简介
Anaconda是一个免费开源的Python和R语言的发行版本,用于计算科学(数据科学、机器学习、大数据处理和预测分析),Anaconda致力于简化包管理和部署。Anaconda的包使用软件包管理系统Conda进行管理。
Anaconda3默认包含Python 3.7,但是用户可以创建虚拟环境来使用任意版本的Python包。
常用命令
- 查看conda版本:
conda --version
- 查看conda的环境配置:
conda config --show
- 更新conda:
conda update conda
- 更新Anaconda整体:
conda update Anaconda
管理环境
Conda允许创建相互隔离的虚拟环境(Virtual Environment),这些环境各自包含属于自己的文件、包以及他们的依存关系,并且不会相互干扰。
创建虚拟环境
conda create -n env_name python=3.8
不指定python版本时,自动创建基于最新python版本的虚拟环境。
创建虚拟环境时,安装必要的包
conda create -n env_name numpy matplotlib python=3.8
列举虚拟环境
conda env list
所显示的列表中,前面带星号*的表示当前活动环境。
激活虚拟环境
conda activate env_name
退出虚拟环境
conda deactivate,回到base
删除虚拟环境、虚拟环境中的包
conda remove --name env_name --allconda remove --name env_name package_name
导出环境
conda env export --name myenv > myenv.yml
还原环境
conda env create -f myenv.yml
管理Package
查询包的安装情况。
conda listconda list pkgname*
查询当前Anaconda repository中是否有想要安装的包
conda search package_name
安装、更新、卸载包
conda install package_nameconda update package_nameconda uninstall package_name
清理缓存
conda clean -p 删除没有用的包 –packagesconda clean -t 删除tar打包 –tarballsconda clean -y -all 删除所有的安装包及cache(索引缓存、锁定文件、未使用过的包和tar包)
conda install vs pip install
- conda可以管理非python包,pip只能管理python包。
- conda自己可以用来创建环境,pip不能,需要依赖virtualenv之类的。
conda安装的包是编译好的二进制文件,安装包文件过程中会自动安装依赖包;pip安装的包是wheel或源码,装过程中不会去支持python语言之外的依赖项。
- conda安装的包会统一下载到一个目录文件中,当环境B需要下载的包,之前其他环境安装过,就只需要把之间下载的文件复制到环境B中,下载一次多次安装。pip是直接下载到对应环境中。
- conda只能在conda管理的环境中使用,例如比如conda所创建的虚环境中使用。pip可以在任何环境中使用,在conda创建的环境 中使用pip命令,需要先安装pip(conda install pip ),然后可以 环境A 中使用pip 。
- conda 安装的包,pip可以卸载,但不能卸载依赖包,pip安装的包,只能用pip卸载。
由于conda的库不如pip的库丰富,有时候可能迫不得已要使用pip安装。只有在conda install搞不定时才使用pip intall。
Windows 通过WSL2 Ubuntu和Docker搭建深度学习环境
参考:
WSL2 Ubuntu安装Docker Engine
设置 Docker的 apt 仓库
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
下载安装Docker的安装包
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
查看docker版本,确认是否成功安装。
❯ docker -v
Docker version 27.1.1, build 6312585
WSL2 下安装Anaconda的Docker镜像
参考Anaconda官网文档Docker — Anaconda documentation
docker pull continuumio/miniconda3:24.5.0-0
docker run -it --name=miniconda continuumio/miniconda3:24.5.0-0 bash
(base) root@8fead34bd870:/
Python 3.12.4
wsl2和windows11共用显卡驱动,因此我们只需安装cudatoolkit和cudnn。以后windows显卡驱动正常更新即可。
windows下nvidia-smi命令查看显卡驱动,以及支持的 CUDA 的最高版本,CUDA Version指的是可驱动的最高版本。
nvidia-smi
Fri Aug 9 23:04:30 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 531.79 Driver Version: 531.79 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3060 Ti WDDM | 00000000:01:00.0 On | N/A |
| 0% 49C P8 10W / 225W| 885MiB / 8192MiB | 3% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 3008 C+G C:\Program Files\Typora\Typora.exe N/A |
| 0 N/A N/A 3372 C+G ...ekyb3d8bbwe\PhoneExperienceHost.exe N/A |
| 0 N/A N/A 7852 C+G ...nt.CBS_cw5n1h2txyewy\SearchHost.exe N/A |
| 0 N/A N/A 9944 C+G ...CBS_cw5n1h2txyewy\TextInputHost.exe N/A |
| 0 N/A N/A 11300 C+G ...les\Microsoft OneDrive\OneDrive.exe N/A |
| 0 N/A N/A 11628 C+G ...t.LockApp_cw5n1h2txyewy\LockApp.exe N/A |
| 0 N/A N/A 11632 C+G ...5n1h2txyewy\ShellExperienceHost.exe N/A |
| 0 N/A N/A 14872 C+G C:\Windows\explorer.exe N/A |
| 0 N/A N/A 15800 C+G ...2txyewy\StartMenuExperienceHost.exe N/A |
| 0 N/A N/A 16008 C+G ...siveControlPanel\SystemSettings.exe N/A |
| 0 N/A N/A 16976 C+G ...64__v826wp6bftszj\TranslucentTB.exe N/A |
| 0 N/A N/A 20136 C+G ...42.0_x64__8wekyb3d8bbwe\GameBar.exe N/A |
| 0 N/A N/A 21440 C+G ...ram Files (x86)\Anycast\Anycast.exe N/A |
| 0 N/A N/A 21848 C+G ...crosoft\Edge\Application\msedge.exe N/A |
| 0 N/A N/A 22204 C+G ...tionsPlus\logioptionsplus_agent.exe N/A |
| 0 N/A N/A 27108 C+G ...voice\logioptionsplus_logivoice.exe N/A |
+---------------------------------------------------------------------------------------+
根据可驱动的最高版本直接去官网下载对应版本:https://developer.nvidia.com/cuda-toolkit-archive
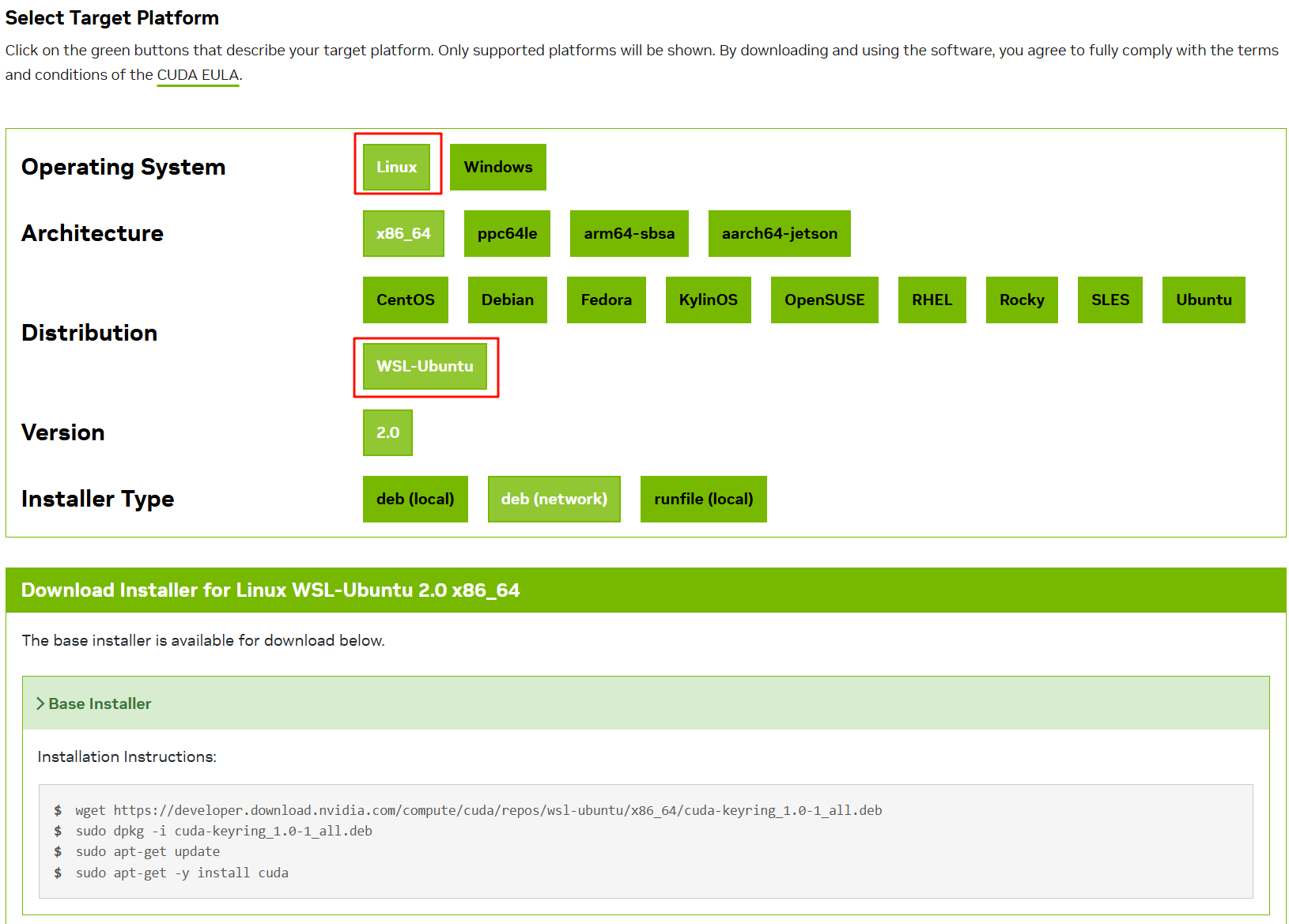
执行官网提供的安装命令:
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.0-1_all.deb
sudo dpkg -i cuda-keyring_1.0-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda
创建环境,安装pytorch
conda create -n pytorch python=3.10
conda active pytorch
Start Locally | PyTorch
根据官网确定环境配置,得到相应的安装命令:
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
plan2
基于 WSL2 和 Docker 的深度学习环境指北 - duanyll
安装Docker Engine
安装带 CUDA 的 PyTorch 镜像
pytorch/pytorch:2.4.0-cuda12.1-cudnn9-devel
若想要使用pycharm连接docker容器,容器端口号必须指定为22,因为SFTP默认使用22端口。
docker run -it –gpus all -p 8077:22 pytorch/pytorch:2.4.0-cuda12.1-cudnn9-devel
进入容器,用which python查看,为/opt/conda/bin/python,可知默认使用conda来管理环境和package。
容器中安装SSH
sudo apt purge openssh-server # wsl2 自带的好像 sshd 不完整,先删除掉
apt update
apt -y upgrade
apt install -y vim openssh-server
service ssh start
service ssh status
设置root密码和配置文件
passwd root
vim /etc/ssh/sshd_config
添加如下内容
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
PermitRootLogin yes
重启ssh
service ssh restart
【详细教程】pycharm使用docker容器开发_pycharm docker-CSDN博客
不知道为什么连不上,只能正常连接子系统和docker。
修复 WSL2 镜像网络模式下无法连接 Docker 的问题 - sulinehk blog - 专注于计算机科学与软件工程的技术博客
可能是添加了这个配置才好的。
直接运行项目中的jupyter notebook内容,会报错:
Running as root is not recommended. Use --allow-root to bypass.
在容器中执行:
jupyter server --generate-config
Writing default config to: /root/.jupyter/jupyter_server_config.py
vim /root/.jupyter/jupyter_server_config.py
安装matplotlib
Matplotlib 是 Python 的绘图库。
conda install -y matplotlib
Matplotlib Pyplot
Pyplot 是 Matplotlib 的子库,提供了和 MATLAB 类似的绘图 API。
Pyplot 是常用的绘图模块,能很方便让用户绘制 2D 图表。
Pyplot 包含一系列绘图函数的相关函数,每个函数会对当前的图像进行一些修改,例如:给图像加上标记,生新的图像,在图像中产生新的绘图区域等等。
使用的时候,我们可以使用 import 导入 pyplot 库,并设置一个别名plt:
import matplotlib.pyplot as plt
一些常用的 pyplot 函数:
plot():用于绘制线图和散点图scatter():用于绘制散点图bar():用于绘制垂直条形图和水平条形图hist():用于绘制直方图pie():用于绘制饼图imshow():用于绘制图像subplots():用于创建子图