpringBootTest
public class RedisTest {
@Resource
private RedisTemplate redisTemplate;
@Test
public void testRedisTemplate() {
ValueOperations valueOperations = redisTemplate.opsForValue();
valueOperations.set("name", "hunter");
System.out.println(valueOperations.get("name"));
}
}所有的值的操作都被封装到了ValueOperations对象中,而普通的键操作直接通过模板对象就可以使用了,大致使用方式其实和Jedis一致。
虽然在程序中能正常读取指定的key,但是直接查看redis中存储的数据,会发现KEY前面带着奇怪的16进制字符 , VALUE也是一串16进制字符,可读性极差。
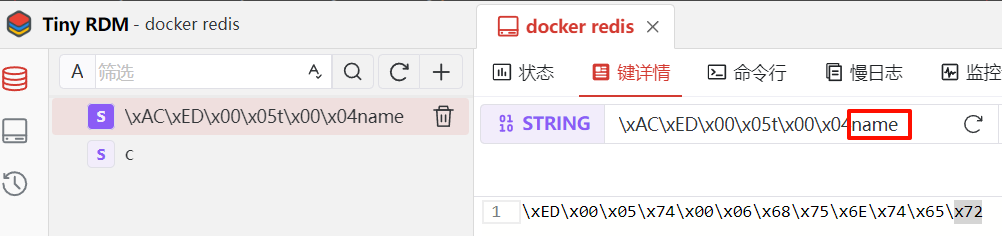
实际线上场景,绝大多数情况下,KEY会使用StringRedisSerializer,VALUE使用JSON序列化居多:
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory); // 设置连接工厂
// 使用StringRedisSerializer.UTF_8作为key和hash key的序列化器
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 使用GenericJackson2JsonRedisSerializer作为value和hash value的序列化器
template.setValueSerializer(RedisSerializer.json());
template.setHashValueSerializer(RedisSerializer.json());
// 对配置进行初始化
template.afterPropertiesSet();
return template;
}
}@SpringBootTest
public class RedisTest {
@Resource
private RedisTemplate<String, User> redisTemplate;
@Test
public void testRedisTemplate() {
ValueOperations<String, User> valueOperations = redisTemplate.opsForValue();
User user = new User();
user.setPhoneNumber("1234567890");
user.setUserName("hunter");
valueOperations.set("user", user);
System.out.println(valueOperations.get("user"));
}
}查看Redis中存储的数据,拥有良好的可读性:
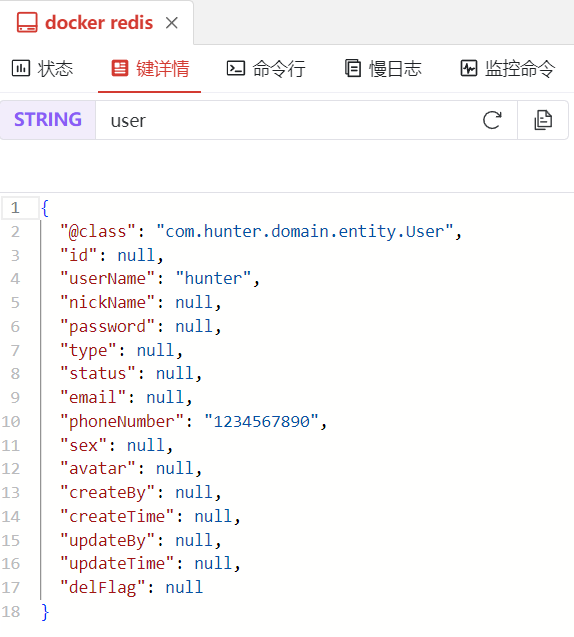
自定义Redis序列化的实现
事务
由于Spring没有专门的Redis事务管理器,所以只能借用JDBC提供的:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>@Service
public class RedisService {
@Resource
StringRedisTemplate template;
@PostConstruct
public void init(){
template.setEnableTransactionSupport(true); //需要开启事务
}
@Transactional // 需要添加事务注解
public void test(){
template.multi();
template.opsForValue().set("d", "xxxxx");
template.exec();
}
}还可以为RedisTemplate对象配置一个Serializer来实现对象的JSON存储:
@Test
void contextLoad2() {
// 注意Student需要实现序列化接口才能存入Redis
template.opsForValue().set("student", new Student());
System.out.println(template.opsForValue().get("student"));
}SpringBoot整合Redis - Redisson
Redisson是构建在Redis上的分布式Java工具包,基于Netty,提供了大量开箱即用的分布式数据结构和服务,例如分布式锁ReentrantLock、分布式集合(Map/List/Set)、分布式队列等。
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
</dependency>redisson的依赖排除了jedis和lettuce的依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</exclusion>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
...
</dependencies>在实际应用中,可以结合Lettuce和Redisson来使用。
RedissonClient是Redisson的客户端接口,通过它来访问和操作Redis中的数据结构。RedissonClient提供了对Redis各种数据类型的封装,如:
- 单个对象存储的抽象
RBucket - List的封装
RQueue - Set、Map等。
Redis相关参数的配置使用RedisConfigProperties类结合配置文件:
@Data
// prefix用于指定配置文件中的属性前缀,映射到该类中对应的字段。如果不配置,就会匹配没有前缀的配置项
@ConfigurationProperties(prefix = "redis.config", ignoreInvalidFields = true)
public class RedisConfigProperties {
private String host;
private int port;
private String password;
/**
* 连接池大小
*/
private int poolSize = 64;
/**
* 连接池最小空闲连接数
*/
private int minIdleSize = 10;
/**
* 连接的最大空闲时间,单位毫秒,超时则关闭连接
*/
private int idleConnectTimeout = 10000;
/**
* 连接超时时间,单位毫秒
*/
private int connectTimeout = 10000;
/**
* 连接重试次数
*/
private int retryAttempts = 3;
/**
* 连接重试间隔时间,单位毫秒
*/
private int retryInterval = 1000;
/**
* 定期查看连接是否可用的时间间隔,单位毫秒。0表示不进行定期检查。
*/
private int pingInterval = 0;
/**
* 是否保持长连接
*/
private boolean keepAlive = true;
}实际的配置在RedisConfig:
@Configuration
@EnableConfigurationProperties(RedisConfigProperties.class)
public class RedisConfig {
@Bean
public RedissonClient redissonClient(RedisConfigProperties properties) {
Config config = new Config();
// 根据需要设定序列化器
// config.setCodec(new RedisCodec());
config.useSingleServer()
.setAddress("redis://" + properties.getHost() + ":" + properties.getPort())
.setConnectionPoolSize(properties.getPoolSize())
.setConnectionMinimumIdleSize(properties.getMinIdleSize())
.setIdleConnectionTimeout(properties.getIdleConnectTimeout())
.setConnectTimeout(properties.getConnectTimeout())
.setRetryAttempts(properties.getRetryAttempts())
.setRetryInterval(properties.getRetryInterval())
.setPingConnectionInterval(properties.getPingInterval())
.setKeepAlive(properties.isKeepAlive());
return Redisson.create(config);
}
}再通过自定义RedissonService类去调用:
@Service
public class RedissonService implements IRedisService {
@Resource
private RedissonClient redissonClient;
@Override
public <T> void setValue(String key, T value) {
// <T>表示getBucket方法返回一个RBucket<T>实例
redissonClient.<T>getBucket(key).set(value);
}
@Override
public <T> void setValue(String key, T value, long expireTime) {
redissonClient.<T>getBucket(key).set(value, Duration.ofMillis(expireTime));
}
@Override
public <T> T getValue(String key) {
return redissonClient.<T>getBucket(key).get();
}
@Override
public <T> RQueue<T> getQueue(String key) {
return redissonClient.getQueue(key);
}
@Override
public <T> RBlockingQueue<T> getBlockingQueue(String key) {
return redissonClient.getBlockingQueue(key);
}
@Override
public <T> RReliableQueue<T> getReliableQueue(String key) {
return redissonClient.getReliableQueue(key);
}
@Override
public void setAtomicLong(String key, long value) {
redissonClient.getAtomicLong(key).set(value);
}
@Override
public Long getAtomicLong(String key) {
return redissonClient.getAtomicLong(key).get();
}
@Override
public long incr(String key) {
return redissonClient.getAtomicLong(key).incrementAndGet();
}
@Override
public long incrBy(String key, long delta) {
return redissonClient.getAtomicLong(key).addAndGet(delta);
}
@Override
public long decr(String key) {
return redissonClient.getAtomicLong(key).decrementAndGet();
}
@Override
public long decrBy(String key, long delta) {
return redissonClient.getAtomicLong(key).addAndGet(-delta);
}
@Override
public void remove(String key) {
redissonClient.getBucket(key).delete();
}
@Override
public <K, V> RMap<K, V> getMap(String key) {
return redissonClient.getMap(key);
}
@Override
public <K, V> V getFromMap(String key, K field) {
return redissonClient.<K, V>getMap(key).get(field);
}
}使用Redis做缓存
MyBatis的二级存储
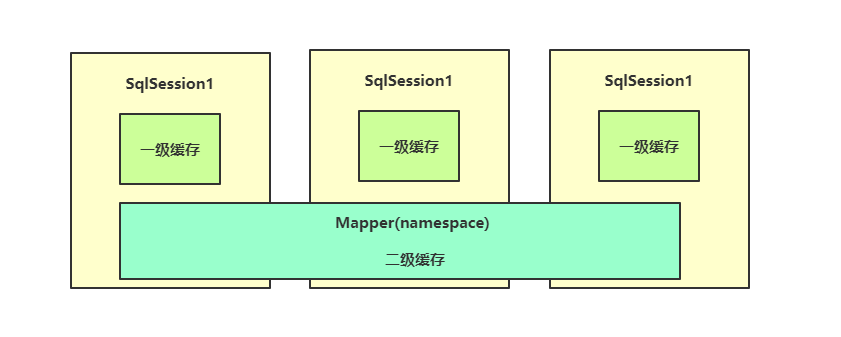
MyBatis的二级缓存,是Mapper级别的缓存,能作用于所有会话。但是MyBatis默认的二级缓存只能是单机的。将Redis作为MyBatis的二级缓存,就能实现多台服务器使用同一个二级缓存,所有的服务器全部存储在Redis服务器上。
编写缓存类
需要编写缓存类RedisMyBatisCache,实现MyBatis提供的Cache接口:
import org.apache.ibatis.cache.Cache;
public class RedisMyBatisCache implements Cache {
private static RedisTemplate<Object, Object> template;
private final String id;
// 构造方法必须带一个String类型的参数接收id
public RedisMyBatisCache(String id) {
this.id = id;
}
// 初始化时通过配置类将RedisTemplate给过来
public static void setTemplate(RedisTemplate<Object, Object> template) {
RedisMyBatisCache.template = template;
}
@Override
public String getId() {
return id;
}
@Override
public void putObject(Object o, Object o1) {
// 直接向Redis数据库中丢数据即可,o就是Key,o1就是Value,60秒为过期时间
template.opsForValue().set(o, o1, 60, TimeUnit.SECONDS);
}
@Override
public Object getObject(Object o) {
// 根据Key直接从Redis数据库中获取值
return template.opsForValue().get(o);
}
@Override
public Object removeObject(Object o) {
// 根据Key删除
return template.delete(o);
}
@Override
public void clear() {
// 由于template中没封装清除操作,只能通过connection来执行
template.execute((return redisTemplate.execute((RedisCallback<Long>) connection ->
connection.serverCommands().dbSize()
).intValue();RedisCallback<Void>) connection -> {
// 通过connection对象执行清空操作
connection.serverCommands().flushDb();
return null;
});
}
@Override
public int getSize() {
// 这里也是使用connection对象来获取当前的Key数量
return Objects.requireNonNull(template.execute(RedisServerCommands::dbSize)).intValue();
}
}编写配置类
@Configuration
public class MyBatisConfiguration {
@Resource
RedisTemplate<Object, Object> template;
@PostConstruct
public void init(){
// 把RedisTemplate给到RedisMybatisCache
RedisMyBatisCache.setTemplate(template);
}
}在Mapper上启用此缓存
// 修改缓存实现类implementation为自定义的缓存类RedisMyBatisCache
@CacheNamespace(implementation = RedisMyBatisCache.class)
@Mapper
public interface MainMapper {
@Select("select name from student where sid = 1")
String getSid();
}Token持久化存储
实现PersistentTokenRepository接口
单独使用SpringSecurity时,remember-me的Token可以设置为持久化存储,是存储在数据库中,那么现在让Token信息存储在缓存中:
// 实现PersistentTokenRepository接口
@Component
public class RedisTokenRepository implements PersistentTokenRepository {
// Key名称前缀,用于区分
private final static String REMEMBER_ME_KEY = "spring:security:rememberMe:";
@Resource
RedisTemplate<Object, Object> template;
@Override
public void createNewToken(PersistentRememberMeToken token) {
// 这里要放两个,一个存seriesId->Token,一个存username->seriesId,因为删除时是通过username删除
template.opsForValue().set(REMEMBER_ME_KEY + "username:" + token.getUsername(), token.getSeries());
template.expire(REMEMBER_ME_KEY + "username:" + token.getUsername(), 1, TimeUnit.DAYS);
this.setToken(token);
}
// 先获取,然后修改创建一个新的,再放入
@Override
public void updateToken(String series, String tokenValue, Date lastUsed) {
PersistentRememberMeToken token = this.getToken(series);
if (token != null) {
this.setToken(new PersistentRememberMeToken(token.getUsername(), series, tokenValue, lastUsed));
}
}
@Override
public PersistentRememberMeToken getTokenForSeries(String seriesId) {
return this.getToken(seriesId);
}
// 通过username找seriesId直接删除这两个
@Override
public void removeUserTokens(String username) {
String series = (String) template.opsForValue().get(REMEMBER_ME_KEY + "username:" + username);
template.delete(REMEMBER_ME_KEY + series);
template.delete(REMEMBER_ME_KEY + "username:" + username);
}
// 由于PersistentRememberMeToken没实现序列化接口,这里只能用Hash来存储了,所以单独编写一个set和get操作
private PersistentRememberMeToken getToken(String series) {
Map<Object, Object> map = template.opsForHash().entries(REMEMBER_ME_KEY + series);
if(map.isEmpty()) return null;
return new PersistentRememberMeToken(
(String) map.get("username"),
(String) map.get("series"),
(String) map.get("tokenValue"),
new Date(Long.parseLong((String) map.get("date"))));
}
private void setToken(PersistentRememberMeToken token) {
Map<String, String> map = new HashMap<>();
map.put("username", token.getUsername());
map.put("series", token.getSeries());
map.put("tokenValue", token.getTokenValue());
map.put("date", ""+token.getDate().getTime());
template.opsForHash().putAll(REMEMBER_ME_KEY + token.getSeries(), map);
template.expire(REMEMBER_ME_KEY + token.getSeries(), 1, TimeUnit.DAYS);
}
}在Mapper上启用MyBatis的Redis二级缓存
@Data
public class Account implements Serializable {
int id;
String username;
String password;
String role;
}@CacheNamespace(implementation = RedisMyBatisCache.class)
@Mapper
public interface AccountMapper {
@Select("select * from users where username = #{username}")
Account getAccountByUsername(String username);
}实现验证Service
@Service
public class AuthService implements UserDetailsService {
@Resource
AccountMapper mapper;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
Account account = mapper.getAccountByUsername(username);
if (account == null) {
throw new UsernameNotFoundException("");
}
return User
.withUsername(username)
.password(account.getPassword())
.roles(account.getRole())
.build();
}
}SecurityConfiguration配置
@Configuration
public class SecurityConfiguration {
@Resource
private RedisTokenRepository tokenRepository;
@Resource
private AuthService authService;
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity httpSecurity) throws Exception {
return httpSecurity
...
.rememberMe(rememberMeConfigurer -> {
rememberMeConfigurer
.tokenRepository(tokenRepository); // 持久化存储
})
.userDetailsService(authService) // 自定义用户验证逻辑
.build();
}
@Bean
public PasswordEncoder passwordEncoder() {
// 将BCryptPasswordEncoder直接注册为Bean,Security会自动处理密码对比
return new BCryptPasswordEncoder();
}
}