Spring Cloud
什么是微服务
传统的单体架构足以满足中小型项目的需求,但是随着项目规模的扩大,实际会暴露越来越多的问题:一台服务器无法承受庞大的单体应用部署;单体应用的维护变得越来越困难……
微服务是一种新的 架构风格:
- 把单体应用拆分成一个个小型服务,独立运行。
- 每个小型的服务,都可以独立部署和升级。
- 微服务之间使用 HTTP 进行数据交互。
- 可以同时使用多台主机部署这些微服务,节省成本的同时,也保证了安全性。
- 一个微服务可以同时存在多个,这样当其中一个出问题时,能保证微服务的高可用。
为什么需要 Spring Cloud
微服务架构存在的问题:
- 项目拆分成微服务之后,需要对各个微服务进行管理、监控等,便于及时发现和排查问题。因此,微服务架构需要 一整套解决方案,包括 服务注册与发现、容灾处理、负载均衡、配置管理 等。
- 在分布式环境下,单体应用的某些功能可能变得麻烦,比如 分布式事务。
为了解决这些问题,Spring Cloud 作为一套分布式的解决方案,集合了一些大型互联网公司的开源产品,共同组成了 Spring Cloud 框架。并且利用 Spring Boot 的开发便利性,简化了分布式系统基础设施的开发,做到一键启动和部署。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>Consul:服务发现和分布式配置
Consul 是一款开源的 分布式服务发现与配置管理系统,由 HashiCorp 公司使用 Go 语言开发。
Docker 安装 Consul
参考:docker 安装 Consul 手把手教程_docker consul-CSDN 博客
docker pull hashicorp/consul:1.20
docker run --name consul1 -d -p 8500:8500 -p 8300:8300 -p 8301:8301 -p 8302:8302 -p 8600:8600 hashicorp/consul:1.20 agent -server -bootstrap-expect=1 -ui -bind=0.0.0.0 -client=0.0.0.0Consul 容器启动后,就能通过 8500 端口进行访问。
服务发现
添加依赖与配置
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
<version>${consul.version}</version>
</dependency>该依赖包含:
spring-cloud-consul-discoveryspring-cloud-starter-consulspring-cloud-starter-loadbalancer
application.yml:
spring:
application:
name: cloud-payment-service
cloud:
consul:
# 配置 consul 地址
host: localhost
port: 8500
discovery:
# 配置当前服务注册到 consul 的服务名
service-name: ${spring.application.name}
# 开启健康检查
heartbeat:
enabled: true
ttl: 10s查找服务
使用 LoadBalancer 根据客户端的负载均衡算法查找服务
Spring 框架的 RestTemplate 类是许多应用程序用来 远程调用 REST 服务 的经典方式。当 Consul 中注册了服务,就能让 RestTemplate 使用 service-name 访问对应的服务。
想要成功解析 service-name,需要为 RestTemplate 实例添加 @LoadBalanced 注解(RestTemplate 和 WebClient 支持使用 @LoadBalanced 实现负载均衡,HttpClient 不支持)。@LoadBalanced 具体作用:
- 解析服务名。
- 负载均衡。自动在多个服务实例间分配请求,实现轮询、随机等负载策略。
声明 RestTemplate 实例:
@LoadBalanced
@Bean
public RestTemplate loadbalancedRestTemplate() {
return new RestTemplate();
}使用 RestTemplate:
private static final String PAYMENT_SERVICE_URL = "http://cloud-payment-service";
@Resource
private RestTemplate restTemplate;
@PostMapping("/pay/add")
public ResponseResult addOrder(PayDto payDto) {
return restTemplate.postForObject(PAYMENT_SERVICE_URL + "/pay/add", payDto, ResponseResult.class);
}
@GetMapping("/pay/get/{id}")
public ResponseResult<PayVo> getPay(@PathVariable("id") Integer id) {
ResponseEntity<ResponseResult<PayVo>> responseEntity =
restTemplate.exchange(
PAYMENT_SERVICE_URL + "/pay/get/" + id,
HttpMethod.GET,
null,
new ParameterizedTypeReference<>() {
}
);
return responseEntity.getBody();
}服务正常启动运行后,可以在 Consul 的 UI 界面看到对应的服务:
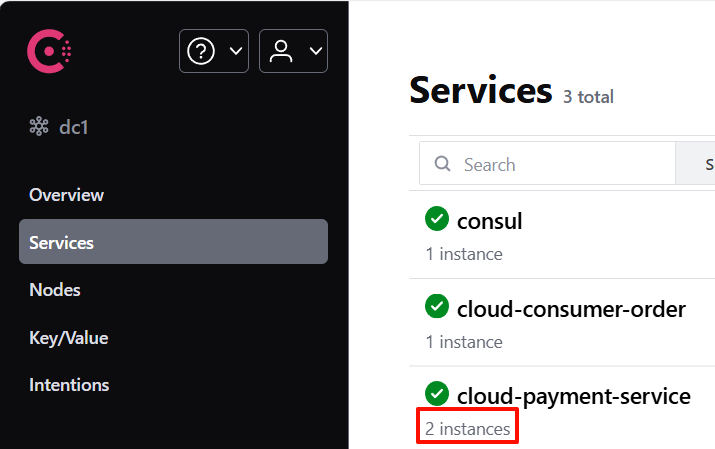
可以看到,同一个服务存在多个实例的情况,负载均衡会生效。
使用 DiscoveryClient 查找服务
import org.springframework.cloud.client.discovery.DiscoveryClient;
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List<ServiceInstance> list = discoveryClient.getInstances("cloud-payment-service");
if (list != null && list.size() > 0 ) {
// 指定访问,跟负载均衡无关
return list.get(0).getUri();
}
return null;
}分布式配置
系统拆分之后产生大量的微服务,每个微服务分别有对应的 yaml 配置文件。如果某个配置项发生了修改,一个个去修改每个微服务的配置文件会很麻烦。因此,需要一套 集中、动态的配置管理设施。可以把这些 全局的配置信息注册到 Consul 中。
添加分布式配置的依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-config</artifactId>
<version>${consul.version}</version>
</dependency>Consul 中配置 Key/Value
创建 config 目录
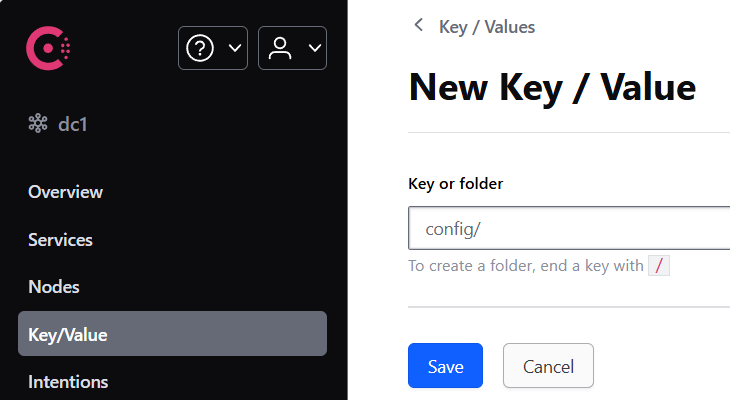
创建微服务的环境配置目录
例如 service-name 为 cloud-payment-service 的微服务,可以创建 3 种环境配置目录:
-dev:开发环境-prod:生产环境- 不带后缀的 默认环境
创建名为 data 的 Key,Value 中写入自定义的配置
YAML 格式的配置文件内容,默认需要名为 data 的 Key。
YAML must be set in the appropriate
datakey in consul.You can change the data key using
spring.cloud.consul.config.data-key.
config/cloud-payment-service/data
config/cloud-payment-service-dev/data
config/cloud-payment-service-prod/data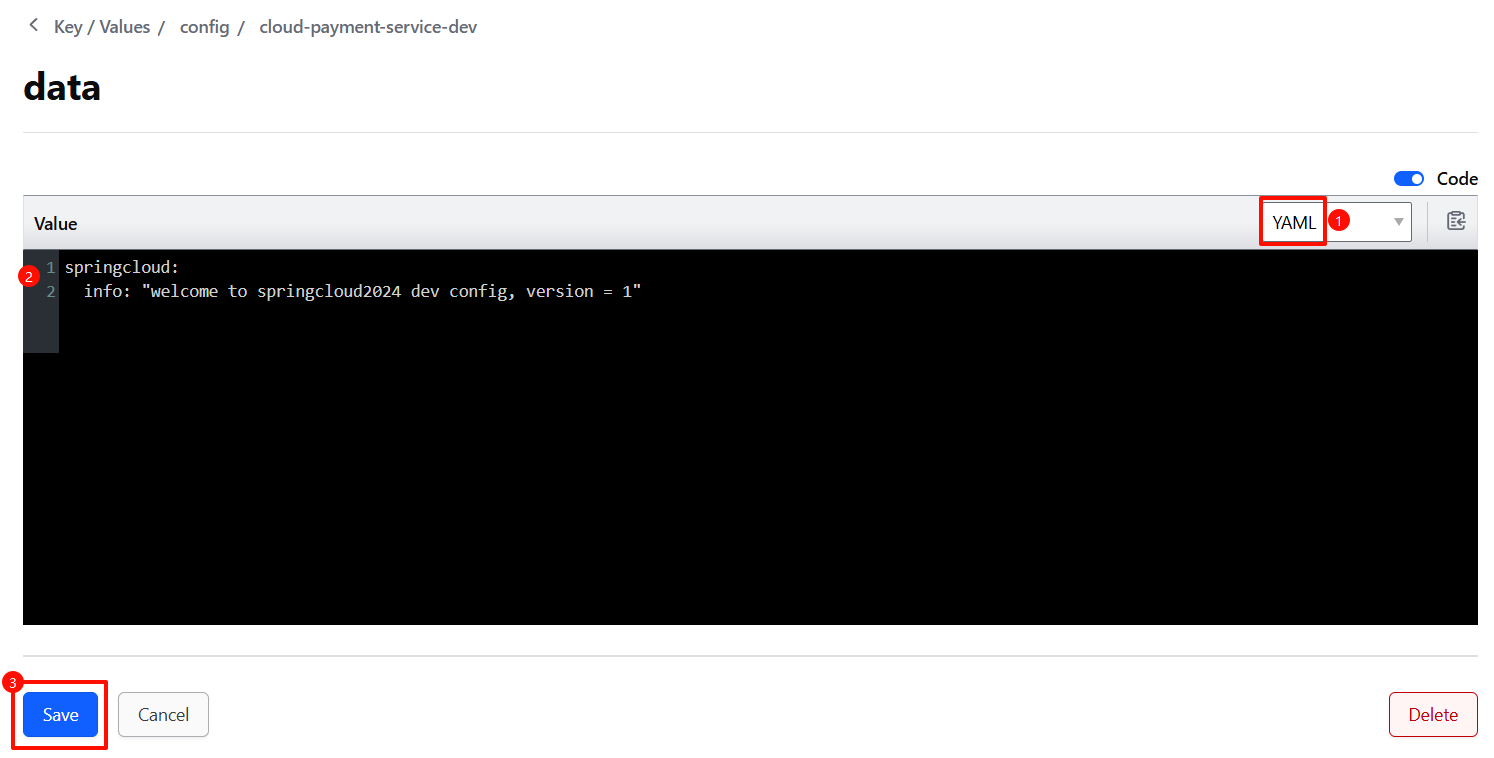
注意:在 Consul 中 填写 YAML 格式的 Value 时,缩进不能用 Tab 键,需要老老实实用空格,否则无法正确识别内容。
Spring Boot 项目中配置 application.yml 文件
spring:
application:
name: cloud-payment-service
cloud:
consul:
# 配置 consul 地址
host: localhost
port: 8500
discovery:
# 配置当前服务注册到 consul 的服务名
service-name: ${spring.application.name}
config:
# consul中Key/Value的文本格式
format: YAML
# 配置文件名以"-"连接
profile-separator: "-"
config:
# optional:导入的配置可选,即使在Consul中没有找到对应的配置,应用程序也能正常启动
# consul:指定了配置的来源是Consul
# 最后的":"表示从Consul的默认配置路径开始 导入配置
# 默认的加载路径前缀是 /config, 会基于配置的consul.discovery.service-name生成完整的配置路径
# 会涉及全局公共配置/config/application和/config/${consul.discovery.service-name}两个路径,对应服务下的配置优先级更高
import: "optional:consul:"
profiles:
# 指定读取的配置文件后缀,结合Consul中的设置,dev会读取config/cloud-payment-service-dev/data下的Value。不填写时,默认读取config/cloud-payment-service/data下的Value
active: dev读取配置内容
使用 org.springframework.beans.factory.annotation.Value 注解,就能够获取 Consul 中保存的配置:
import org.springframework.beans.factory.annotation.Value;
@GetMapping(value = "/get/info")
public String getInfoByConsul(@Value("${springcloud.info}") String info) {
return "This is payment8001, info=" + info;
}动态刷新
当 Consul 中的配置变动后,项目读取的内容也能够动态刷新。Spring Cloud Consul 默认的等待时间 wait-time 和延迟 delay 分别是 55s 和 1s。
spring:
cloud:
consul:
config:
watch:
wait-time: 55
delay: 1000wait-time:定义了 Consul 在一次配置查询中,等待配置更改的最大时间。即,如果在等待的时间中配置没有更改,轮询 Consul 的频率就是 55s/次。能够减少不必要的轮询请求,提高效率。delay:定义了在检测到 Consul 配置变化之后,实际执行更新动作之前的延迟时间。在 Consul 中的配置快速变化的情况下,可以避免频繁重新加载配置。
持久化存储配置数据
如果没有配置持久化存储,Consul 重启之后,配置数据会全部丢失。因此,可以自定义一个目录,例如 consul/data,在容器启动时,通过 -v 选项,挂载到 Consul 容器的 /consul/data 目录上:
docker run --name consul1 -v /consul/data -d -p 8500:8500 -p 8300:8300 -p 8301:8301 -p 8302:8302 -p 8600:8600 hashicorp/consul:1.20 agent -server -bootstrap-expect=1 -ui -bind=0.0.0.0 -client=0.0.0.0LoadBalancer:服务调用和负载均衡
Spring Cloud LoadBalancer :: Spring Cloud Commons
LoadBalancer 的主要作用是提供 客户端 的负载均衡。在调用微服务接口的时候,会从注册中心获取注册信息服务列表,缓存到 JVM 本地,从而实现 RPC 远程服务调用。
作为对比,Nginx 是提供 服务端 的负载均衡,客户端所有的请求都交给 Nginx,由 Nginx 来转发请求。
spring-cloud-starter-consul-discovery 依赖已经依赖了 spring-cloud-starter-loadbalancer 依赖。
参考官方文档:
使用 RestTemplate 作为负载均衡的客户端,只需要添加 @LoadBalanced 注解,就能开启负载均衡。
@Configuration
public class RestTemplateConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}负载均衡算法
LoadBalancer 包含 2 种负载均衡算法:轮询算法 RoundRobinLoadBalancer(默认)、随机算法 RandomLoadBalancer。
OpenFeign:服务调用和负载均衡
Feign 是一个声明式的 Web 服务客户端,使 Web 服务的调用变得容易。OpenFeign 基本上是当前 微服务之间调用的事实接口。
在实际开发中,由于对服务依赖的调用可能不止一处,所以通常会 针对每个微服务自行封装一些客户端类,包装这些依赖服务的调用。OpenFeign 在此基础上做了进一步的封装,只需要创建一个接口,并用注解的方式来配置它,就能完成对服务提供方的接口绑定,统一对外暴露 可以被调用的接口方法,简化和降低了服务调用客户端的开发量。
基本使用
消费端添加依赖,开启 OpenFeign 功能
<!-- openfeign 服务调用 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>${openfeign.version}</version>
</dependency>在启动类上添加 @EnableFeignClients 注解:
// 排除数据源的自动配置
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
// 开启 OpenFeign 功能
@EnableFeignClients
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
}通用模块 新建服务接口,添加 @FeignClient 注解
// value 是服务名,从 Consul 中读取配置。这种可能会被多方调用的服务名,应该作为全局公共配置,放在/config/application/data 下
@FeignClient(value = "${payment-service-name}")
public interface PayFeignApi {
// FeignClient 会去注册中心发现服务,并调用服务的接口
@GetMapping("/pay/get/{id}")
ResponseResult<PayVo> getPay(@PathVariable("id") Integer id);
@PostMapping(value = "/pay/add")
<T> ResponseResult<T> addPay(@RequestBody PayDto payDto);
}消费端进行服务调用
消费端不需要再使用 RestTemplate 类调用 REST 服务,使用 @FeignClient 注解的接口进行调用即可。
@RestController
@RequestMapping("/consumer")
public class OrderController {
@Resource
private PayFeignApi payFeignApi;
@PostMapping(value = "/feign/pay/add")
public <T> ResponseResult<T> addOrder(@RequestBody PayDto payDto) {
// 本地新增订单
// 调用支付服务
return payFeignApi.addPay(payDto);
}
@GetMapping(value = "/feign/pay/get/{id}")
public ResponseResult<PayVo> getPay(@PathVariable("id") Integer id) {
// 调用支付服务
return payFeignApi.getPay(id);
}
}超时控制
比较简单的业务,使用 OpenFeign 的默认配置进行服务间调用,基本没有问题。但是如果业务比较复杂,服务需要进行比较复杂的操作,就 可能会出现 Read Timeout 异常。因此,很有必要 对超时时间进行配置。
OpenFeign 客户端 默认 的 连接超时时间 connect-timeout 是 10s,请求处理超时时间 readTimeout 是 60s:
// feign.Request.Options
public Options() {
this(10, TimeUnit.SECONDS, 60, TimeUnit.SECONDS, true);
}
public Options(
long connectTimeout,
TimeUnit connectTimeoutUnit,
long readTimeout,
TimeUnit readTimeoutUnit,
boolean followRedirects) {
super();
this.connectTimeout = connectTimeout;
this.connectTimeoutUnit = connectTimeoutUnit;
this.readTimeout = readTimeout;
this.readTimeoutUnit = readTimeoutUnit;
this.followRedirects = followRedirects;
this.threadToMethodOptions = new ConcurrentHashMap<>();
}全局配置
全局配置 控制所有的 Feign 超时时间。
spring:
cloud:
openfeign:
client:
config:
default:
# 连接超时时间 3s
connect-timeout: 3000
# 请求处理超时时间 3s
read-timeout: 3000指定配置
指定配置 控制指定微服务 的接口超时时间。指定配置比全局配置优先级高。
spring:
cloud:
openfeign:
client:
config:
# 指定调用某个微服务模块的超时时间
# 可以从Consul中读取配置。这种可能会被多方调用的服务名,应该作为全局公共配置,放在/config/application/data下
${payment-service-name}:
# 连接超时时间 8s
connect-timeout: 8000
# 请求处理超时时间 8s
read-timeout: 8000重试机制
OpenFeign 的重试机制 默认是关闭的。通过编写配置类来开启重试:
import feign.Retryer;
@Configuration
public class FeignConfig {
// 配置 Retryer
@Bean
public Retryer retryer() {
// return Retryer.NEVER_RETRY; 这个是默认的
// 100ms 后开启重试机制
// 重试间隔 1s
// 最大请求次数:3 次
return new Retryer.Default(100, 1, 3);
}
}性能优化
Http 请求连接池
OpenFeign 默认使用 JDK 自带的 sun.net.www.protocol.http.HttpURLConnection 发送 Http 请求。由于它没有连接池,性能和效率比较差,因此可以通过替换为 Apache HttpClient 5。
<!-- httpclient5 提供HTTP客户端基础功能,负责底层的连接管理、请求发送和响应处理等 -->
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
</dependency>
<!-- openfeign对 HttpClient5 的适配器实现,将OpenFeign的注解转换为HttpClient5的请求 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-hc5</artifactId>
</dependency>自动配置类 org.springframework.cloud.openfeign.FeignAutoConfiguration 会检查 classpath 中的可用客户端。当依赖了 httpclient5 时,就会被该自动配置类检测到:
@Configuration(proxyBeanMethods = false)
// 检查 ApacheHttp5Client 类是否存在
@ConditionalOnClass(ApacheHttp5Client.class)
// 没有手动配置的 CloseableHttpClient
@ConditionalOnMissingBean(org.apache.hc.client5.http.impl.classic.CloseableHttpClient.class)
// 检查配置属性,默认启用了 ApacheHttp5Client
@ConditionalOnProperty(value = "spring.cloud.openfeign.httpclient.hc5.enabled", havingValue = "true",
matchIfMissing = true)
@Import(org.springframework.cloud.openfeign.clientconfig.HttpClient5FeignConfiguration.class)
protected static class HttpClient5FeignConfiguration {
@Bean
// 没有其他 Client Bean 生效
@ConditionalOnMissingBean(Client.class)
public Client feignClient(org.apache.hc.client5.http.impl.classic.CloseableHttpClient httpClient5) {
// 创建 feign.hc5.ApacheHttp5Client 实例
return new ApacheHttp5Client(httpClient5);
}
}对请求和响应进行 GZIP 压缩
GZIP 压缩是一种广泛用于 减少文件大小的技术,通过压缩 HTTP 请求或响应的内容,可以 显著减少数据传输的带宽需求,提高传输效率。
spring:
cloud:
openfeign:
# 压缩的配置
compression:
request:
enabled: true
# 请求压缩的最小阈值:2048字节
min-request-size: 2048
mime-types: text/xml, application/xml, application/json
response:
enabled: true日志打印
OpenFeign 输出日志,需要 FeignClient 所在的包日志级别为 debug。
logging:
level:
# 含有@FeignClient注解的完整带包名的接口名
com.hunter.cloud.api.PayFeignApi: debugOpenFeign 的配置类中,设置 OpenFeign 的日志级别:
import feign.Logger;
@Configuration
public class FeignConfig {
/**
* 设置日志级别
* @return Logger.Level
*/
@Bean
public Logger.Level feignLoggerLevel() {
return Logger.Level.BASIC;
}
}
Feign 的日志级别:
NONE:不记录任何日志信息(默认)。BASIC:仅记录请求的方法,URL 以及响应状态码和执行时间。HEADERS:在 BASIC 的基础上,额外记录了请求和响应的头信息FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Resilience4J:容错机制
Resilience4J 是一个轻量级的容错库,提供了一系列的 容错机制,如断路器(Circuit Breaker)、隔离(Bulkhead) 限流(Rate Limiter)等,帮助构建健壮的分布式系统。
断路器 Circuit Breaker
对于 高流量的应用 来说,单一的后端依赖 可能会导致所有服务器上的所有资源在几秒钟内饱和。而且这些应用还可能导致 服务之间的延迟增加,备份队列、线程和其他系统资源紧张,导致整个系统发生更多的级联故障。
因此我们需要一个框架,保证在调用出现问题的情况下,对故障和延迟进行隔离和管理,避免级联故障,从而提高分布式系统的可用性。Circuit Breaker 是 Spring Cloud 提供的一个断路器抽象层,它的核心功能:
统一抽象接口,支持多种断路器实现。
熔断与降级机制。
当服务调用失败达到阈值时,断路器会 快速失败并触发预设的回退逻辑(熔断:拒绝访问、降级:只返回简单的提示),避免资源耗尽和故障扩散。
服务限流。
限制访问微服务的请求的并发量,避免因流量激增出现故障。
<!-- resilience4j 用于服务熔断、降级的断路器实现 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId>
</dependency>
<!-- 断路器需要AOP支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>断路器有 3 个普通状态:CLOSE、OPEN、HALF_OPEN
- 当熔断器处于 CLOSE 状态时,所有请求都会通过 熔断器。
- 如果失败率超过设定的阈值,熔断器就会从 CLOSE 状态转为 OPEN,所有请求都会被拒绝。
- 当处于 OPEN 状态一段时间后,熔断器就会转为 HALF_OPEN 状态,放入一定数量的请求,并重新计算失败率。
- 失败率超过阈值,转为 OPEN 状态,低于阈值,转为 CLOSE 状态。
还有两个特殊状态:DISABLED、FORCED_OPEN,这两个状态不会在生产中使用,不会产生熔断器时间,退出这两个状态的唯一方法是触发状态转换或者重置熔断器。
熔断器 使用滑动窗口来存储和统计调用的结果。可以选择 基于调用数量或者时间 的滑动窗口:
基于调用数量的滑动窗口:统计 最近 N 次 的调用结果。
基于时间的滑动窗口:统计 最近 N 秒 的调用结果。
配置参数
默认值 可见 io.github.resilience4j.circuitbreaker.CircuitBreakerConfig。
| 配置属性 | 默认值 | 描述 |
|---|---|---|
| failureRateThreshold | 50 | 以百分比配置失败率阈值。当 失败率 ≥ 阈值时,断路器开启,并进行服务降级。 |
| slowCallRateThreshold | 100 | 以百分比的方式配置,断路器把调用时间大于 slowCallDurationThreshold 的调用视为慢调用,当 慢调用比例 ≥ 阈值时,断路器开启,并进行服务降级。 |
| slowCallDurationThreshold | 60s | 配置调用时间的阈值,高于该阈值的呼叫视为慢调用,并增加慢调用比例。 |
| permittedNumberOfCallsinHalfopenState | 10 | 断路器在 半开状态下 允许通过的调用次数。如果有 任一请求失败,将重新进入开启状态。 |
| maxWaitDurationInHalfOpenState | 0 | 断路器在 半开状态下的最长等待时间,超过该配置值的话,断路器会从半开状态恢复为开启状态。配置是 0 时表示断路器会一直处于半开状态,直到所有允许通过的访问结束。 |
| slidingwindowType | COUNTBASED | 配置 滑动窗口的类型,当断路器关闭时,将调用的结果记录在滑动窗口中。滑动窗口的类型可以是 count-based 或 timebased。如果滑动窗口类型是 COUNT BASED,将会统计记录最近 slidingwindowsize 次 调用的结果。如果是 TIME BASED,将会统计记录最近 slidingwindowsize 秒 的调用结果。 |
| slidingWindowSize | 100 | 配置 滑动窗口的大小。 |
| minimumNumberOfCalls | 100 | 断路器 计算失败率或慢调用率 之前所需的 最小调用数(每个滑动窗口 周期)。例如,如果 minimumNumberofcalls 为 10,则必须至少记录 10 个调用,然后才能计算失败率。如果只记录了 9 次调用,即使所有 9 次调用都失败,断路器也不会开启。 |
| waitDurationInOpenState | 60s | 断路器 从开启过渡到半开启 应等待的时间。 |
| automaticTransitionFromOpenToHalfOpenEnabled | false | 如果设置为 true,则意味着断路器将 自动从开启状态过渡到半开状态,并且不需要调用来触发转换。创建一个线程来监视断路器的所有实例,以便 在 WaitDurationInOpenstate 之后 将它们转换为半开状态。但是,如果设置为 false,则只有在发出调用时才会转换到半开,即使在 waitDurationlnOpenState 之后也是如此。这里的优点是没有线程监视所有断路器的状态。 |
| recordExceptions | empty | 指定 认为失败的异常列表。除非通过 ignoreExceptions 显式忽略,否则与列表中某个匹配或继承的异常都将被视为失败。如果指定异常列表,则所有其他异常均视为成功,除非它们被 ignoreExceptions 显式忽略。 |
| ignoreExceptions | empty | 被忽略且既不算失败也不算成功的异常列表。任何与列表之一匹配或继承的异常都不会被视为失败感成功,即使异常是 recordExceptions 的一部分。 |
| recordException | throwable -> true By defaultall exceptionsare recored asfailures. | 自定义断言评估异常是否应记录为失败。如果异常应计为失败,则断言必须返回 true。如果出断言返回 false,应算作成功,除非 ignoreExceptions 显式忽略异常。 |
| recordException | throwable -> false By defaultno exceptionsis ignored. | 自定义断言来判断一个异常是否应该被忽略,则谓词必须返回 true。如果异常应算作失败,则断言必须返回 false。 |
实战案例 —— 计数的滑动窗口
- 6 次访问 中当执行方法的 失败率达到 50% 时,CircuitBreaker 进入
OPEN状态,拒绝所有请求。 - 等待 5 秒后,CircuitBreaker 将从
OPEN状态过渡到HALF_OPEN状态,允许一些请求通过以测试服务是否恢复正常。 - 如果还是异常,CircuitBreaker 将 重新进入 OPEN 状态;如果请求正常处理,将进入 CLOSE 状态,恢复正常处理请求。
在 Resilience4j 的 YAML 配置中,
timeout-duration属性需要 直接使用 Duration 字符串格式 而非嵌套结构。IDEA 的默认提示会引导使用 Spring Boot 的 Duration 解析方式,即嵌套结构,导致 Resilience4j 不识别,从而配置无法生效。不生效的写法(嵌套结构)
timeout-duration: seconds: 5 # 错误!Resilience4j不识别这种层级结构生效的写法(ISO8601 持续时间格式)
timeout-duration: 5s
服务端的接口
// Resilience4j 进行断路操作的样例
@GetMapping("/circuit/{id}")
public String myCircuit(@PathVariable("id") Integer id) {
// 模拟一些请求报错的场景
log.info("调用到服务端,参数id为:{}", id);
if (id < 0) {
throw new RuntimeException("----- id 不能为负数 -----");
}
if (id == 9999) {
try {
// 模拟请求处理时间过久,没有返回值
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
return "Hello, circuit. inputId: " + id + "\t 随机值:" + UUID.randomUUID();
}消费端的 application.yml 配置
server:
port: 80
spring:
application:
name: cloud-consumer-order
config:
# optional:导入的配置可选,即使在Consul中没有找到对应的配置,应用程序也能正常启动
# consul:指定了配置的来源是Consul
# 最后的":"表示从Consul的默认配置路径开始 导入配置
# 默认的加载路径前缀是 /config, 会基于配置的consul.discovery.service-name生成完整的配置路径
# 会涉及全局公共配置/config/application和/config/${consul.discovery.service-name}两个路径,对应服务下的配置优先级更高
import: "optional:consul:"
cloud:
consul:
# 配置 consul 地址
host: localhost
port: 8500
discovery:
# 配置当前服务注册到 consul 的服务名
service-name: ${spring.application.name}
# 开启健康检查
heartbeat:
enabled: true
ttl: 10s
config:
# consul中Key/Value的文本格式
format: YAML
openfeign:
client:
config:
default:
# 连接超时时间
connect-timeout: 3000
# 请求处理超时时间,在和resilience4j的timelimiter结合使用时,谁时间短谁生效。
read-timeout: 10000
# 压缩的配置
compression:
request:
enabled: true
# 请求压缩的最小阈值:2048字节
min-request-size: 2048
mime-types: text/xml, application/xml, application/json
response:
enabled: true
# openfeign 的断路器配置,用于监控对外部服务的调用
circuitbreaker:
enabled: true
# 断路器组,允许将多个Feign客户端调用的服务归入同一个组,实现一组服务有统一的断路器策略
group:
enabled: true
resilience4j:
circuitbreaker:
configs:
default:
# 以百分比配置的失败率阈值,>=此阈值则触发熔断
failure-rate-threshold: 50
# 滑动窗口类型为 计数
sliding-window-type: COUNT_BASED
# 滑动窗口大小为 6个请求
sliding-window-size: 6
# 滑动窗口的周期:断路器计算失败率或慢调用率之前所需的最小调用数
minimum-number-of-calls: 6
# 自动从open状态过渡到half-open状态
automatic-transition-from-open-to-half-open-enabled: true
# 从开启状态过渡到半开启状态的等待时间,Period of Time
wait-duration-in-open-state: PT5s
# 半开状态下,允许的最大请求数。如果有任一请求失败,将重新进入开启状态
permitted-number-of-calls-in-half-open-state: 3
# 只要抛出了Exception类及其子类,就作为请求失败进行统计
record-exceptions:
- java.lang.Exception
instances:
# 对具体的服务实例进行定义,
${payment-service-name}:
# 使用名为default的断路器配置
base-config: default
timelimiter:
configs:
default:
# 请求的最大执行时间 Period of Time,默认为1s。
# timeout-duration: PT6s
# 请求超时后,是否取消正在执行的Future
cancel-running-future: true消费端的接口
接口需要添加 @CircuitBreaker 注解,用于指定针对的目标服务,以及服务降级后的兜底处理方法。
当请求的最大执行时间,超过了 resilience4j.timelimiter.config.default.timeout-duration,也会调用指定的 fallbackMethod。
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
@GetMapping(value = "/feign/pay/circuit/{id}")
// name:断路器针对目标服务名生效,fallbackMethod:指定服务降级后的兜底处理方法
@CircuitBreaker(name = "${payment-service-name}", fallbackMethod = "myCircuitFallback")
public String myCircuit(@PathVariable("id") Integer id) {
return payFeignApi.myCircuit(id);
}
/**
* 服务降级后的兜底处理方法
*
* @param t 异常信息
* @return 服务降级后的返回值
*/
public String myCircuitFallback(Integer id, Throwable t) {
return "myCircuitFallback方法兜底,系统繁忙,请稍后再试";
}由于现在通常都 对异常有全局的统一处理,按照统一的格式进行响应,不会粗暴地抛出 Exception,也就不会触发服务降级。因此,通过模拟请求执行时间超时而抛出错误的情况,来测试服务降级的策略是否生效:
交替访问
http://localhost:80/consumer/feign/pay/circuit/9999和http://localhost:80/consumer/feign/pay/circuit/-4,请求 id 为9999时,会因为请求超时而稳定报错。请求 id 为
-4时,会有正常响应。当 第 3 次 发出 id 为
-4的请求时,为总共的第 6 次请求,达到了滑动窗口大小,得到 正常的响应 后,失败率为 50%,触发熔断。之后再马上发出 id 为
-4的请求时,由于服务熔断,会直接调用指定的fallbackMethod。等待 5s,断路器 过渡到半开状态,能处理最多
permitted-number-of-calls-in-half-open-state数量的请求。
实战案例 —— 计时的滑动窗口
计时滑动窗口通过一个固定大小的 由 N 个桶组成的环形数组 实现,每个桶对应一个时间片段,比如 1s。当前时间段的调用结果会记录在数组的第一个桶中,其他桶按时间顺序存储历史统计数据。当时间推移时,旧桶数据会被新桶覆盖,从而实现窗口滚动。
- 每个桶维护 3 个核心指标:失败次数、慢调用次数、总调用次数。
- 同时,使用 1 个 long 类型的变量,记录所有调用的总响应时间。
- 统计时,只聚合各桶数据,无需存储每个调用记录。
这样,能实现 汇总数据实时更新,获取统计快照无需计算 O(1)。内存的消耗仅与桶数量相关 O(n),与调用量无关。同时,通过原子操作实现性能安全,避免性能瓶颈。
消费端的 application.yml 配置:
server:
port: 80
spring:
application:
name: cloud-consumer-order
config:
# optional:导入的配置可选,即使在Consul中没有找到对应的配置,应用程序也能正常启动
# consul:指定了配置的来源是Consul
# 最后的":"表示从Consul的默认配置路径开始 导入配置
# 默认的加载路径前缀是 /config, 会基于配置的consul.discovery.service-name生成完整的配置路径
# 会涉及全局公共配置/config/application和/config/${consul.discovery.service-name}两个路径,对应服务下的配置优先级更高
import: "optional:consul:"
cloud:
consul:
# 配置 consul 地址
host: localhost
port: 8500
discovery:
# 配置当前服务注册到 consul 的服务名
service-name: ${spring.application.name}
# 开启健康检查
heartbeat:
enabled: true
ttl: 10s
config:
# consul中Key/Value的文本格式
format: YAML
openfeign:
client:
config:
default:
# 连接超时时间
connect-timeout: 3000
# 请求处理超时时间
read-timeout: 10000
# 压缩的配置
compression:
request:
enabled: true
# 请求压缩的最小阈值:2048字节
min-request-size: 2048
mime-types: text/xml, application/xml, application/json
response:
enabled: true
# openfeign 的断路器配置,用于监控对外部服务的调用
circuitbreaker:
enabled: true
# 断路器组,允许将多个Feign客户端调用的服务归入同一个组,实现一组服务有统一的断路器策略
group:
enabled: true
resilience4j:
circuitbreaker:
configs:
default:
# 以百分比配置的失败率阈值,超过此阈值则触发熔断
failure-rate-threshold: 50
# 滑动窗口类型为 计时
sliding-window-type: TIME_BASED
# 滑动窗口大小为 2秒
sliding-window-size: 2
# 滑动窗口的周期:断路器计算失败率或慢调用率之前所需的最小调用时间
minimum-number-of-calls: 2
# 慢调用的时间阈值,默认60s
slow-call-duration-threshold: PT2s
# 慢调用的比例峰值,超过此阈值则触发熔断,默认100%
slow-call-rate-threshold: 30
# 自动从open状态过渡到half-open状态
automatic-transition-from-open-to-half-open-enabled: true
# 从开启状态过渡到半开启状态的等待时间
wait-duration-in-open-state: PT5s
# 半开状态下,允许的最大请求数。如果有任一请求失败,将重新进入开启状态
permitted-number-of-calls-in-half-open-state: 3
# 只要抛出了Exception类及其子类,就作为请求失败进行统计
record-exceptions:
- java.lang.Exception
instances:
# 对具体的服务实例进行定义,
${payment-service-name}:
# 使用名为default的断路器配置
base-config: default
timelimiter:
configs:
default:
# 请求的最大执行时间 Period of Time
timeout-duration: PT6s
# 请求超时后,是否取消正在执行的Future
cancel-running-future: true
logging:
level:
# 含有@FeignClient注解的完整带包名的接口名
com.hunter.cloud.api.PayFeignApi: debug隔离壁 BulkHead
隔离壁的作用是用来 限制下游服务的最大并发数量。Resilience4J 提供了两种隔离壁模式的实现:
- 使用信号量的
SemaphoreBulkhead - 使用 1 个有界队列和 1 个固定线程池的
FixedThireadPoolBulkhead
<!-- resilience4j-bulkhead 限制并发线程数,防止资源耗尽 -->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-bulkhead</artifactId>
<version>${bulkhead.version}</version>
</dependency>信号量隔离壁 SemaphoreBulkhead
- 当信号量有空闲时,进入系统的请求会直接获取信号量并开始处理业务。
- 当信号量全被占用时,接下来的请求将 进入阻塞状态。SemaphoreBulkhead 提供了一个阻塞计时器,如果阻塞状态的请求 在阻塞计时内无法获取到信号量,系统就会拒绝这些请求;请求在阻塞计时内获取到了信号量,就能处理业务。
服务端接口:
// Resilience4j 隔离舱操作的样例
@GetMapping(value = "/bulkhead/{id}")
public String myBulkhead(@PathVariable("id") Integer id) {
if (id == 9999) {
try {
// 模拟处理的用时
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
return "Hello, bulkhead. inputId: " + id + "\t 随机值:" + UUID.randomUUID();
}消费端的 application.yml 配置:
resilience4j:
bulkhead:
configs:
default:
# 允许并发线程执行的最大数量,默认值25
max-concurrent-calls: 2
# 达到并发调用的最大数量时,新的线程允许等待的最大时间(阻塞时间),默认值0
max-wait-duration: 1s
timelimiter:
configs:
default:
# 请求的最大执行时间 Period of Time,调大,避免对bulkhead的设置生效产生干扰
timeout-duration: PT20s
# 请求超时后,是否取消正在执行的Future
cancel-running-future: true消费端的接口:
接口需要添加 @Bulkhead 注解,用于指定针对的目标服务,隔离壁的类型,以及隔离壁生效后的兜底处理方法。
import io.github.resilience4j.bulkhead.annotation.Bulkhead;
@GetMapping(value = "/feign/pay/bulkhead/{id}")
@Bulkhead(name = "${payment-service-name}", type = Bulkhead.Type.SEMAPHORE,
fallbackMethod = "myBulkheadFallback")
public String myBulkhead(@PathVariable("id") Integer id) {
return payFeignApi.myBulkhead(id);
}
public String myBulkheadFallback(Integer id, Throwable t) {
return "myBulkheadFallback方法兜底,隔离壁超出最大数量限制,系统放慢,请稍后再试";
}固定线程池隔离壁 FixedThreadPoolBulkhead
FixedThireadPoolBulkhead 使用 1 个有界队列和 1 个 固定线程池 来实现隔离壁。
- 当线程池中存在空闲时,进入系统的请求会直接 开启新线程或者使用线程池中的空闲线程 来处理请求。
- 当线程池中的线程全被占用时,接下来的请求进入等待队列。
- 如果等待队列已满,接下来的请求直接被拒绝。
ThreadPoolBulkhead 只对 CompletableFuture 方法有效,因此 必须创建返回 CompletableFuture 类型的方法。
消费端的 application.yaml:
resilience4j:
thread-pool-bulkhead:
configs:
default:
# 核心线程池大小,即始终保持运行的线程数量
core-thread-pool-size: 1
# 线程池允许的最大线程数量
max-thread-pool-size: 1
# 等待队列的容量,默认100
queue-capacity: 1消费端的接口:
接口需要添加 @Bulkhead 注解,用于指定针对的目标服务,隔离壁的类型,以及隔离壁生效后的兜底处理方法。
@GetMapping(value = "/feign/pay/threadpoolbulkhead/{id}")
@Bulkhead(name = "${payment-service-name}", type = Bulkhead.Type.THREADPOOL,
fallbackMethod = "myThreadPoolBulkheadFallback")
public CompletableFuture<String> myThreadPoolBulkhead(@PathVariable("id") Integer id) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 根据配置的 resilience4j.thread-pool-bulkhead.configs,异步执行
return CompletableFuture.supplyAsync(
() -> payFeignApi.myBulkhead(id) + "\t Builkhead.Type.THREADPOOL");
}
// 线程池隔离壁超出最大数量限制,系统放慢,请稍后再试
public CompletableFuture<String> myThreadPoolBulkheadFallback(Integer id, Throwable t) {
// 异步执行
return CompletableFuture.supplyAsync(
() -> "myThreadPoolBulkheadFallback方法兜底,隔离壁超出最大数量限制,系统放慢,请稍后再试");
}限速器 RateLimiter
系统能提供的最大并发量是有限的,同时请求又过多,这时就需要限流,即通过对并发请求进行限速,或者对一个时间窗口内的请求进行限速,以保护应用系统。一旦达到限制的速率,就可以 进行拒绝服务、排队、降级等处理。
限流算法
漏斗算法 Leaky Bucket
可以看作一个固定容量的漏斗,按照设定速率流出水滴。有两个变量:
- 漏斗的容量(系统允许的 突发请求上限)
- 漏水速率(以 固定的速率处理请求)
由于漏斗的流出速率固定,即使系统有空闲资源,漏斗算法也会强制限速,对于 存在突发特性 的流量来说,可能造成资源浪费。
令牌桶算法 Token Bucket
令牌桶算法通过一个“桶”来控制数据的发送速率,Spring Cloud 默认使用该算法。
- 桶内存储一定数量的令牌,每个令牌代表 1 个数据包的发送权限。
- 令牌 以固定的速率生成,数据包的发送需要消耗令牌。能够一定程度容忍突发的流量。
- 如果桶内没有令牌,数据包需要等待,直到有令牌可用。
滚动时间窗 Tumbling Time Window
滚动时间窗是一种 基于固定时间段 的计数器限流算法。
- 时间窗:将时间划分为 连续、非重叠 的等长区间(如每秒 1 个窗口)。
- 计数器:每个时间窗维护一个计数器,如果超过阈值就拒绝请求。
- 窗口重置:当前窗口结束时,计数器归零,立即开启下一个窗口的计数。
但是当大量请求恰好分布在两个时间窗口的交界处,系统实际允许通过的请求量会短暂达到限流阈值的 2 倍,导致限流失效,这称为 流量突刺。
示例:假设设置了每秒限流 100 次请求。在第一个窗口的最后 1ms,突然涌入 99 个请求,全部允许通过。在第 2 个窗口开始的 1ms,又涌入了 99 个请求,全部允许通过。实际的结果就是,在 2ms 内,通过了 198 个请求,远超阈值。
滑动时间窗 Sliding Time Window
滑动时间窗是一种 动态调整 的限流策略。通过 维护一个持续滑动的时间窗口,统计其中的请求数量来实现流量控制。
与滚动时间窗不同,滑动时间窗 将大窗口划分为多个子窗口,统计时,动态组合这些片段来计算当前窗口的请求量。
工作流程:
- 初始化窗口:设定窗口总长度(如 1s)和子窗口数量(如 5 个 200ms 子窗口)
- 请求到达:记录当前时间戳,并确定所属的子窗口。
- 统计计数:累加当前时间点向前推一个完整窗口内所有窗口的请求量。
- 限流决策:如果统计值超过限流的阈值,就拒绝请求,否则放行,并更新计数。能够有效解决滚动时间窗临界时的流量突刺问题。
实战案例
依赖:
<!-- resilience4j-ratelimiter 限速器,限制请求速率 -->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-ratelimiter</artifactId>
</dependency>如下的依赖已经包含该依赖:
<!-- resilience4j-circuitbreaker 用于服务熔断、降级的断路器实现 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId>
</dependency>服务端接口:
@GetMapping(value = "/ratelimiter/{id}")
public String myRateLimiter(@PathVariable("id") Integer id) {
return "Hello, ratelimiter. inputId: " + id + "\t 随机值:" + UUID.randomUUID();
}消费端的 application.yml 配置:
resilience4j:
ratelimiter:
configs:
default:
# 时间窗口大小,默认500ns
limit-refresh-period: 1s
# 时间窗口内最多允许的请求数量,默认50
limit-for-period: 2
# 获取限流器许可的超时时间,默认5s
timeout-duration: 1s消费端接口:
import io.github.resilience4j.ratelimiter.annotation.RateLimiter;
@GetMapping(value = "/feign/pay/ratelimiter/{id}")
@RateLimiter(name = "${payment-service-name}", fallbackMethod = "myRateLimiterFallback")
public String myRateLimiter(@PathVariable("id") Integer id) {
return payFeignApi.myRateLimiter(id);
}
public String myRateLimiterFallback(Integer id, Throwable t) {
return "你被限流了,禁止访问";
}Micrometer:服务链路追踪
在微服务框架中,一个由客户端发起的请求,在后端系统中会 经过多个不同的服务节点调用 来协同产生最后的请求结果。每个前端请求都会形成一条复杂的分布式调用链路,链路中的任何一个环节出现高延时或错误,都会引起整个请求的失败。因此,我们希望:
- 能够实时观测系统的整体调用链路情况
- 能够快速发现并定位到问题
- 尽可能精确地判断故障对系统的 影响范围和影响程度
- 尽可能精确地梳理出服务之间的依赖关系,判断出 依赖关系 是否合理
- 尽可能精确地分析整个系统调用链路的 性能 与瓶颈点
- 尽可能精确地分析系统的 存储 瓶颈与容量规划
分布式链路追踪就是 将一次分布式请求还原成调用链路,进行日志记录,性能监控,并 将调用情况集中展示,比如各个服务节点上的耗时、请求具体到达的机器、每个服务节点的请求状态等。
分布式链路追踪原理
- Trace ID:每次请求会生成 全局唯一的 Trace ID,贯穿整条调用链,关联跨服务的所有日志和操作。
- 层级 Span 结构
- 每个服务节点会生成 Span 记录(包含 开始和结束时间、元数据)
- 通过 Parent-Span ID 形成树状结构
- 上下文传播:通过 Http 头/X-Ray 头等载体
假设有 3 个微服务调用的链路:Service1 调用 Service2,Service2 调用 Service3 和 Service4:
[Trace ID: 123]
├─ [Span ID: A] (网关)
│ └─ [Span ID: B] (Service1)
│ └─ [Span ID: C] (Service 2)
│ ├─ [Span ID: D] (Service 3)
│ │
│ └─ [Span ID: E] (Service 4)ZipKin
ZipKin 是一款开源的分布式链路跟踪系统的 图形化工具,能够收集微服务运行过程中的实时调用链路信息,并将其展示到 Web 图形化界面上,进而直观地定位并解决问题。
docker pull openzipkin/zipkin:3
docker run -d --name=zipkin -p 9411:9411 openzipkin/zipkin:3启动后访问:http://localhost:9411/zipkin/
实战案例
在项目的父工程 POM 中添加 micrometer 的依赖版本管理中心:
<!-- micrometer 服务链路追踪依赖版本管理中心 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-bom</artifactId>
<version>${micrometer.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>所有微服务模块都应该加入服务链路追踪当中,因此 具体的依赖放入公共模块:
<!-- micrometer 指标追踪 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing</artifactId>
</dependency>
<!-- 用于将micrometer与分布式跟踪工具brave集成,以收集应用的分布式跟踪数据 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-brave</artifactId>
</dependency>
<!-- 观测模块,收集应用的度量数据 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-observation</artifactId>
</dependency>
<!-- feign http客户端的micrometer模块,收集客户端请求的度量数据 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-micrometer</artifactId>
</dependency>
<!-- 将brave跟踪数据报告到zipkin的库 -->
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
</dependency>同样,涉及 micrometer 的公共配置,就存放到 Consul 的公共配置路径 /config/application/data 下,供所有微服务获取该配置:
management:
zipkin:
tracing:
# 指定zipkin服务器的接收端点地址,所示为默认值,用于将微服务收集的链路追踪数据发送到zipkin进行存储。
endpoint: http://localhost:9411/api/v2/spans
tracing:
sampling:
# 采样率,默认0.1(10次请求采样1次),值越大,采样越及时。生产环境通常建议较低的采样率,以平衡性能和监控需求。
probability: 1.0服务端接口:
@GetMapping(value = "/micrometer/{id}")
public String myMicrometer(@PathVariable("id") Integer id) {
return "Hello, micrometer. inputId: " + id + "\t 随机值:" + UUID.randomUUID();
}消费端接口:
@GetMapping(value = "/feign/pay/micrometer/{id}")
public String myMicrometer(@PathVariable("id") Integer id) {
return payFeignApi.myMicrometer(id);
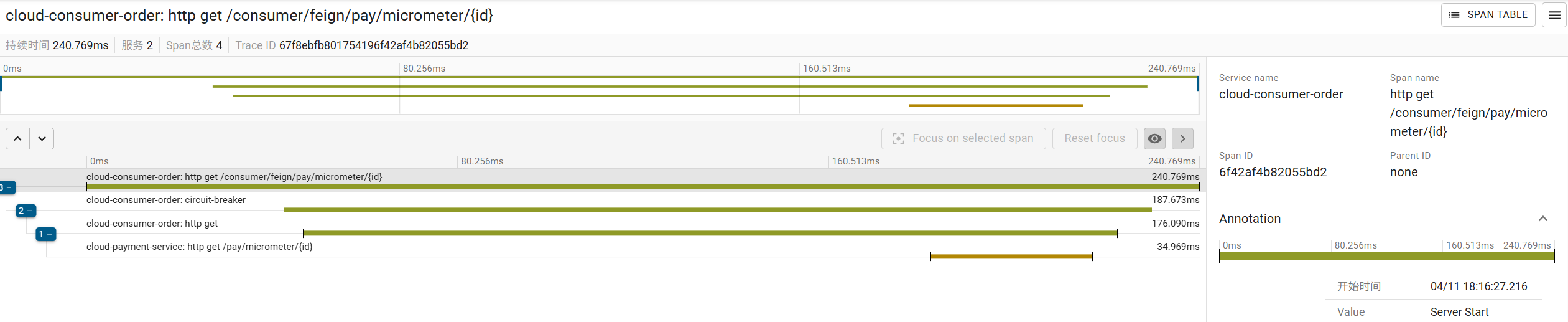
}调用消费端接口后,访问 http://localhost:9411/zipkin/,运行查询,就可以查看到请求,点击对应请求的 SHOW,就能查看详情:

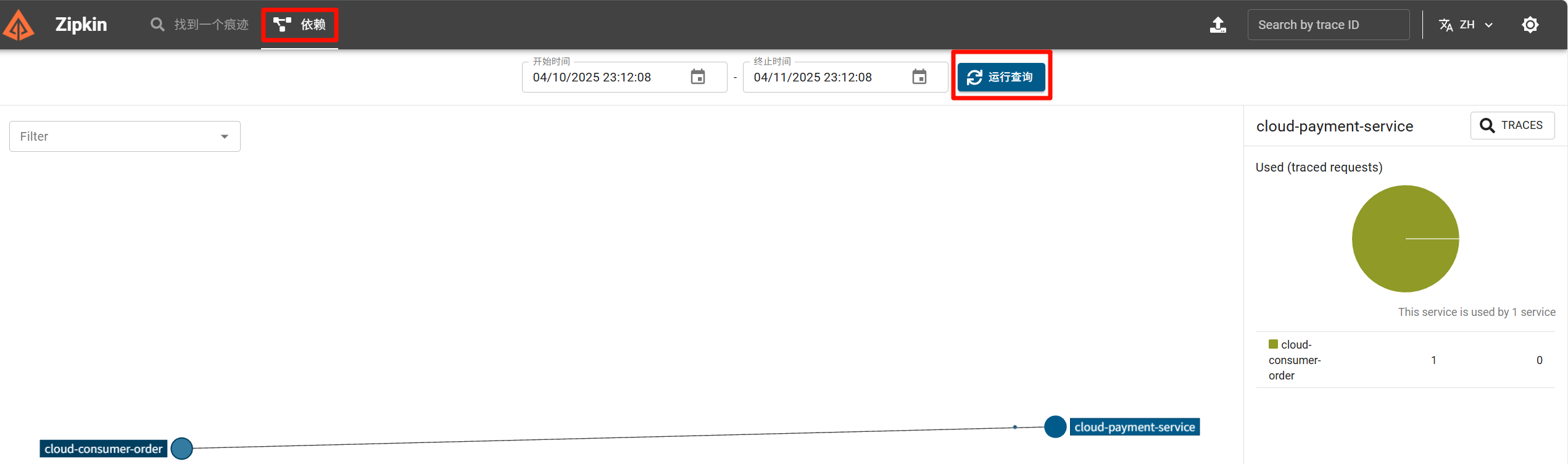
点击依赖标签页下的查询,就能查看图形化展示:
Gateway 网关
Gateway 是在 Spring 生态系统之上构建的 API 网关服务,基于 Spring6、Spring Boot3 和 Project Reactor 等技术。它旨在 为微服务架构提供一种简单有效、统一的 API 路由管理方式,提供跨领域的关注点,例如安全性、监控/度量和恢复能力。
Gateway 的功能有:
- 反向代理
- 鉴权
- 流量控制
- 熔断
- 日志监控
Spring Cloud Gateway 组件的 核心是一系列过滤器,通过这些过滤器,可以将客户端发送的请求转发到对应的微服务。Gateway 是加在整个微服务最前沿的防火墙和代理器,隐藏微服务结点的 IP、端口信息,从而加强安全保护。Gateway 本身也是一个微服务,需要注册到服务注册中心。
三大核心概念
- Route 路由:路由是构建网关的基本模块,它由 ID、目标 URI、一系列的断言和过滤器 组成。
- Predicate 断言:开发人员可以匹配 HTTP 请求中的所有内容,如果请求和断言匹配,就进行路由。
- Filter 过滤器:Spring 框架中
GatewayFilter的实例,使用过滤器,可以在请求被路由之前或者之后 对请求进行修改。在请求之前可以做 参数校验、权限校验、流量监控、日志输出、协议转换 等;在请求之后,可以做 响应内容、响应头修改、流量监控、日志输出 等。
web 前端请求通过断言,定位到真正的服务节点,并在这个转发过程的前后,进行一些精细化控制,再加上目标 URI,就可以实现一个具体的路由。
工作流程
客户端向 Spring Cloud Gateway 发出请求,然后在 Gateway Handler Mapping 中 找到与请求相匹配的路由,将其发送到 Gateway Web Handler。Handler 再 通过指定的过滤器链,将请求发送到实际的服务,执行业务逻辑,然后返回。
实战案例
创建 Gateway 模块 cloud-gateway
pom.xml 中添加依赖:
<!-- Spring Cloud Gateway -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!-- 服务注册发现consul discovery, 网关也要注册进服务注册中心统一管控 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>
<!-- consul 分布式配置 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-config</artifactId>
</dependency>
<!-- 指标监控健康检查的actuator,网关是响应式编程 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>application.yml 中,添加 对目标服务的路由配置:
server:
port: 9527
spring:
application:
name: cloud-gateway
cloud:
consul:
host: localhost
port: 8500
discovery:
service-name: ${spring.application.name}
config:
format: yaml
gateway:
routes:
- id: pay_routh1 # 路由的唯一标识
predicates: # 断言,路由的匹配条件
- Path=/pay/gateway/get/** # 路径匹配
uri: # 匹配后提供路由的目标地址
http://localhost:8001
- id: pay_routh2
predicates:
- Path=/pay/circuit/**
uri:
http://localhost:8001再添加一个主启动类即可:
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}修改 OpenFeign 的相关配置
通用模块的服务接口,把 @FeignClient 注解的 value 由实际的服务提供者更改为网关服务,由网关来统一路由。
// value 是服务名,要和服务提供者的 service-name(在注册中心的名称)相同。从具体的服务改为网关,由网关来统一路由
@FeignClient(value = "${gateway-service-name}")
public interface PayFeignApi { ... }从而实现 通过网关微服务进行统一的路由管理。
注意,当网关微服务出错,如果调用方配置了断路器例如 resilience4j,抛出的错误会被
高级特性
Route 使用微服务名来动态获取服务 URI
通过动态获取服务 URI 来避免硬编码 URI 的问题,微服务名可以配置到 Consul 中,application.yml 的配置变更如下:
routes:
- id: pay_routh1 # 路由的唯一标识
predicates: # 断言,路由的匹配条件
- Path=/pay/gateway/get/** # 路径匹配
uri: # 匹配后提供路由的目标地址
lb://${payment-service-name} # lb为负载均衡,后跟访问的服务名(从Consul中获取)Route Predicate Factories 路由断言工厂
断言用于确定请求是否符合路由条件,每个断言都通过 Predicate Factory 创建。Spring Cloud Gateway 提供了多种内置的 Predicate Factory,可以 根据不同的请求属性来定义路由匹配规则,如路径、方法、请求头信息等。
Configuring Route Predicate Factories and Gateway Filter Factories :: Spring Cloud Gateway
- Shortcut 快捷方式配置
快捷方式配置由 过滤器名称 识别,后跟等号 =,再跟由逗号 , 分隔的参数值。
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- Cookie=mycookie, mycookievalue # 名为mycookie,并且其值为 mycookievalue的Cookie- Fully Expanded 充分展开配置
充分展开的参数看起来更像标准的 yaml 配置。通常有一个 name 键和 args 键。args 用于 配置谓词或筛选条件的键值对的映射。
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- name: Cookie # Cookie类型的谓词
args:
name: mycookie # Cookie的名称
regexp: mycookievalue # mycookie的值需要匹配的正则表达式After/Before/Between
After 路由断言工厂采用 datetime 参数(即 java ZonedDateTime),匹配在指定时间之后发生的请求。
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://example.org
predicates:
- After=2017-01-20T17:42:47.789-07:00[America/Denver]可以通过日志或控制台输出,获取 ZonedDateTime 格式的时间:
@Test
public void test() {
ZonedDateTime zonedDateTime = ZonedDateTime.now();
// 输出格式形如:2025-04-18T20:55:51.761270200+08:00 [Asia/Shanghai]
log.info("{}", zonedDateTime);
}Before 和 Between 路由断言工厂配置同理。只是 Between 断言工厂需要两个 datetime 参数,匹配在 datetime1 之后和 datetime2 之前发生的请求,datetime2 参数必须在 datetime1 之后,两者中间使用 , 分隔。
spring:
cloud:
gateway:
routes:
- id: pay_routh1 # 路由的唯一标识
uri: # 匹配后提供路由的目标地址
lb://${payment-service-name} # lb为负载均衡,后跟访问的服务名(从Consul中获取)
predicates: # 断言,路由的匹配条件
- Path=/pay/gateway/get/** # 路径匹配
- Between=2025-04-18T14:51:49.392967700+08:00[Asia/Shanghai], 2025-04-18T15:59:49.392967700+08:00[Asia/Shanghai]Cookie
Cookie 路由断言工厂采用两个参数,name 和 regexp,匹配指定名称 且 其值与正则表达式匹配 的 Cookie。
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: https://example.org
predicates:
- Cookie=chocolate, ch.p # 名为chocolate,并且其值匹配 ch.p正则表达式 的CookieHeader
Header 路由断言工厂采用 2 个参数,header 和 regexp,匹配指定名称 且 其值与正则表达式匹配的请求头。
spring:
cloud:
gateway:
routes:
- id: header_route
uri: https://example.org
predicates:
- Header=X-Request-Id, \d+ # 名为X-Request-Id的请求头,值为1个或多个数字Host
Host 路由断言工厂采用 1 个参数 Host,主机名模式列表。模式使用 Ant 风格的通配符,并以 . 作为分隔符,匹配请求的 Host 头:
spring:
cloud:
gateway:
routes:
- id: host_route
uri: https://example.org
predicates:
- Host=**.somehost.org, **.anotherhost.orgMethod
Method 路由断言工厂采用 methods 参数:
spring:
cloud:
gateway:
routes:
- id: method_route
uri: https://example.org
predicates:
- Method=GET, POSTPath
路径路由断言工厂接受两个参数:一个 Spring PathMatcher 模式列表 和一个 可选标志 matchTrailingSlash(默认值为 true)。
spring:
cloud:
gateway:
routes:
- id: path_route
uri: https://example.org
predicates:
- Path=/red/{segment}, /blue/{segment} # {segment}表示可以跟任意段落matchTrailingSlash 如果设置为 false,则 请求路径末尾如果存在额外的斜杠,不会被匹配。
Query
RemoteAddr
Weight
自定义断言
Developer Guide :: Spring Cloud Gateway
自定义断言的模板:
@Component public class MyRoutePredicateFactory extends AbstractRoutePredicateFactory<MyRoutePredicateFactory.Config> { public MyRoutePredicateFactory() { super(Config.class); } @Override public Predicate<ServerWebExchange> apply(Config config) { // grab configuration from Config object return exchange -> { //grab the request ServerHttpRequest request = exchange.getRequest(); //take information from the request to see if it //matches configuration. return matches(config, request); }; } public static class Config { //Put the configuration properties for your filter here } }
自定义断言的构造步骤:
- 继承
AbstractRoutePredicateFactory抽象类,泛型为自定义断言的内部Config类。 - 自定义命名,但是 必须以
RoutePredicateFactory后缀结尾(配置文件配置时,仅使用自定义命名的开头进行配置,才能被正确解析) - 编写内部类,命名必须为
Config。 - 编写空参构造方法,使用 super 调用内部
Config类。 - 实现
apply方法,自定义断言的判断逻辑。 - 如果希望 yaml 配置文件配置该自定义断言时 支持 Shortcut 快捷方式配置,需要实现
shortcutFieldOrder方法。
以配置会员等级 userType 为例,判断是否可以访问:
/**
* 自定义会员等级的路由断言工厂
*
*/
@Component
public class UserTypeRoutePredicateFactory extends AbstractRoutePredicateFactory<UserTypeRoutePredicateFactory.Config> {
public UserTypeRoutePredicateFactory() {
// 指定配置类
super(Config.class);
}
/**
* 自定义断言的判断逻辑
*
* @param config 路由断言规则的配置
* @return 路由断言的 Predicate
*/
@Override
public Predicate<ServerWebExchange> apply(Config config) {
return exchange -> {
// 检查 request 中的参数是否与配置的 userType 匹配
String userType = exchange.getRequest().getQueryParams().getFirst("userType");
if (userType == null) {
return false;
}
if (userType.equalsIgnoreCase(config.getUserType())) {
return true;
}
return false;
};
}
/**
* 使用快捷方式配置路由断言时,配置字段的顺序。配置会被转换为完整的 Config 对象,并按照该方法返回的顺序进行赋值。
* @return 路由断言的配置字段的顺序
*/
@Override
public List<String> shortcutFieldOrder() {
// 返回一个包含 userType 字段的单元素列表,表示在简写配置中,userType 应该是第一个(也是唯一的)字段
return Collections.singletonList("userType");
}
/**
* 路由断言规则的配置类
*/
@Setter
@Getter
@Validated
public static class Config {
@NotEmpty
private String userType;
}
}application.yml 配置如下时,能把 用户类型为钻石 这样的要求传入自定义断言,转换为完整的 Config 对象:
Spring:
cloud:
gateway:
routes:
- id: pay_routh1 # 路由的唯一标识
predicates: # 断言,路由的匹配条件
- Path=/pay/get/** # 路径匹配
- UserType=diamond # 自定义的请求参数匹配
uri: # 匹配后提供路由的目标地址
lb://${payment-service-name} # lb表示负载均衡消费端的 Controller 层:
@GetMapping(value = "/feign/pay/get/{id}")
public ResponseResult<PayVo> getPay(@PathVariable("id") Integer id, @RequestParam("userType") String userType) {
log.info("getPay start, id={}, userType={}", id, userType);
// 调用支付服务
return payFeignApi.getPay(id, userType);
}这样,当请求参数携带了 userType=diamond 时,才会访问目标地址:
http://localhost:80/consumer/feign/pay/get/1?userType=diamond
GatewayFilter Factories 网关过滤器工厂
过滤器分别会在请求被执行前后调用,用来修改请求和响应信息。主要作用有:
- 请求鉴权
- 异常处理
- 记录接口调用时长统计
Filter 的类型:
- 全局默认过滤器 Global Filters:Gateway 默认已有,直接使用。主要作用于 所有的路由,无需在配置文件中配置,实现
GlobalFilter接口即可。 - 网关过滤器 Gateway Filter:作用于 单一路由或某个路由分组。
- 自定义过滤器
RequestHeader 请求头相关组
AddRequestHeader添加请求头Spring: cloud: gateway: routes: - id: pay_routh1 # 路由的唯一标识 predicates: # 断言,路由的匹配条件 - Path=/pay/get/** # 路径匹配 filters: - AddRequestHeader=X-Request-hunter1, hunterValue1 # 添加请求头内容,一对KV - AddRequestHeader=X-Request-hunter2, hunterValue2RemoveRequestHeader移除请求头- RemoveRequestHeader=sec-fetch-site # 删除请求头sec-fetch-siteSetRequestHeader修改请求头- SetRequestHeader=sec-fetch-mode, hunter # 将请求头sec-fetch-mode对应的值修改为hunter
在服务端测试效果:
@GetMapping(value = "/get/filter")
public ResponseResult<String> getGatewayFilter(HttpServletRequest request) {
StringBuilder result = new StringBuilder();
Enumeration<String> headerNames = request.getHeaderNames();
while (headerNames.hasMoreElements()) {
String headerName = headerNames.nextElement();
String headerValue = request.getHeader(headerName);
log.info("headerName={}, headerValue={}", headerName, headerValue);
if ("X-Request-hunter1".equalsIgnoreCase(headerName)
|| "X-Request-hunter2".equalsIgnoreCase(headerName)) {
result.append(headerName).append("\t").append(headerValue).append(" ");
}
}
return ResponseResult.success("result: " + result);
}RequestParameter 请求参数相关组
AddRequestParameter添加请求参数- AddRequestParameter=customerId, 9527001 # 新增请求参数Parameter:k, v如果请求本身携带了该请求参数,实际携带的请求参数值会覆盖默认的配置值。
RemoveRequestParameter移除请求参数- RemoveRequestParameter=customerName # 删除url请求参数customerName
在服务端测试效果:
@GetMapping(value = "/get/filter")
public ResponseResult<String> getGatewayFilter(HttpServletRequest request) {
...
String customerId = request.getParameter("customerId");
log.info("customerId={}", customerId);
...
}ResponseHeader 响应头相关组
AddResponseHeader添加响应头参数RemoveResponseHeader移除响应头参数SetResponseHeader修改响应头参数
PrefixPath、SetPath 前缀和路径相关组
PrefixPath自动添加路径前缀# 隐藏路径前缀,访问/gateway/filter,实际会在添加前缀后,访问/pay/gateway/filter predicates: - Path=/gateway/filter/** filters: - PrefixPath=/paySetPath修改路径predicates: - Path=/XYZ/abc/{segment} # {segment}表示可以跟任意段落 filters: - SetPath=/pay/gateway/{segment} # {segment}表示占位符,写abc也行,要上下一致RedirectTo重定向predicates: - Path=/pay/gateway/filter/** # 真实地址 filters: - RedirectTo=302, http://www.bing.com/
Default Filters
相当于全局通用:
spring:
cloud:
gateway:
default-filters:
- AddRequestHeader=X-Request-hunter1, hunterValue1
- RemoveRequestHeader=sec-fetch-site自定义过滤器
自定义全局 Filter
自定义过滤器需要实现 GlobalFilter 和 Ordered 接口,模板如下:
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Component
public class CustomGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
log.info("custom global filter");
return chain.filter(exchange);
}
@Override
public int getOrder() {
return -1;
}
}以 统计接口调用的耗时情况 为例:
package com.hunter.cloud.gatewayFilterFactory;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
@Component
@Slf4j
public class MyGlobalFilter implements GlobalFilter, Ordered {
public static final String BEGIN_VISIT_TIME = "begin_visit_time";
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
exchange.getAttributes().put(BEGIN_VISIT_TIME, System.currentTimeMillis());
// filter 方法将请求传递给下一个过滤器,如果没有过滤器了,就路由至目标服务
// Mono <Void> 是一个异步的,不返回任何值的操作。
// .then 方法是一个 Reactor 操作符,它允许在前一个异步操作之后,再执行一些额外的操作。
// Mono.fromRunnable 方法将一个 Runnable 任务包装成了一个 Mono <Void>
return chain.filter(exchange).then(Mono.fromRunnable(() -> {
Long beginTime = exchange.getAttribute(BEGIN_VISIT_TIME);
if (beginTime!= null) {
log.info("访问接口主机:{}", exchange.getRequest().getURI().getHost());
log.info("访问接口端口:{}", exchange.getRequest().getURI().getPort());
log.info("访问接口URL:{}", exchange.getRequest().getURI().getPath());
log.info("访问接口URL参数:{}", exchange.getRequest().getQueryParams());
log.info("访问接口时长:{}ms", System.currentTimeMillis() - beginTime);
}
}));
}
@Override
public int getOrder() {
return 0;
}
}自定义条件 Filter
Developer Guide :: Spring Cloud Gateway
自定义条件 Filter 的模板:
@Component public class PreGatewayFilterFactory extends AbstractGatewayFilterFactory<PreGatewayFilterFactory.Config> { public PreGatewayFilterFactory() { super(Config.class); } @Override public GatewayFilter apply(Config config) { // grab configuration from Config object return (exchange, chain) -> { //If you want to build a "pre" filter you need to manipulate the //request before calling chain.filter ServerHttpRequest.Builder builder = exchange.getRequest().mutate(); //use builder to manipulate the request return chain.filter(exchange.mutate().request(builder.build()).build()); }; } public static class Config { //Put the configuration properties for your filter here } }
自定义条件过滤器的构造步骤:
- 继承
AbstractGatewayFilterFactory抽象类,泛型为自定义断言的内部Config类。 - 自定义命名,但是 必须以
GatewayFilterFactory后缀结尾(配置文件配置时,仅使用自定义命名的开头进行配置,才能被正确解析) - 编写内部类,命名必须为
Config。 - 编写空参构造方法,使用 super 调用内部
Config类。 - 实现
apply方法,自定义过滤器的判断逻辑。 - 如果希望 yaml 配置文件配置该自定义断言时 支持 Shortcut 快捷方式配置,需要实现
shortcutFieldOrder方法。
@Component
@Slf4j
public class MyGatewayFilterFactory extends AbstractGatewayFilterFactory<MyGatewayFilterFactory.Config> {
public MyGatewayFilterFactory() {
// 指定配置类
super(Config.class);
}
@Override
public GatewayFilter apply(Config config) {
return (exchange, chain) -> {
ServerHttpRequest request = exchange.getRequest();
log.info("进入自定义条件过滤器MyGatewayFilterFactory, status={}", config.getStatus());
// 请求参数中包含 hunter,继续处理
if (request.getQueryParams().containsKey("hunter")) {
return chain.filter(exchange);
} else { // 不包含,直接完成响应
exchange.getResponse().setStatusCode(HttpStatus.BAD_REQUEST);
return exchange.getResponse().setComplete();
}
};
}
/**
* 使用快捷方式配置过滤器时,配置字段的顺序。配置会被转换为完整的 Config 对象,并按照该方法返回的顺序进行赋值。
* @return 过滤器的配置字段的顺序
*/
@Override
public List<String> shortcutFieldOrder() {
// 返回一个包含 status 字段的单元素列表,表示在简写配置中,status 应该是第一个(也是唯一的)字段
return Collections.singletonList("status");
}
@Getter
@Setter
public static class Config {
// 设定一个状态值,匹配后才能访问
private String status;
}
}配置文件 application.yml:
spring:
cloud:
gateway:
routes:
- id: pay_routh1 # 路由的唯一标识
predicates: # 断言,路由的匹配条件
- Path=/pay/get/** # 路径匹配
filters:
- My=hunterSpring Cloud Alibaba 简介
Spring Cloud Alibaba 是阿里巴巴结合自身的微服务实践而推出的微服务开发一站式解决方案,为开发者提供了更多选择。
核心组件:
- Nacos:服务发现和分布式配置
- Sentinel:流量控制、熔断降级
RocketMQ:消息队列Seata:分布式事务Alibaba Cloud OSS:对象存储
Nacos:服务发现和分布式配置
CAP 理论:
- Consistency (一致性):所有节点访问同一份数据,看到的值是相同的。
- Availability (可用性):非故障节点在合理的时间内能返回合理的响应。
- Partition Tolerance (分区容错性):分布式系统出现 网络分区(节点之间不互通,整个网络分成了几块区域) 的时候,仍然能对外提供服务。
Nacos 等价于 Spring Cloud Consul。
- Consul 支持 CP 架构。
- Nacos 默认支持 AP 架构,也支持 CP 架构。
注册中心的对比:
| 服务注册与发现框架 | CAP 模型 | 控制台管理 |
|---|---|---|
| Zookeeper | CP | 不支持 |
| Consul | CP | 支持 |
| Nacos | AP | 支持 |
版本发布说明-阿里云Spring Cloud Alibaba官网
各组件版本适配关系:
Spring Cloud Alibaba Version Spring Cloud Version Spring Boot Version Nacos Version Sentinel Version Seata Version RocketMQ Version 2023.0.1.0* Spring Cloud 2023.0.1 3.2.4 2.3.2 1.8.6 2.0.0 5.1.4
获取 Nacos 的 Docker 镜像:
docker pull nacos/nacos-server:v2.3.2启动 Nacos 容器:映射 Nacos 的 Web 界面端口 8848 到主机的相同端口,并且配置 Nacos 以使用嵌入式数据库运行:
# MODE = standalone 表示以单机模式运行
# -p 8848:8848:映射 HTTP 协议端口。-p 9848:9848:映射 gRPC 协议端口。
docker run --name nacos-server -e MODE=standalone -p 8848:8848 -p "9848:9848" -d nacos/nacos-server:v2.3.2如果希望 Nacos 使用外部 MySQL 数据库,需要传递相应的环境变量到 Docker 容器,例如:
docker run --name nacos-server -p 8848:8848 -p "9848:9848" \
-e MODE=standalone \
-e MYSQL_SERVICE_HOST=<your-mysql-host> \
-e MYSQL_SERVICE_PORT=<your-mysql-port> \
-e MYSQL_DATABASE=<your-db-name> \
-e MYSQL_USER=<your-username> \
-e MYSQL_PASSWORD=<your-password> \
-d nacos/nacos-server:v2.3.2成功启动后,访问 http://localhost:8848/nacos 显示如下界面
依赖:
<dependencies>
<!-- nacos 服务发现 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- 负载均衡 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!-- nacos 配置中心 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- 包含tomcat服务器的web模块 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>application.yml配置文件:
spring:
application:
name: nacos-order-consumer
profiles:
active: dev
config:
# optional:导入的配置可选,即使没有找到对应的配置,应用程序也能正常启动
# nacos:指定了配置的来源是 Nacos。后跟的占位符组成的内容是Nacos配置文件`Data ID`的默认命名规则
import: "optional:nacos:${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}"
cloud:
nacos:
# Nacos Server地址
server-addr: localhost:8848
# 服务发现
# discovery:
# 分布式配置
config:
# 分布式配置的文件扩展名(格式)
file-extension: yaml
group: DEFAULT_GROUP
name服务发现
负载均衡客户端:
/**
* 使用RestTemplate作为HTTP客户端,并开启负载均衡
*/
@Configuration
public class RestTemplateConfig {
@Bean
// 开启负载均衡
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}通过restTemplate发送HTTP请求:
@RestController
@RequestMapping("/consumer")
public class OrderNacosController {
// 要访问的微服务名称,会从Nacos寻找
private static final String PAYMENT_SERVICE_URL = "http://nacos-payment-provider";
@Resource
private RestTemplate restTemplate;
@GetMapping("/pay/nacos/{id}")
public String paymentInfo(@PathVariable("id") Integer id) {
return restTemplate.getForObject(PAYMENT_SERVICE_URL + "/pay/nacos/" + id, String.class);
}
@GetMapping("/pay/get/{id}")
public String getPay(@PathVariable("id") Integer id) {
ResponseEntity<String> responseEntity =
restTemplate.exchange(
PAYMENT_SERVICE_URL + "/pay/get/" + id,
HttpMethod.GET,
null,
new ParameterizedTypeReference<>() {
}
);
return responseEntity.getBody();
}
@DeleteMapping("/pay/delete/{id}")
public String deletePay(@PathVariable("id") Integer id) {
ResponseEntity<String> responseEntity = restTemplate.exchange(
PAYMENT_SERVICE_URL + "/pay/delete/" + id,
HttpMethod.DELETE,
null,
new ParameterizedTypeReference<>() {
}
);
return responseEntity.getBody();
}
}分布式配置
Nacos界面,配置管理的路径为配置管理>配置列表>创建配置,如图所示:
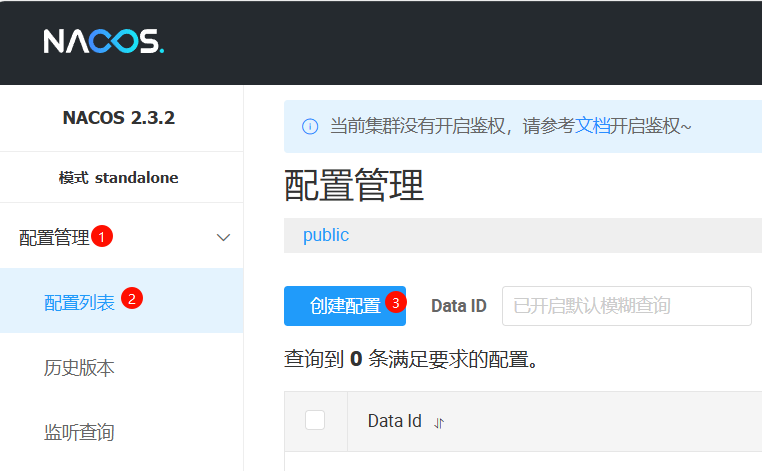
配置文件Data ID的命名规则为:${prefix}-${spring.profiles.active}.${file-extension}。三者都是application.yml中的配置:
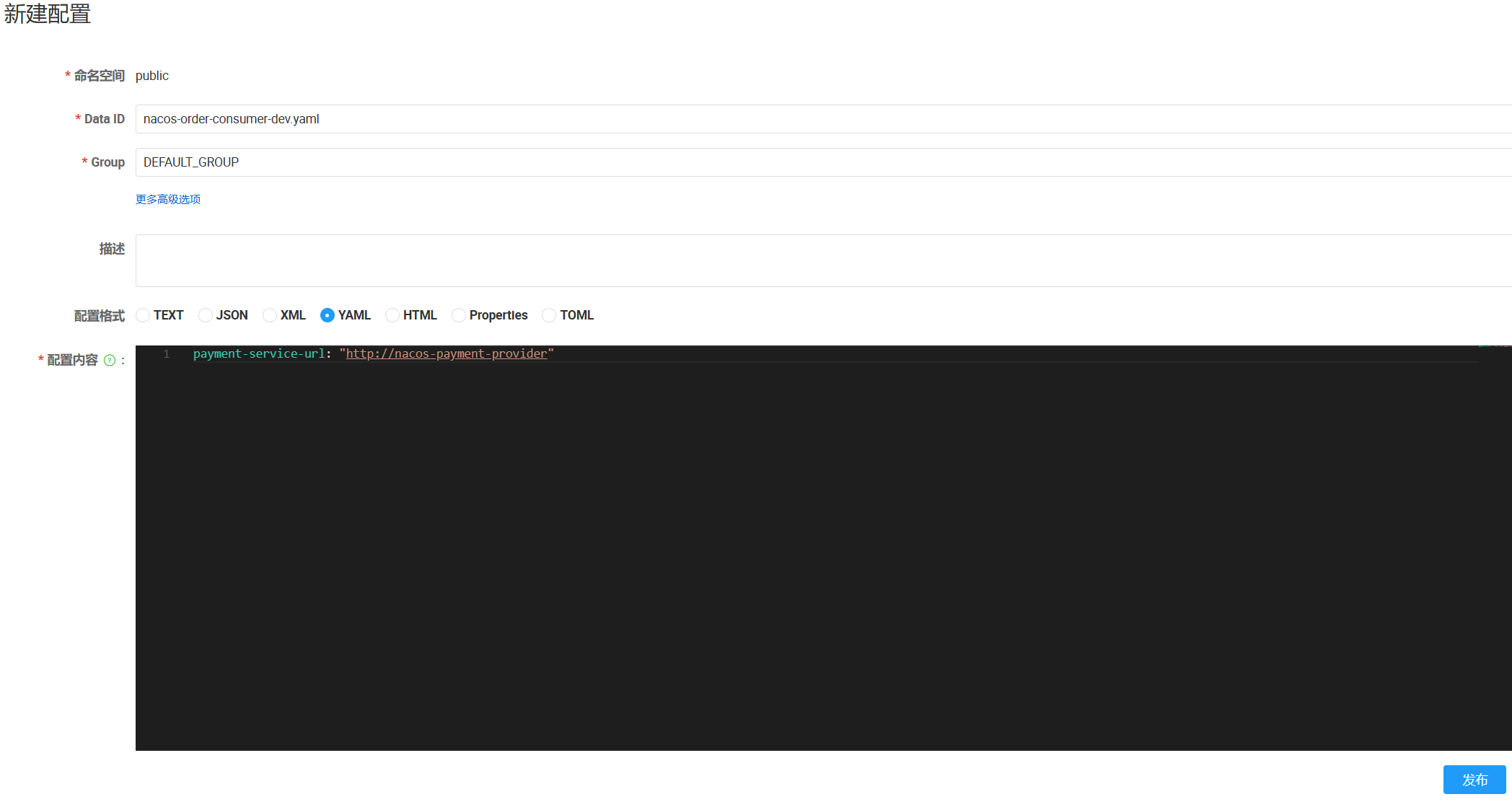
prefix:默认为spring.alication.name的值,也可以通过配置项spring.cloud.nacos.config.prefix来配置。spring.profiles.active:指定当前环境对应的profile,例如dev、prod。当不配置spring.profiles.active时,Data ID的拼接格式变为${prefix}.${file-extension}。spring.cloud.nacos.config.file-extension:指定配置内容的数据格式,如yaml。
在application.yaml中配置完成后, 去Nacos的界面,创建占位符实际填充后的同名的配置文件,并在其中配置内容,进行发布:
控制器类编写业务逻辑:
@RestController
@RequestMapping("/consumer")
// 通过Spring Cloud原生注解,实现配置支持Nacos的动态刷新。
@RefreshScope
public class OrderNacosController {
// 获取Nacos中的配置
@Value("${payment-service-url}")
private String paymentServiceUrl;
@GetMapping("/pay/url")
public String getPaymentServiceUrl() {
return paymentServiceUrl;
}
}历史配置
Nacos会记录配置文件的历史版本,默认保留30天。还有回滚功能。

Nacos 数据模型Key(唯一标识符)
Nacos 数据模型Key由三元组Namespace-Group-DataID唯一确定,Namespace默认是空串,公共命名空间(public),分组默认是 DEFAULT_GROUP。这种分层设计可以帮助用户更好地组织和隔离配置。
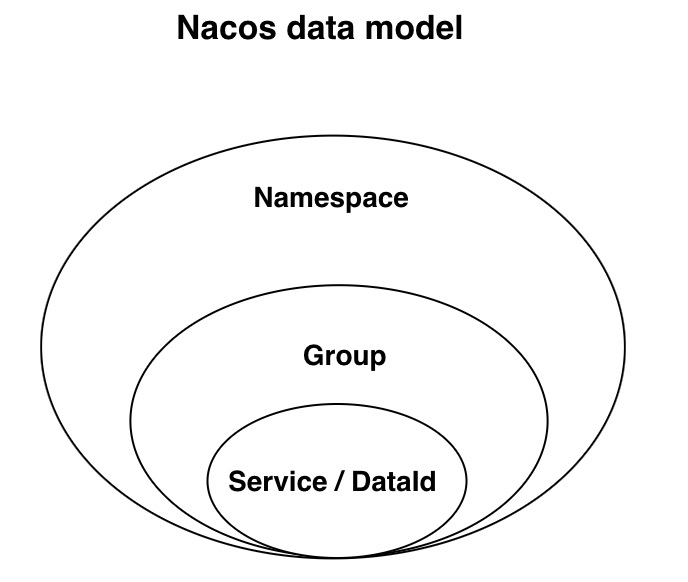
- Namespace 提供了环境或租户级别的隔离,避免不同环境或团队之间的配置冲突。
- Group 提供了逻辑分组的能力,方便对配置进行分类管理。
Sentinel:流量治理
Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。
Sentinel没有提供官方的Docker镜像,使用第三方提供的镜像:
docker pull bladex/sentinel-dashboard:1.8.8
docker run --name sentinel -d -p 8858:8858 -d bladex/sentinel-dashboard:1.8.8访问8858端口即可访问sentinel后端管理界面。用户和密码都是sentinel。

Seata:分布式事务解决方案
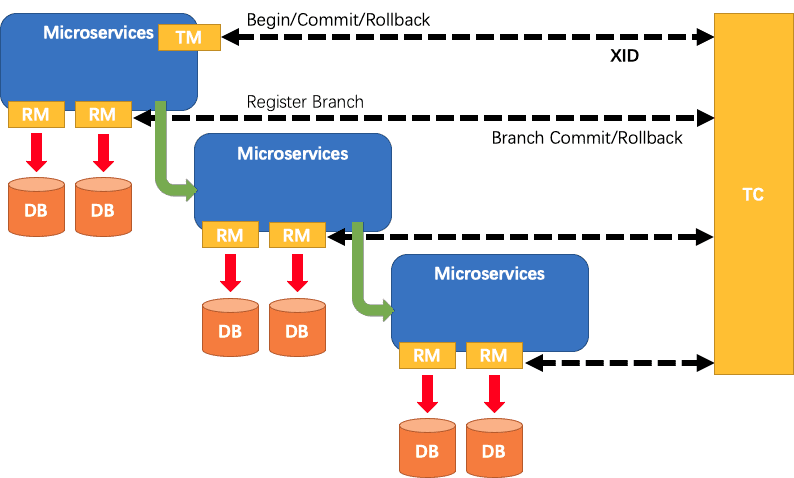
- TC(Transaction Coordinator)事务协调器【班主任】:就是Seata,负责维护全局事务和分支事务的状态,驱动全局事务提交或回滚
- TM(Transaction Manager)事务管理器【班长】:标注全局
@GlobalTransactional启动入口动作的微服务模块(比如订单模块),他是事务的发起者,负责定义全局事务的范围,并根据TC维护全局事务和分支事务状态,做出开始事务、提交事务、回滚事务的决议 - RM(Rescorce Manager)资源管理器【学生】:就是Mysql数据库本身,可以是多个RM,负责管理分支事务上的资源,向TC注册分支事务,汇报分支事务状态,驱动分支事务的调教或回滚。
docker pull apache/seata-server:2.4.0
docker run --name seata-server -p 8091:8091 -p 7091:7091 -d apache/seata-server:2.4.0