SQLserver技术内幕:T-SQL语言基础
T-SQL 查询和编程基础
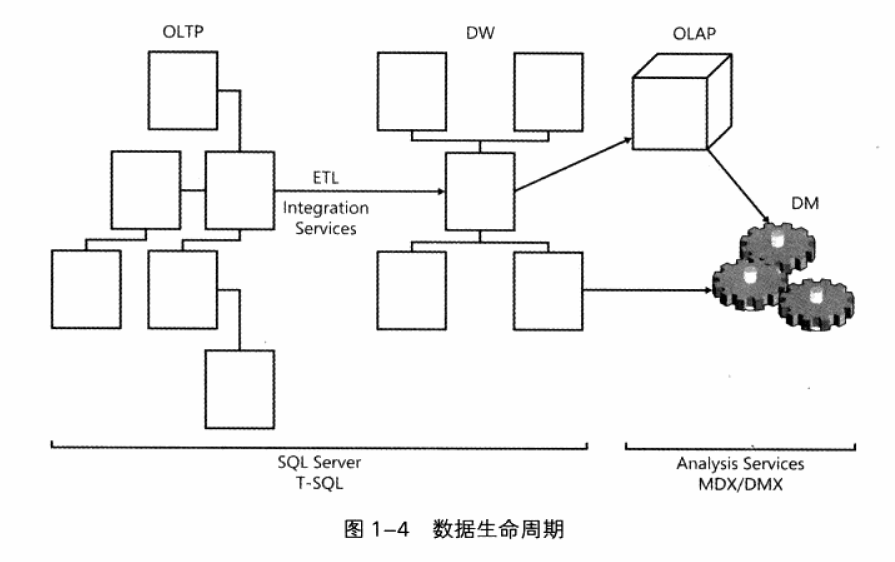
数据生命周期
联机事务处理 (OLTP,OnLine Transactional Processing)
OLTP系统的重点是数据输入,而不是生成报表。主要处理的事务包括插入、更新和删除数据。关系模型的目标主要定位于OLTP系统,一个规范化的模型可以为数据输入和数据一致性提供更好的性能。在规范化的环境中,每个数据表用于表示一个实体,并将数据冗余保持在最低限度。当要修改一个实体事实时,只要在一个地方进行修改,使修改操作得以优化,同时也减少了发生错误的机会。
但OLTP环境不适合生成报表,因为规范化的数据模型通常涉及许多表,表间关系非常复杂,导致查询复杂、性能低下。
数据仓库 (Data Warehouse)
数据仓库是专门针对数据检索和生成报表而设计的环境。当这样的环境服务于整个企业,就称之为数据仓库。主要为了支持数据检索,而对数据仓库中的数据模型进行设计和优化。模型有意保持了一定的冗余,允许通过更少的表和更简单的关系,得到比OLTP环境更加简单和有效的查询。
数据仓库最简单的设计是star schema,它包括多个维度表(dimension table)和一个事实表(fact table)。每个维度代表一个如何分析数据的主题。
例如,在处理订单和销售的系统中,可能要按照客户、产品、雇员、时间等不同的维度对数据进行分析。在star schema中,每个维度实现为一个具有冗余数据的表。例如,一个产品维度应该实现为一个ProductDim表,而不是规范化的三个表:Products、ProductSubCategories和ProductCategories。如果规范化一个维度表,生成表示该维度的多个表,得到的就是所谓的雪花形维度(snowflake dimension),包含雪花形维度的模式就称为雪花模式(snowflake schema)。
事实表存储用户感兴趣的事实和度量(measure),比如与维度主键的每个组合相关的数量和值。例如,对于客户、产品、雇员,以及日期的每个组合,在事实表中将有一行相关的数量和值。数据仓库中的数据通常会预先聚合到某个特定级别的粒度(如日期),而在OLTP环境中的数据通常按照事务级别来记录。
ETL(Extract Transform and Load):从源系统(OLTP以及其它系统)抽取数据,对数据进行处理,并将数据加载到数据仓库的工具。SQL Server提供了叫做Microsoft SQL Server Intergration Services(SSIS)的工具来处理ETL请求。
联机分析处理技术(OLAP, OnLine Analytical Processing)
OLAP系统支持对聚合后的数据进行动态的在线分析,这通常涉及频繁地请求不同级别的聚合。后者又必须对数据进行切片(slicing)和切块(dicing)。如果对于每个这样的请求都要扫描和聚合大量数据,代价高,响应时间久,因此可以预先计算好不同级别的聚合,如时间维度、产品维度。
预先计算不同级别聚合的方法:
- 在关系数据仓库中计算和存储不同级别的聚合。这需要编写一套复杂的过程来处理聚合的初始化和增量更新。
- 适用专门为OLAP需求而设计的特殊产品——Microsoft SQL Server Analysis Services(SSAS)。SSAS是独立于SQL Server服务的一种服务(或引擎),它可以计算不同级别的聚合,并将其保存在一种经过优化的多维结构(多维数据集,cube)中。用于管理和查询SSAS数据方块的语言称为多维表达式(MDX, Multidimensional Expressions)。
数据挖掘(DM, Data Mining)
在动态分析处理中,为了找到有用的信息,用户必须不断地从一种聚合视图定位到另一种视图(进行数据切片和切块)。数据挖掘算法可以梳理数据,从中筛选出有用的信息。
SSAS支持用数据挖掘算法(聚类分析、决策树等)来解决这些需求。用于管理和查询数据挖掘模型的语言是数据挖掘扩展插件语句(DMX, Data Mining Extensions)。
SQL Server 体系结构
SQL Server 实例
SQL Server实例是指安装的一个SQL Server数据库引擎/服务。一台计算机上可以安装多个实例。
数据库
每个SQL Server实例可以包含多个数据库。安装程序创建的系统数据库包括:
- master
保存SQL Server实例范围内的源数据信息、服务器配置、实例中所有数据库的信息,以及初始化信息。
model
model数据库是创建新数据库的模板。每个新创建的数据库最初都是model的一个副本(copy)。如果想在所有新创建的数据库中都包含特定的对象(比如数据类型),或者想在所有新创建的数据库中都以特定的方式来配置某些数据库属性,就可以先把这些对象或配置属性放在model数据库中。
对model数据库做出的修改不会影响已有的数据库,只影响之后新创建的数据库
tempdb
tempdb数据库是SQL Server保存临时数据的地方,包括工作表(work table)、排序空间(sort space)、行版本控制(row versioning)信息等。SQL Server允许用户创建临时表,其存储位置就是tempdb。
每次重新启动SQL Server实例时,会删除这个数据库的内容,并将其重新创建为model的一个副本。
msdb
msdb是SQL Server Agent保存其数据的地方。SQL Server Agent负责自动化处理,包括记录有关作业(job)、计划(schedule)和警报等实体的信息。SQL Server Agent也是负责复制的服务。msdb还用于保存一些有关其他SQL Server功能的信息,例如Database Mail和Service Broker。
可以在数据库级上定义一个称为collation(排序规则)的属性,由它确定数据库中字符数据使用的排序规则信息(包括支持的语言、区分大小写和排序顺序)。如果在创建数据库时不指定collation属性,将使用实例默认的排序规则设置。
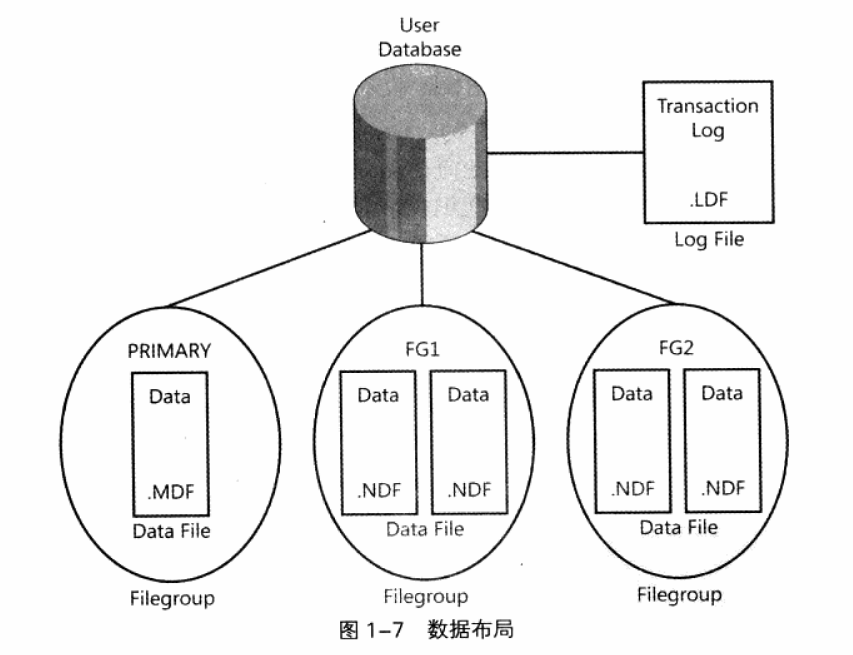
如下图,数据库在物理上由数据文件和事务日志文件组成。当创建数据库时,能够定义每个文件的各种属性,包括文件名、保存位置,以及文件自动扩展的增量。
每个数据库必须至少有一个数据文件和一个日志文件。
- 数据文件(.mdf, .ndf):保存数据库对象数据;
- 日志文件(.ldf, log data file):保存SQL Server为了维护事务而需要的信息;
SQL Server可以并行写多个数据文件,但只能顺序写日志文件,因此使用多个日志文件也不能提升系统的性能。多个数据文件在逻辑上按照文件组(filegroup)的形式进行分组管理。对象数据可能会保存在属于目标文件组的多个文件中。数据库至少要有一个主文件组。PRIMARY文件组包含主数据文件(.mdf, Master Data File)和数据库的系统目录(catalog),可以选择性地为PRIMARY增加多个辅助数据文件(.ndf, secondary data file)。用户定义的文件组只能包含辅助数据文件。
可以指定默认文件组,当对象创建语句没有明确指定目标文件组时,就将其创建在默认文件组中。
架构 (Schema) 和对象
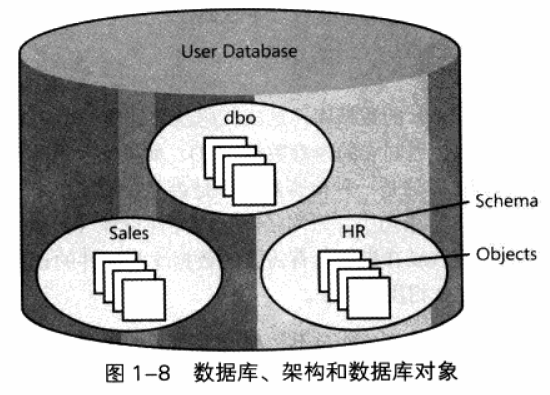
如下图所示,一个数据库包含多个架构,每个架构包含多个对象。可以将架构(Schema)看作是各种对象的容器,这些对象可以是表(table)、视图(view)、存储过程(store procedure)等。
可以在架构级别上控制对象的访问权限。
另外架构也是一个命名空间,用作对象名称的前缀。如果在引用对象时省略架构名称,SQL Server会自行分析,导致可能得到的对象不是原本想要的。
创建表和定义数据完整性
表属于架构,架构属于数据库。
在SQL Server环境中创建一个名为testdb的数据库:
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;DB_ID函数接受一个数据库名称作为参数,返回它的内部数据库ID,如果指定的数据库不存在,将返回NULL。
在这个简单的CREATE DATABASE语句中,采用了默认的文件设置(例如区域和初始大小)。在产品环境中,通常应该显式指定所有需要的数据库和文件的设置。
上述例子中使用的架构是dbo,在每个数据库中都会自动创建dbo架构,并作为默认架构。
创建表
以下代码创建一个名为Employees的表:
USE testdb;
IF OBJECT_ID('dbo.Employees', 'U') IS NOT NULL
DROP TABLE dbo.Employees;
CREATE TABLE dbo.Employees
(
empId INT NOT NULL,
firstName VARCHAR(30) NOT NULL,
lastName VARCHAR(30) NOT NULL,
hireDate DATE NOT NULL,
mgrId INT NULL, -- 经理ID,允许有雇员没有经理,如CEO
ssn VARCHAR(20) NOT NULL, -- social security number,社会保险号
salary MONEY NOT NULL
);USE语句将当前的数据库上下文切换为testdb,它能确保后续操作会在目标数据库中进行。
IF语句调用OBJECT_ID函数,检查当前数据库中是否已经存在Employees表。OBJECT_ID函数接受一个对象名称和类型作为参数,U代表用户定义的表。可填写的类型见SQL SERVER 中的 object_id()函数。如果匹配给定参数的对象存在,该函数就返回内部的对象ID,否则返回NULL。
对于表的每个属性,需要指定它的属性名称、数据类型和是否允许NULL值。如果不显式指定一个列是否允许NULL值,SQL Server则采用默认值,ANSI规定默认为NULL。除非有明显的原因必须要支持NULL,各属性最好都定义为NOT NULL。
定义数据完整性
- 声明式(declarative)数据完整性:作为表定义的一部分而实施的数据完整性。
- 过程式(procedural)数据完整性:用代码来实施的数据完整性。
为属性选择数据类型和是否与允许NULL值,甚至数据模型本身,都是声明式数据完整性约束的例子。当用CREATE TABLE语句创建表时,可以同时定义这些约束;或者在表已创建的情况下,用ALTER TABLE语句增加这些约束。
除了DEFAULT约束以外,其他所有约束都可以定义为组合约束(即基于一个或多个属性的约束)。
主键约束 (Primary Key Constraints)
主键约束用于实施行的唯一约束,同时不允许约束属性取NULL值,表内的每行数据可以被唯一确定。每个表只能定义一个主键。
以上述创建的Employees表为例,在empId上定义一个主键约束:
ALTER TABLE dbo.Employees
ADD CONSTRAINT PK_Employees
PRIMARY KEY(empId);为了实施逻辑主键约束的唯一约束,SQL Server在幕后创建一个唯一索引(unique index)。也可以用索引来加速查询的处理,避免对整个表进行不必要的扫描。
唯一约束 (nique Constraints)
唯一约束用来保证数据行的一个列(或一组列)数据的唯一,可以在数据库中实现关系模型的替换键(alternate key)的概念。与主键不同,同一个表中可以定义多个唯一约束,唯一约束也不限于只定义在NOT NULL列上。SQL Server支持只允许在唯一约束列中有一个列可以为NULL值。
以下代码在Employees表中定义了ssn列上的一个唯一约束:
ALTER TABLE dbo.Employees
ADD CONSTRAINT UNQ_Employees_ssn -- 增加约束
UNIQUE(ssn);和主键约束一样,SQL Server也在幕后为唯一约束创建一个唯一索引。
外键约束
外键约束用于实施引用完整性。这种约束在引用表(referencing table)的一组属性上进行定义,并指向被引用表(referenced table)中的一组候选键(主键或唯一约束)。引用表和被引用表可能是同一个表。外键的目的是为了将外键列允许的值域限制为被引用列中现有的值。
以下代码创建了一个名为Orders的表,其主键定义在orderid列上:
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
CREATE TABLE dbo.Orders
(
orderId INT NOT NULL,
empId INT NOT NULL,
custId VARCHAR(10) NOT NULL,
orderTs DATETIME NOT NULL,
qty INT NOT NULL,
CONSTRAINT PK_Orders -- 定义约束
PRIMARY KEY(OrderID)
);接下来在Orders表的empId列上定义一个外键约束,让它指向Employees表的empId列:
ALTER TABLE dbo.Orders
ADD CONSTRAINT FK_Orders_Employees
FOREIGN KEY(empId)
REFERENCES dbo.Employees(empId);引用表和被引用表可能是同一个表。
限制Employees表的mgrId列的值域为同一个表中已存在的那些empId列的值,可以增加如下外键约束:
ALTER TABLE dbo.Employees
ADD CONSTRAINT FK_Employees_Employees
FOREIGN KEY(mgrId) -- 依然允许NULL值
REFERENCES dbo.Employees(empId);注意:即使被引用的候选列不存在NULL值,在外键列中也允许NULL值。
以上定义的外键,当试图删除或更新被引用的相关数据时,如果在引用表中存在相关的行,则操作不能执行。这种情况可以通过定义具有级联操作的外键来解决,可在外键定义中将ON DELETE和ON UPDATE选项定义为CASCADE、SET DEFAULT和SET NULL之类的操作。
- CASCADE:操作被级联到引用表中相关的列
- SET DEFAULT / SET NULL:将引用表中相关行的外键属性设置为列的默认值或NULL
ALTER TABLE dbo.Employees
DROP CONSTRAINT FK_Employees_Employees
ALTER TABLE dbo.Employees
ADD CONSTRAINT FK_Employees_Employees
FOREIGN KEY(mgrId) -- 依然允许NULL值
REFERENCES dbo.Employees(empId)
ON DELETE CASCADE
ON UPDATE SET DEFAULT;检查约束 (Check)
检查约束用于定义在表中输入或修改一行数据之前必须满足的一个谓词。
以下的检查约束可以保证Employees表的salary列只支持正数:
ALTER TABLE dbo.Employees
ADD CONSTRAINT CHK_Employees_salary
CHECK(salary > 0);当谓词计算结果为TRUE或UNKNOWN时,RDBMS接受对数据行的修改,即NULL值会被接受。
默认约束 (Default)
默认约束与特定的属性关联。当插入一行数据时,如果没有为属性显式指定明确的值,就可以用一个表达式作为其默认值。
例如,以下代码为orderTs属性定义了一个默认约束(表示订单时间的时间戳):
ALTER TABLE dbo.Orders
ADD CONSTRAINT DFT_Orders_orderTs
DEFAULT(CURRENT_TIMESTAMP) FOR orderTs;CURRENT_TIMESTAMP函数返回当前的日期和时间值。
单表查询
先执行示例数据库脚本,构建一个示例数据库。
SELECT 语句的元素
USE TSQLFundamentals2008;
select empid, YEAR(orderdate) AS orderYear, count(*) AS numOrders
from Sales.Orders
where custid = 71
group by empid, YEAR(orderdate)
having count(*) > 1
order by empid, orderYear;各子句在逻辑上按以下顺序进行处理:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
因此,上述代码实际的处理顺序如下:
from Sales.Orders -- 查询数据行
where custid = 71 -- 保留客户ID = 71 的记录
group by empid, YEAR(orderdate) -- 按雇员ID和订单年份进行分组
having count(*) > 1 -- 保留具有多个订单的分组
select empid, YEAR(orderdate) AS orderYear, count(*) AS numOrders -- 返回指定行
order by empid, orderYear -- 按指定顺序对输出结果进行排序分隔标识符名称:
如果标识符是非常规的(例如名称中嵌入了空格或其他特殊字符、以数字开头、或是SQL Server的保留字),就必须分隔这样的标识符。ANSI SQL分隔标识符的标准格式是使用双引号(例如,“Order Details”)。SQL Server的特殊格式是使用方括号([Order Details])。
WHERE 子句
WHERE子句对查询性能有重要影响。在过滤表达式的基础上,SQL Server会计算使用什么索引来访问请求的数据。通过使用索引,有时可以大幅减少SQL Server在获取请求的数据时付出的代价。
要实可记住T-SQL使用的是三值谓词逻辑(TRUE, FALSE, UNKNOWN)。如果WHERE阶段要返回结果为TRUE的行,UNKNOWN也不会被返回。
GROUP BY 子句
所有的聚合函数都会忽略NULL值,除了COUNT(*)。
例如,假设一个组有5行,其qty列的值分别为30、10、NULL、10、10。COUNT(*)返回5,COUNT(qty)返回4,COUNT(DISTINCT qty)返回2;
SELECT 子句
当表达式中进行了一定的处理(例如,YEAR(orderDate)),或者没有基于原始表的列(如调用CURRENT_TIMESTAMP函数),这时如果不为表达式起一个别名,查询的结果集中就不能拥有列名。在某些情况下,T-SQL允许查询返回没有名称的结果集列,但关系模型不允许这样。因此强烈推荐将诸如YEAR(orderDate)之类的表达式起一个别名。
除了<表达式> AS <别名>这种格式,T-SQL还支持<别名> = <表达式>,和<表达式> <别名>这两种格式,后者非常不明确,避免使用这种定义别名的方式。
由于SELECT字句是在FROM、WHERE、GROUP BY,以及HAVING子句之后处理。这意味着在SELECT子句中为表达式分配的别名,在SELECT子句之前处理的那些子句中并不存在。
以下就是在WHERE子句中使用这种无效引用的一个例子:
SELECT orderId, YEAR(orderDate) AS orderYear
FROM Sales.Orders
WHERE orderYear > 2006;解决这一问题的一种方法就是在WHERE子句和SELECT子句中重复使用表达式YEAR(orderDate),SQL Server能够标识在查询中重复使用的同一表达式,因此,表达式其实只会被计算一次。
除了很少数的例外,在绝大多数情况下,使用星号*是一种糟糕的编程习惯。建议即使需要被查询表的所有列,也应该显式地指定它们。虽然使用星号时,为了解析列名需要付出一些额外的代价,但重要的问题在于查询过程中无法察觉到的代价,前者的代价反而显得微不足道。
在SELECT子句中不能引用当前SELECT子句中创建的别名列,例如:
SELECT orderId, YEAR(orderDate) AS orderYear, orderYear + 1 AS nextYear
FROM Sales.Orders;如前所述,解决这一问题的方法就是重复使用表达式(虽然繁琐,但这就是SQL…)。
ORDER BY 子句
带有ORDER BY 子句的查询会产生一种ANSI称之为游标(cursor)的结果(一种非关系结果,其中的行有固定的顺序)。
在SQL中的某些语言元素和运算预期只对查询的表结果进行处理,而不能处理游标,例如表表达式和集合运算。
下例中的查询,按照雇员ID和顶顶那年份对输出结果进行排序:
SELECT empid, YEAR(orderDate) AS orderYear, COUNT(*) AS numOrders
FROM Sales.Orders
WHERE custId = 71
GROUP BY empid, YEAR(orderDate)
ORDER BY empId, orderYear;可见,ORDER BY 子句成功引用了SELECT子句中的别名列orderYear——可知ORDER BY子句是在SELECT阶段之后被处理的。
SQL和T-SQL都支持在ORDER BY子句中指定表示该列名称或别名在SELECT列表中所处位置的非负整数。
上述代码的GROUP BY empId, orderYear也可以写成GROUP BY 1, 2,但这是一种糟糕的方式。首先,在关系模型中,属性本身没有顺序位置,要通过名称来引用它们。其次,当修改SELECT子句时,可能会忘记对ORRDER BY 子句中的引用位置做相应的修改。
T-SQL支持在ORDER BY子句中指定没有在SELECT子句中出现过的元素,例如,如下查询按照雇佣日期对雇员行进行排序,但最后并没有返回hireDate列:
SELECT empId, firstName, lastName, country
FROM HR.Employees
ORDER BY hireDate;当指定了DISTINCT以后,ORDER BY子句就只能选取在SELECT列中出现的元素。因为当指定DISTINCT时,一个结果行可能代表多个原始行,因此无法判断应该使用ORDER BY列表值中多个可能值中的哪一个。
TOP 选项
TOP选项是T-SQL特有的,用于限制查询返回的行数或百分比。当在查询中指定了ORDER BY子句时,TOP将依赖该子句来定义行的逻辑优先顺序。例如,从Orders表返回最近的5个订单的代码如下:
SELECT TOP (5) orderId, orderDate, custId, empId
FROM Sales.Orders
ORDER BY orderDate DESC;从逻辑查询处理的角度来看,TOP选项是作为SELECT阶段的一部分而处理,紧接着DISTINCT子句处理之后。当查询中指定了TOP以后,ORDER BY子句就起到了双重作用。首先,作为SELECT处理阶段一部分的TOP选项要依靠ORDER BY子句先为各个行定义它们的逻辑优先顺序,在此基础上再去过滤其他请求。其次,作为SELECT处理阶段之后的ORDER BY阶段,与为了展示数据而行进行排序的ORDER BY子句完全一样。
当使用TOP时,同一ORDER BY子句既担当了为TOP决定行的逻辑优先顺序的角色,也担当了展示数据的常规角色,最终生成的结果由表变成了具有固定顺序的游标。
在TOP选项中可以使用PERCENT关键字,SQL Server会按照百分比来计算应该返回的满足条件的行数(向上取整)。例如,以下查询请求最近更新过的前1%(向上取整)个订单:
SELECT TOP (1) PERCENT orderId, orderDate, custId, empId
FROM Sales.Orders
ORDER BY orderDate DESC;由于orderDate 的取值不是唯一的,具有相同订单日期的行之间的优先关系没有定义,这会让查询结果具有不确定性,多个查询结果都可以认为是正确的。SQL Server只是根据物理上最先访问到了哪行,就选择相应的行。如果想让查询结果是确定的,就要让ORDER BY列表能唯一地决定一行。
除了在ORDER BY列表增加额外的属性,还可以请求返回所有与TOP n行中最后一行具有相同结果的行,为此必须增加一个WITH TIES选项。
SELECT TOP (5) WITH TIES orderId, orderDate, custId, empId
FROM Sales.Orders
ORDER BY orderDate DESC;OVER 子句
OVER子句用于为行定义一个窗口(window),以便进行特定的运算,可以把行的窗口简单地认为是运算将要操作的一个行的集合。聚合函数和排名函数都是可以支持OVER子句的运算类型,由于OVER子句为这些函数提供了一个行的窗口,所以这些函数也称之为开窗函数(window function)。
聚合函数传统上一直以GROUP BY查询作为操作的上下文,聚合开窗函数使用OVER子句提供的窗口作为上下文,对窗口中的一组值进行操作。这样就能在不进行分组的情况下,在同一行中同时返回基础行的列和聚合列。
带有空的圆括号的OVER子句会提供所有行进行计算,这里的所有行是在FROM、WHERE、GROUP BY以及HAVING处理阶段完成后仍然可用的行。注意:只有在SELECT和ORDER BY处理阶段才允许使用OVER子句。
如果想对行进行限制或分区,可以使用PARTITION BY子句。例如,想返回当前客户(和当前行具有相同custId(某属性)的所有行)的总价格,则可以指定SUM(val) OVER(PARTITION BY custId)。
SELECT orderId, custId, val,
SUM(val) OVER() AS TTLvalue,
SUM(val) OVER(PARTITION BY custId) AS custTTLvalue
FROM Sales.OrderValues;OVER子句还可以在表达式中混合使用基本列和聚合值列。例如,以下查询为OrderValues的每一行计算当前价格占总价格的百分比,以及当前价格占客户总价格的百分比:
SELECT orderId, custId, val,
100. * val / SUM(val) OVER() AS pctAll,
100. * val / SUM(val) OVER(PARTITION BY custId) AS pctCust
FROM Sales.OrderValues;表达式中使用的是十进制实数100.,这样可以隐式地将整数值val和SUM(val)转换成十进制实数值。
OVER子句也支持四种排名函数:
- ROW_NUMBER 行号
- RANK 排名
- DENSE_RANK 密集排名
- NTILE
SELECT orderId, custId, val,
ROW_NUMBER() OVER(ORDER BY val) AS rowNum,
RANK() OVER(ORDER BY val) AS rank,
DENSE_RANK() OVER(ORDER BY val) AS dense_rank,
NTILE(10) OVER(ORDER BY val) AS ntile
FROM Sales.OrderValues
ORDER BY val;ROW_NUMBER函数用于为查询的结果集中的各行分配递增的序列号,即使行的排序值相同,也会生成唯一的行号值,如果ORDER BY不能唯一确定行的顺序,查询可能会返回多个正确的结果。如果想对排序值中的相同值以同样的方式处理,可以考虑使用RANK或DENSE_RANK函数。
RANK和DENSE_RANK与ROW_NUMBER类似,但它们为具有相同逻辑排序值的所有行生成同样的排名。RANK和DENSE_RANK的区别是:RANK表示之前有多少个具有更低的排序值的行,而DENSE_RANK则表示之前有多少个更低的排序值(这正是该函数被称为密集排名的原因)。
NTILE函数可以把结果中的行关联到组(title,相当于由行组成的指定数目的组**),并为每一行分配一个所属的组的编号。NTILE函数接受一个表示组的数量的参数,并要在OVER子句中指定逻辑顺序**。上述的查询例子有830行,请求将其分成10组,因此组的大小就是83。
NTILE函数在逻辑上需要依赖于ROW_NUMBER函数,整个过程是先根据对val的排序结果,为每一行分配行号;再基于前面计算好的组的大小83行,将第1行到第83行分配到第1组,以此类推。如果组数无法整除行数,余数会被一一分配到前面的每个组。例如,假设有102行,请求分成5组,那么前两组将有21行。
OVER子句中指定的ORDER BY逻辑与数据展示没什么关系,不会改变查询结果表最终的任何内容。如果在SELECT处理阶段指定了开窗函数,开窗计算会在DISTINCT子句之前进行处理(TOP选项是紧接着DISTINCT处理之后)。
总结目前位置讨论过的所有子句的逻辑处理顺序:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- OVER
- DISTINCT
- TOP
- ORDER BY
谓词和运算符
T-SQL支持的谓词包括IN、BETWEEN以及LIKE等。
- BETWEEN这个谓词用于检查一个值是否在指定的范围内,包括两个指定的边界值。
- LIKE这个谓词用于检查一个字符串是否与指定的模式匹配。例如,如下查询返回lastName以字符D开头的所有雇员:
字符串’D%’前面的字母N代表National,用于表示Unicode数据类型(NCHAR或NVARCHAR),与之对应的是常规的字符数据类型(CHAR或VARCHAR)。因为lastName字段的数据类型是NVARCHAR(40),所以就要在字符串前面加个字母N。SELECT empId, firstName, lastName FROM HR.Employees WHERE lastname LIKE N'D%';
CASE 表达式
CASE表达式是一个标量表达式,它基于条件逻辑来返回一个值。CASE表达式不能被用于控制活动的流程,也不能根据条件逻辑来做某些处理。相反,它只是根据条件逻辑来返回某个值。因为CASE是一个标量表达式,所以它支持任何标量表达式(如SELECT、WHERE、HAVING以及ORDER BY子句)、CHECK约束等。
CASE表达式有两种格式:简单表达式和搜索表达式。
简单表达式
CASE简单格式将一个值(或一个标量表达式)与一组可能的取值进行比较,并返回第一个匹配的结果。如果列表中没有值等于测试值,CASE表达式就返回其ELSE子句中列出的值。如果没有ELSE子句,则默认将其视为ELSE NULL。
例如,以下对Production.Products表的查询就在SELECT子句中使用了CASE表达式,以生成用于描述categoryId列取值的信息:
SELECT productId, productName, categoryId,
CASE categoryId
WHEN 1 THEN 'Beverages'
WHEN 2 THEN 'Condiments'
WHEN 3 THEN 'Confections'
ELSE 'Unknown Category'
END AS CategoryName
FROM Production.Products;除非商品种类的数量非常少,而且也是静态的,否则最好的设计选择可能是应该在另一个单独的表中来维护商品种类,当需要获取种类描述时,把那个表和Products进行连接join。事实上,TSQLFundamentals2008本身提供了一个这样的Categories表。
作为CASE简单表达式的另一个演示,以下对Sales.OrderValues视图的查询先根据val的逻辑顺序生成3个组,再把组的编号翻译成组的描述信息(Low、Medium和High);
SELECT orderId, custId, val,
CASE NTILE(3) OVER(ORDER BY val)
WHEN 1 THEN 'Low'
WHEN 2 THEN 'Medium'
WHEN 3 THEN 'High'
ELSE 'Unknown'
END AS titleDesc
FROM Sales.OrderValues
ORDER BY val;CASE简单表达式只有一个测试值(或表达式),它紧跟在CASE关键字后面,与WHEN子句中的一组可能值进行比较。
搜索表达式
CASE 搜索表达式更灵活,它可以在WHEN子句中指定谓词或逻辑表达式,而不限于只进行相等性比较。CASE搜索表达式返回结果为TRUE的第一个WHEN逻辑表达式所关联的THEN子句中指定的值。如果没有任何WHEN表达式结果为TRUE,CASE表达式就返回ELSE子句中出现的值(如果没有指定ELSE子句,则返回NULL)。
例如,以下查询根据商品的价格是否小于1000.00、在1000.00到3000.00之间、或者大于3000.00而生成相应的价格描述:
SELECT orderId, custId, val,
CASE
WHEN val < 1000.00 THEN 'Less then 1000'
WHEN val BETWEEN 1000.00 AND 3000.00 THEN 'Between 1000 and 3000'
WHEN val > 3000.00
ELSE 'Unknown'
END AS valueCategory
FROM Sales.OrderValues;每个CASE简单表达式都可以转换成CASE搜索表达式,但并非所有情况都有必要使用CASE搜索表达式。
NULL值
如果逻辑表达式只涉及已经存在的值,那么最终的计算结果就是TRUE/FALSE。但是当逻辑表达式涉及缺少的值时,其计算结果就是UNKNOWN。例如考虑谓词salary > 0:当salary是NULL时,表达式的计算结果为UNKNOWN。
在不同的语言元素中,SQL对UNKNOWN的处理也有所不同。
- SQL对查询过滤条件处理的正确定义是:“接受TRUE”就意味着要过滤掉FALSE和UNKNOWN。
- SQL对CHECK约束处理的正确定义是:“拒绝FALSE”就意味着接受TRUE和UNKNOWN。
UNKNOWN的一个微妙之处是,当对它取反时,结果仍然是UNKNOWN。对两个NULL值进行比较的表达式NULL = NULL,其计算结果也是UNKNOWN。因为NULL值代表一个缺少或不可知的值,所以无法判断,因此SQL提供了两个谓词:IS NULL和IS NOT NULL来取代= NULL和!= NULL。
在用于比较和排序目的的不同语言元素中,SQL处理NULL的方式也有所不同。一些元素认为两个NULL值相等,另一些认为不等。
例如,分组和排序时,认为两个NULL值相等。至于排序时,NULL值应该排在有效值之前还是之后,ANSI SQL把它留给了具体的产品实现。T-SQL把NULL值排在了有效值之前。但可以通过在ORDER BY阶段通过CASE表达式,手工更改NULL值的排序:
ORDER BY (CASE WHEN xxx IS NULL THEN 1 ELSE 0 END);ANSI SQL有两种UNIQUE约束:
- 将多个NULL值视为相等的
- 将多个NULL值视为不同的
SQL Server只实现了前者。
同时操作 (All-At-Once Operation)
SQL支持一种所谓的同时操作的概念,认为在同一逻辑查询处理阶段中出现的所有表达式都是同时进行计算的。
SELECT orderId, YEAR(orderDate) AS orderYear,
orderYear + 1 AS nextYear
FROM Sales.Orders;以上SELECT列表中第三个表达式对第二列orderYear这一列别名的引用是无效的,因为从逻辑上来说,SELECT列表中各表达式的计算是没有顺序的,所有表达式都在同一时刻进行计算。
再如下方的查询语句:
SELECT col1, col2
FROM dbo.T1
WHERE col1 != 0 AND col2 / col1 > 2;如果表达式col1 != 0的结果为FALSE,SQL Server将会按照**短路求值原则(short-circuit),停止计算这个表达式。
因为ANSI SQL中有同时操作这一概念,所以SQL Server可以按它喜欢的任意顺序来自由处理WHERE子句中的表达式**。SQL Server通常是基于代价估计的标准来做决定,即通常先计算需要付出较小代价的表达式。为了尽可能避免查询执行失败,可以采用简单的数学办法避免除数为0的错误:
SELECT col1, col2
FROM dbo.T1
WHERE col1 != 0 and col2 > 2 * col1;处理字符数据
排序规则 (Collation)
排序规则封装了几个方面的特征,包括多语言支持(和Unicode类型有关)、排序规则、区分大小写、区分重音等。要得到系统中目前支持的所有排序规则及其描述,可以查询表函数fn_helpcollations,如下所示:
SELECT name, description
FROM sys.fn_helpcollations();例如排序规则Latin1_General_CI_AS:
- Latin1_Genral 表示支持的语言是英语
- 排序规则名称中没有显式地出现BIN元素,则默认使用字典排序(不区分大小写)
- CI 表示不区分大小写(Case Insensitive)
- AS 表示区分重音(Accent Sensitive)
可以在4种不同的级别上定义排序规则:
- SQL Server实例
- 数据库
- 列
- 表达式
最低级的排序规则是比较有效的一种定义方式。
- SQL Server实例的排序规则是在安装时设置的。它决定了所有系统数据库的排序规则,同时也是用户数据库默认使用的排序规则。
- 创建用户数据库时,可以使用COLLATE子句指定数据库的排序规则。数据库的排序规则决定了数据库中对象元数据的排序规则,同时也是用户表列默认使用的排序规则。
如果数据库的排序规则区分大小写,则可以同时创建两个列为T1和t1的表 。 - 在定义列时,可以使用COLLATE子句显式地指定它的排序规则。
- COLLATE子句也可以修改表达式的排序规则。
例如,在不区分大小写的环境中,在查询中使用区分大小写的比较:SELECT empId, firstName, lastName FROM HR.Employees WHERE lastName COLLATE Latin1_General_CS_AS = N'davis';
数据类型
SQL Server支持两种字符数据类型:普通字符和Unicode字符。普通字符数据类型包括CHAR和VARCHAR,Unicode字符数据类型包括NCHAR和NVARCHAR。普通字符使用一个byte来保存每个字符,Unicode字符需要两个byte。一个列所支持的语言由列的有效排序规则(collation)属性决定。
- 在排序规则为Latin1_General_CS_AS等规则时:
普通字符类型由于一个列只用一个byte来保存每个字符,所以就限制在这个列中只能使用英语。
当使用Unicode字符类型时,可以表示所有语言,表示字符常量时,需要在单引号前指定一个字符N:N'Unicode字符'。 - 在排序规则为Chinese_PRC_CI_AS等规则时:
中文也能直接保存在VARCHAR类型中,且无需通过在单引号前指定一个字符N。
名称中不包含VAR元素的任何数据类型都是固定长度的(CHAR, NCAHR),SQL Server会按照为列定义的大小,在行中为该列留出固定的空间。因为当需要扩展字符串时,在行中无法进行扩展,所以固定长度的数据类型更适合以写入为主的系统。但因为这种类型的存储消耗不是最优的,所以在读取数据时可能要付出更多的代价。
名称中含有VAR元素的数据类型是可变长度的(VARCHAR, NVARCHAR),SQL Server在行中会按字符串的实际长度来保存数据,外加两个额外的字节以保存数据的偏移值(o)。例如,如果将一个列定义为VARCHAR(25),意味着它应该最多支持25个字符,在实际使用中,存储空间由实际的字符数量决定。与固定长度类型相比,可变长度类型小号的存储空间更少,所以读操作会更快。但是,更新数据时可能需要对行进行扩展,导致数据移动,超出当前页的范围,因此更新效率有所降低。
在定义可变长度的数据类型时,可以使用MAX说明符,而不必指定字符的最大数量。当使用MAX说明符(VARCHAR(MAX))时,可以把一个值直接保存到行的内部,长度具有一定上限(默认8000字节)。大小超过该上限的值将作为大型对象(LOB, Large OBject),保存在行的外部。
引号分隔的标识符
在标准SQL中,单引号''用于分隔文字字符串,如果单引号是文字字符串的一部分,则需要两个单引号表示。如字符串abc’de,应该写成abc''de';
双引号""用于分隔不规则的标识符(表名或列名包含空格或以数字开头(Java标识符只能以字母、下划线_、$开头,因此,尽量多语言保持统一))。在SQL Server中,有一个QUOTED_INDENTIFIER的设置选项,用于控制双引号的含义。可以在数据库级应用这个设置选项(ALTER DATABASE命令),也可以在会话级应用这个设置选项(SET命令)。当打开这个设置时,双引号的作用符合标准SQL的规定,仅用于分隔标识符。强烈建议遵循该标准SQL规定,大多数数据库接口(包括OLEDB和ODBC)都默认将该选项设置为ON。(SQL Server还支持用方括号[]作为分隔符)。
运算符和函数
字符串串联运算符(加号+)
T-SQL提供了加号+运算符,可以将两个或多个字符串合并或串联成一个字符串。
例如,以下对Employees表的查询将雇员的firstName列、一个空格,以及lastName列串联,生成完整的姓名fullName列:
SELECT empId, firstName + N' ' + lastName AS fullName
FROM HR.Employees;ANSI SQL规定对NULL值执行字符串串联运算,也会产生NULL值的结果。要用空字符串来替换NULL,可以使用COALESCE函数。该函数接受一系列参数,返回其中第一个不为NULL的值。
SELECT custId, country, region, city,
country + N', ' + COALESCE(region, N'') + N',' + city AS location
FROM Sales.Customers;SUBSTRING 函数
SUBSTRING函数用于从字符串中提取子串。SUBSTRING(string, start, length)
该函数提取从指定位置开始,指定长度的子字符串。例如如下代码返回字符串abc:SELECT SUBSTRING('abcde', 1, 3);
如果第二个参数和第三个参数的和超过了输入字符串的长度,则返回从起始位置开始直到字符串结尾的子字符串,不会引发错误。
LEFT 和 RIGHT 函数
LEFT 和 RIGHT 函数是SUBSTRING 函数的简略形式,它们分别返回字符串中从左边或右边开始,指定长度的子字符串。LEFT(string, length), RIGHT(string, length)
例如如下代码返回字符串’cde’:
SELECT RIGHT('abcde', 3);
LEN 和 DATALENGTH 函数
LEN函数返回字符串的长度,该函数返回的是字符数,而不一定是其字节数。如果要得到字节数,则应该使用DATALENGTH函数。
LEN和DATALENGTH函数的另一个区别是:前者不包含尾随空格(开头或中间的空格都会被计算),而后者包含。
- 在排序规则为Chinese_PRC_CI_AS等规则时,用DATALENGTH函数获取VARCHAR类型的字符数据时,会根据字符实际属于普通字符还是Unicode字符来返回字节数。
CHARINDEX 函数
CHARINDEX 函数返回字符串中某个子串第一次出现的起始位置。CHARINDEX(substring, string [, start_pos])
该函数在第二个参数中搜索第一个参数,并返回其起始位置。可以选择性地指定第三个参数,以便告诉这个函数从字符串的什么位置开始搜索,如果未指定,则从字符串的第一个字符开始搜索。
如果在string中找不到substring,则CHARINDEX返回0。例如,以下代码在’Itzik Ben-Gan’中查找第一个空格的位置,结果将返回6:
SELECT CHARINDEX(' ', 'Itzik Ben-Gan');
PATINDEX 函数
PATINDEX函数返回字符串中某个模式第一次出现的起始位置。PATINDEX(pattern, string)
参数pattern使用的模式与T-SQL中LIKE谓词使用的模式类似,目前还没有解释在T-SQL中如何表示模式,先用以下例子演示怎么在字符串中找到第一次出现数字的位置:SELECT PATINDEX('%[0-9]%', 'abcd123efgh');
这段代码返回的结果是5。
REPLACE 函数
REPLACE函数将字符串中出现的所有某个子串替换为另一个字符串。REPLACE(string, substring1, substring2)
可以使用REPLACE函数来计算字符串中某个字符出现的次数。为此,先将字符串中所有的那个字符串替换为空字符串,再计算字符串的原始长度和新长度的差值。例如,以下查询返回每个雇员的lastName列中字符’e’出现的次数:
SELECT empId, lastName,
LEN(lastName) - LEN(REPLACE(lastName, 'e', '')) AS numOccur
FROM HR.Employees;REPLICATE 函数
REPLICATE函数以指定的次数复制字符串值。REPLICATE(string, n)
例如,以下代码将字符串’abc’复制3次,返回字符串’abcabcabc’:SELECT REPLICATE('abc', 3);
下面这个例子显示了REPLICATE函数、RIGHT函数和字符串串联的用法:
对Production.Suppliers的查询为每个供应商的整数ID生成一个10位数的字符串表示(**不足10位时,前面补0):
SELECT supplierId,
RIGHT(REPLICATE('0', 9) + CAST(supplierId AS VARCHAR(10)), 10) AS strSupplierId
FROM Production.Suppliers;STUFF 函数
STUFF函数可以先删除字符串中指定长度的子串,再插入一个新的字符串作为替换。STUFF(string, pos, delete_length, insertString)
从参数pos指定的位置开始删除delete_length长度的字符,然后将insertString参数指定的字符串插入到pos指定的位置。例如,以下代码对字符串’xyz’进行处理,删除掉其中的第二个字符,再插入字符串’abc’:SELECT STUFF('xyz', 2, 1, 'abc');
这段代码的输出是’xabcz’。
UPPER 和 LOWER 函数
RTRIM 和 LTRIM 函数
RTRIM 和 LTRIM 函数用于删除字符串中的尾随空格或前导空格。
RTRIM(string), LTRIM(string)
LIKE 谓词
T-SQL提供了LIKE谓词,用于检查字符串是否能够匹配指定的模式。
通配符 wildCard
%(百分号)通配符_(下划线)通配符[<字符列>]通配符
方括号中包含一列字符(例如’[ABC]’),表示必须匹配列指定字符中的一个字符。
例如,以下查询返回lastName以字符A、B、C开头的所有雇员:SELECT empId, lastName FROM HR.Employees WHERE lastName LIKE N'[ABC]%';[<字符>-<字符>]通配符
方括号中包含一个字符范围(例如’[A-E]’),表示必须匹配指定范围内的一个字符。
例如,以下查询返回lastName以字符A到E开头的所有雇员:SELECT empId, lastName FROM HR.Employees WHERE lastName LIKE N'[A-E]%';[^<字符列或范围>]通配符
方括号中包含一个插入符^,跟着一个字符列或范围(例如’[^A-E]’),表示不属于指定字符列或范围内的任意单个字符。
例如,以下查询返回lastName不是以字符A到E开头的所有雇员:SELECT empId, lastName FROM HR.Employees WHERE lastName LIKE N'[^A-E]%';- ESCAPE(转义)字符
如果想搜索包含特殊通配符的字符串(如%、_、[、]),则必须使用转义字符。指定一个确保不会在数据中出现的字符作为转义字符,把它放在待查找的字符串前面,并紧接着模式字符串,在ESCAPE关键字后面指定该转义字符。例如,要检查一个名为col1的列中是否包含下划线,可以使用col1 LIKE '%!_%' ESCAPE '!'。
另外,对于通配符%、_、[,可以把它们放在方括号内而不必使用转义字符。例如:col1 LIKE '%[_]%'。
处理日期和时间数据
日期和时间数据类型
在SQL Server 2008之前,SQL Server支持两种表示时间的数据类型:DATETIME 和 SMALLDATETIME。这两种类型都包括了日期和时间组成部分,而且这两部分是不能分开的。SQL Server 2008引入了单独的DATE和TIME数据类型:
- DATETIME2——比DATETIME具有更大的日期范围和更好的精度
- DATETIMEOFFSET:具有一个时区组成部分
| 数据类型 | 存储大小(B) | 日期范围 | 准确度 | 推荐格式 |
|---|---|---|---|---|
| DATETIME | 8 | 1753-01-01 到 9999-12-31 | 3.33毫秒 | ‘YYYYMMDD hh:mm:ss.nnn’ |
| SMALLDATETIME | 4 | 1900-01-01 到 2079-06-06 | 1分钟 | ‘YYYYMMDD hh:mm’ |
| DATE | 3 | 0001-01-01 到 9999-12-31 | 1天 | ‘YYYY-MM-DD’ |
| TIME | 3 到 5 | 00:00:00.0000000 到 23:59.59.9999999 | 100纳秒 | ‘hh:mm:ss.nnnnnnn’ |
| DATETIME2 | 6 到 8 | 0001-01-01 00:00:00.0000000 到 9999-12-31 23:59:59.9999999 | 100纳秒 | |
| DATETIMEOFFSET | 8 到 10 | 0001-01-01 00:00:00.0000000 到 9999-12-31 23:59:59.9999999 | 100纳秒 | ‘YYYY-MM-DD hh:mm:ss.nnnnnnn [+ |
TIME、DATETIME2以及DATETIMEOFFSET的存储空间大小依赖于所选择的精度。可以通过0-7之间的整数来指定精度,分别代表不同小数位数的秒值的精度。例如TIME(0),SQL Server默认将精度设置为7。
字符串文字
SQL Server并没有提供表达日期和时间字符串的具体方法,它允许你指定不同类型的字符串文字,再将其(显式或隐式地)转换为相应的日期和时间数据类型:
SELECT orderId, custId, empId, orderDate
FROM Sales.Orders
WHERE orderDate = '20070212';隐式转换规则并不总是这么简单,其实在过滤器条件和其他表达式中应用的规则是不同的,当前处于讨论的目的,先让事情简单些。
强烈建议按照语言无关的方式来编写日期和时间字符串文字,这样SQL Server才能以相同的方式加以解释,而不受语言相关设置的影响。
| 数据类型 | 语言中立的格式 | 示例 |
|---|---|---|
| DATETIME | ‘YYYYMMDD hh:mm:ss.nnn’ ‘YYYY-MM-DDThh:mm:ss.nnn’ ‘YYYYMMDD’ |
‘20090212 12:30:15.123’ ‘2009-02-12t12:30:15.123’ ‘20090212’ |
| SMALLDATETIME | ‘YYYYMMDD hh:mm’ ‘YYYY-MM-DDThh:mm’ ‘YYYYMMDD’ |
‘20090212 12:30’ ‘2009-02-12T12:30’ ‘20090212’ |
| DATE | ‘YYYYMMDD’ ‘YYYY-MM-DD’ |
‘20090212’ ‘2009-02-12’ |
| DATETIME2 | ‘YYYYMMDD hh:mm:ss.nnnnnnnnn’ ‘YYYY-MM-DD hh:mm:ss.nnnnnnnnn’ ‘YYYY-MM-DDThh:mm:ss.nnnnnnnnn’ ‘YYYYMMDD’ ‘YYYY-MM-DD’ |
‘20090212 12:30:15.1234567’ ‘2009-02-12 12:30:15.1234567’ ‘2009-02-12T12:30:15.1234567’ ‘20090212 ‘ ‘2009-02-12’ |
| DATETIMEOFFSET | ‘YYYYMMDD hh:mm:ss.nnnnnnnnn [+|-]hh:mm’ ‘YYYYMMDD’ ‘YYYY-MM-DD’ |
‘20090212 12:30:15.1234567 +02:00’ ‘2009-02-12 12:30:15.1234567 +02:00’ ‘20090212 ‘ ‘2009-02-12’ |
| TIME | ‘hh:mm:ss.nnnnnnn’ | ‘12:30:15.1234567’ |
有两点要注意,对于所有包括日期和时间组成部分的类型,如果不在字符串文字中指定时间,SQL Server会默认将时间设置为午夜。如果不指定时区,SQL Server将采用00:00。
此外,要重点注意’YYYY-MM-DD’和’YYYY-MM-DD hh:mm…’格式,当转换到DATETIME或SMALLDATETIME类型时,它们是语言相关的;当转换到DATE、DATETIME2以及DATETIMEOFFSET时,它们是语言无关的。
例如,以下代码中,语言设置对于以’YYYYMMDD’格式表示的字符串文字如何转换为DATETIME类型的数据没有影响:
SET LANGUAGE British;
SELECT CAST('20070212' AS DATETIME);
SET LANGUAGE us_english;
SELECT CAST('20070212' AS DATETIME);优先使用类似’YYYYMMDD’这样语言无关的格式,再怎么强调也不为过。
如果你坚持要用与语言相关的格式来表示日期和时间字符串文字,则可以使用CONVERT函数,在它的第3个参数中指定一个表示正在使用的样式的数字,显式地将字符串文字转换成想要的数据类型。样式数字和各自代表的格式见:【Sqlserver系列】CAST和CONVERT。
例如,想指定字符串文字’02/12/2007’的格式为mm/dd/yyyy,可以使用样式号101,如果想采用dd/mm/yyyy的格式,可以使用样式号103:
SELECT CONVERT(DATETIME, '02/12/2007', 101); -- 按指定格式解读,转换成YYYY-MM-DD hh:mm...的格式
SELECT CONVERT(DATETIME, '02/12/2007', 103);单独使用日期和时间
SQL Server 2008引入了可以单独使用日期和时间部分的数据类型,但在前面的讨论中还没有区分这两部分。如果要在SQL Server 2008之前的版本中只是用日期或时间,只能选用同时包含这两种组成部分的DATETIME或SMALLDATETIME数据类型之一。在要实现日期和时间逻辑的地方,也可以使用整数或字符串之类的数据类型,但此处不讨论这种用法。如果选用DATETIME或SMALLDATETIME类型,当只使用日期数据时,保存数据的时间将是午夜零点;当只使用时间数据时,保存数据的日期值将是基础日期1900年1月1日。
例如Sales.Orders表的orderdate列是DATETIME类型的,但由于实际只使用日期部分,所以所有值的时间都存储成午夜了。当需要筛选特定日期的订单时,可以不使用范围过滤条件,只用等号运算符即可:
SELECT orderId, custId, empId, orderDate
FROM Sales.Orders
WHERE orderDate = '20070212';如果想在SQL Server 2008之前的版本中只使用时间,则可以用基础日期1900年1月1日来存储所有时间值。当SQL Server把只包含时间值的字符串文字转换成DATETIME或SMALLDATETIME类型时,它会默认使用基础日期。
如果输入值既包括日期也包括时间,当只想使用日期时,就把时间部分设置成午夜;如果只想使用时间,就把日期部分设置成基础日期。在后面的日期和时间函数一节中,将会介绍实现这种效果的一种简单方法。
过滤日期范围
如果要过滤日期范围(比如,整年或整月),比较自然的方法就是使用YEAR和MONTH之类的函数。不过要小心一点,在大多数情况下,对过滤条件中的列应用了一定的处理后,就不能以有效的方式来使用索引了,相关主题超出了当前的讨论范围。但就目前而言,只要记住以下通用原则:为了潜在地有效利用索引,就需要对谓词进行调整,而不对过滤条件中的列进行处理。
例如:
SELECT orderId, custId, empId, orderDate
FROM Sales.Orders
WHERE orderDate >= '20070101' AND orderDate < '20080101'; -- 筛选2007年的所有订单类似地,不应该使用函数来过滤某个月生成的订单,如下所示:
SELECT orderId, custId, empId, orderDate
FROM Sales.Orders
WHERE YEAR(orderDate) = 2007 AND MONTH(orderDate) = 2;而应该使用一个范围过滤条件:
SELECT orderId, custId, empId, orderDate
FROM Sales.Orders
WHERE orderDate >= '20070201' AND orderDate < '20070301';日期和时间函数
以下不带参数的函数可以返回SQL Server实例所在系统的当前日期和时间:
| 函数 | 返回类型 | 描述 |
|---|---|---|
| GETDATE | DATETIME | 当前日期和时间 |
| CURRENT_TIMESTAMP | DATETIME | 与GETDATE相同,而且是ANSI SQL |
| GETUTCDATE | DATETIME | 以UTC格式表示的当前日期和时间 |
| SYSDATETIME | DATETIME2 | 当前日期和时间 |
| SYSUTCDATETIME | DATETIME2 | 以UTC格式表示的当前日期和时间 |
| SYSDATETIMEOFFSET | DATETIMEOFFSET | 当前日期和时间,包含时区偏移量 |
除了ANSI函数CURRENT_TIMESTAMP之外,不需要参数的函数在调用时都必须多加一对空的圆括号()。此外,因为CURRENT_TIMESTAMP和GETDATE返回的内容相同,但前者是标准SQL,所以推荐优先选用CURRENT_TIMESTAMP。
以下代码演示了取得当前日期和时间函数的用法:
SELECT
GETDATE() AS "GETDATE",
CURRENT_TIMESTAMP AS "CURRENT_TIMESTAMP",
GETUTCDATE() AS "GETUTCDATE",
SYSDATETIME() AS "SYSDATETIME";CAST 和 CONVERT 函数
CAST 和 CONVERT 函数用于转换值的数据类型。
CAST(value AS dataType)
CONVERT(dataType, value [, style_number]) 这两个函数都可以将输入的值转换为指定的数据类型。在一些情况下,还能用CONVERT提供的第三个参数来指定转换的样式(【Sqlserver系列】CAST和CONVERT)。
接下来用几个例子来演示如何用CAST和CONVERT函数来处理日期和时间数据类型。
SELECT CAST('20090212' AS DATE);
SELECT CAST(SYSDATETIME() AS DATE);
SELECT CAST(SYSDATETIME() AS TIME);
-- 使用样式值112('YYYYMMDD'),把当前日期和时间值转换为CHAR(8),再转换回DATETIME类型时,得到的当前日期的时间部分将是零点
SELECT CAST(CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112) AS DATETIME);
-- 使用样式值114('hh:mm:ss.nnn'),把当前日期和时间值转换为CHAR(12),再转换回DATETIME类型时,得到的当前时间的日期部分将是基础日期
SELECT CAST(CONVERT(CHAR(12), CURRENT_TIMESTAMP, 114) AS DATETIME);DATEADD 函数
DATEADD 函数可以将指定日期的部分作为单位,为输入的日期和时间值增加指定的数量(可以增加负数)。DATEADD(part, number, dt_val)
| part | 缩写 |
|---|---|
| year | yy, yyyy |
| quarter | qq, q |
| month | mm, m |
| dayofyear | dy, y |
| day | dd, d |
| week | wk, ww |
| weekday | dw, w |
| hour | hh |
| minute | mi, n |
| second | ss, s |
| millisecond | ms |
| microsecond | mcs |
| nanosecond | ns |
该函数返回值的类型与输入的日期和时间值的类型相同。如果输入的是一个字符串文字,输出的则是DATETIME。
例如:
SELECT DATEADD(year, 1, '20090212');返回的结果为DATETIME格式:2010-02-12 00:00:00.000
DATEDIFF函数
DATEDIFF返回后一个日期和时间值 - 前一个日期和时间值的指定部分的计数。
DATEDIFF(part, dt_vall, dt_val2)
例如,以下代码返回两个值之间相差的天数
SELECT DATEDIFF(dd, '20080212', '20090212'); -- 返回的输出是366在SQL Server 2008之前的版本中,可以用以下代码将当前系统日期和时间值中的时间部分设置为午夜:
SELECT DATEADD(dd, DATEDIFF(dd, '20010101', CURRENT_TIMESTAMP), '20010101');这段代码首先用DATEDIFF函数计算一个锚点日期的午夜值与当前日期和时间之间相差的总天数。接着,再用DATEADD函数为锚点日期增加上一步得到的天数。这样就可以得到当前系统日期在午夜的时间值。
有趣的是,如果在这个表达式中用month取代day来作为计数单位,并确保使用的锚点日期是某个月(任意年份和月份)的第一天,最后得到的结果将是当前月份的第一天:
SELECT DATEADD(mm, DATEDIFF(mm, '20010101', CURRENT_TIMESTAMP), '20010101')类似地,用year作为计数单位,并用某年的第一天作为锚点日期,最后得到的将是当前年的第一天。如果想要得到当前月或当前年的最后一天,只要简单地把锚点日期修改为月或年的最后一天(注意要选择月份最后一天为31天的日期,这样才能正确得到任意月份的最后一天)。例如:
SELECT DATEADD(mm, DATEDIFF(mm, '19991231', CURRENT_TIMESTAMP), '19991231');DATEPART 函数
DATEPART函数返回一个表示给定日期和时间值的指定部分的整数。
以下代码返回输入值的月份部分:
SELECT DATEPART(mm, '20210626'); -- 返回整数2,而不是02YEAR、MONTH 和 DAY 函数
YEAR、MONTH 和 DAY 函数是DATEPART函数的简略版本。
YEAR(dt_val)MONTH(dt_val)DAY(dt_val)
DATENAME 函数
DATENAME 函数返回一个表示给定日期和时间值的指定部分的字符串(这是依赖语言的)。
DATENAME(part, dt_val)
如果请求的部分没有名称,只是一个数字值(比如年份),则DATENAME函数将它的数字值作为字符串而返回。
SELECT DATENAME(mm, '20210626'); -- 如果当前会话的语言是某种英语(us_english, British),函数调用的返回值将是'February',默认的中文环境下会返回数字值**06**
SELECT DATENAME(yy, '20210626'); -- 返回2021ISDATE函数
ISDATE接受一个字符串作为输入,如果能把这个字符串转换为日期和时间数据类型的值,则返回1;否则返回0。
ISDATE(string)
SELECT ISDATE('20210627'); -- 返回1
SELECT ISDATE('20210229'); -- 返回0查询元数据
SQL Server提供了用于获取数据库对象的元数据信息的工具,比如数据库中有什么表,表中有什么列等。这些工具包括目录视图(catalog view)、信息架构视图(information schema view)、系统存储过程和函数。这里不准备介绍很多细节,而只是针对每个元数据工具给出几个例子,能有一个感性的认识,帮助学习。
目录视图
目录视图提供了关于数据库中各对象的非常详细的信息,包括SQL Server特定的信息。例如,如果想列出数据库中的各个表,以及它们的架构名称,按如下操作去查询sys.tables视图:
USE TSQLFundamentals2008;
SELECT SCHEMA_NAME(schema_id) AS table_schema_name, name AS table_name
FROM sys.tables;此处用SCHEMA_NAME函数把架构ID转换成它的名称。
要得到有关某个表的列信息,可以查询sys.columns表。例如,以下代码返回Sales.Orders表中的列信息,包括列名、数据类型(用TYPE_NAME函数把系统类型ID转换成类型名称)、最大长度、排序规则名称,以及是否允许为NULL。
SELECT name AS column_name, TYPE_NAME(system_type_id) AS column_type,
max_length, collation_name, is_nullable
FROM sys.columns
WHERE object_id = OBJECT_ID(N'Sales.Orders');在SSMS中,使用ALT+F1的快捷键,可以获得更详细的数据库对象信息。
信息架构视图
信息架构视图是位于INFORMATION_SCHEMA架构内的一组视图,它们以一种ANSI SQL标准的方式来提供元数据信息。
例如,以下对INFORMATION_SCHEMA.TABLES视图的查询可以列出当前数据库中的用户表,以及它们的架构名称:
SELECT TABLE_SCHEMA, TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE';以下对INFORMATION_SCHEMA.COLUMNS视图的查询提供了有关Sales.Orders表中各个列的绝大多数的可用信息:
SELECT COLUMN_NAME, DATA_TYPE, CHARATER_MAXIMUM_LENGTH,
COLLATION_NAME, IS_NULLABLE
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = 'Sales'
AND TABLE_NAME = 'Orders';这两个示例,达到了和上文目录视图示例相同的结果。
系统存储过程和函数
系统存储过程和函数是在其内部查询系统目录,并返回更加**”摘要化“的元数据信息**。
sp_tables存储过程返回可以在当前数据库中查询的对象(比如表和视图)列表:
EXEC sys.sp_tables;sp_help存储过程接受一个对象名称作为输入,返回与之相关的多个结果集,包含了有关对象的一般信息,以及关于列、索引、约束等对象的信息。
EXEC sys.sp_help @objname = 'Sales.Orders';在SSMS中,使用
ALT+F1的快捷键,获得相同结果。sp_columns存储过程返回对象中有关列的信息。
EXEC sys.sp_columns @table_name = 'Orders', @table_owner = 'Sales';sp_helpconstraint存储过程返回对象中关于约束的信息。
EXEC sys.sp_helpconstraint @objname = 'Sales.Orders';
还有一组函数可以返回关于数据库实体(如SQL Server实例、数据库、对象、列等等)的各属性的信息。
SERVERPROPERTY函数返回当前数据库实例的指定属性信息。
例如,以下代码返回当前数据库实例的版本级别(RTM、SP1、SP2等):
SELECT SERVERPROPERTY('ProductLevel');DATABASEPROPERTYEX函数返回指定数据库的特定属性的信息。
例如,以下代码返回TSQLFundamentals2008数据库的排序规则的当前设置:
SELECT DATABASEPROPERTYEX('TSQLFundamentals2008', 'collation');
连接查询
SQL Server 2008支持4种表运算符:
- JOIN
- APPLY(第5章)
- PIVOT(第7章)
- UNPIVOT(第7章)
JOIN是ANSI标准,而APPLY、PIVOT和UNPIVOT是T-SQL对标准的扩展,每种表运算符都以表作为输入,对表进行处理,经过一系列的逻辑查询处理阶段,最终返回一个结果表。
连接有3种基本类型:交叉连接、内连接和外连接。
交叉连接只有1个步骤:笛卡尔积;
内连接有2个步骤:笛卡尔积、过滤;
外连接有3个步骤:笛卡尔积、过滤、添加外部行。
逻辑查询处理描述了对于给定的任意查询,为了生成正确的结果而需要经历的一系列常规的逻辑步骤,而物理查询处理描述的则是RDBMS引擎如何实际处理查询。连接运算的一些逻辑查询处理步骤可能听起来并不高效,但可以对其物理实现进行优化。逻辑查询处理各步骤对输入表进行的操作是基于关系代数的,而数据库引擎没有必要严格遵守逻辑查询处理的步骤,只要可以保证最终生成的结果与逻辑查询处理描述的相同。出于优化的目的,SQL Server关系引擎经常会采用很多处理捷径。
交叉连接 (CROSS JOIN)
在逻辑上,交叉连接是一种最简单的连接,它只实现了一个逻辑查询步骤:笛卡尔积。如果一个表有$m$行,另一个表有$n$行,将得到$m\times n$行的结果集。
下面的查询是对数据库TSQLFundamentals2008中的Customers表和Employees表进行交叉连接查询,返回结果集中的custId和empId列:
USE TSQLFundamentals2008;
SELECT C.custId, E.empId
FROM Sales.Customers AS C
CROSS JOIN HR.Employees AS E;交叉连接生成的结果集是一个虚拟表,虚拟表中的各列直接源于参与连接的两个表。使用列名称前缀的目的是为了明确标识这些列,当没有具有歧义的列名时,列名前缀是可选的,但是为了明确起见,总是使用列名前缀是个好的习惯。
旧的交叉连接语法只需简单地在表名之间加个逗号,这两种语法在逻辑和性能上都没有区别,但CROSS JOIN语法能使代码结构更清晰。
自交叉连接
所有基本连接类型(交叉连接、内连接以及外连接)都支持自连接。
生成数字表
用交叉连接生成由一列整数组成地结果集非常方便,这样的数字序列在许多情况下都是非常有用的工具。
首先新建一个名为Digits的表,它只有一个名为digit的列,为表添加10行数据(从0到9):
USE tempdb;
IF OBJECT_ID('dbo.Digits', 'U') IS NOT NULL
DROP TABLE dbo.Digits;
CREATE TABLE dbo.Digits
(
digit INT NOT NULL PRIMARY KEY
);
INSERT INTO dbo.Digits(digit)
VALUES (0), (1), (2), (3), (4), (5), (6), (7), (8), (9);假设现在要写一个查询,生成从1到1000的整数序列。可以对Digits表的三个实例进行交叉连接,每个实例分别代表10的不同次幂(1, 10, 100)。为了生成真实的数字,把每个实例的数字乘以它所代表的10的幂,再把结果加起来,最后加1。
SELECT (D3.digit * 100 + D2.digit * 10 + D.digit + 1) AS n
FROM dbo.Digits AS D1
CROSS JOIN dbo.Digits AS D2
dbo.Digits AS D3
ORDER BY n;内连接 (INNER JOIN)
内连接要应用2个逻辑查询处理步骤:笛卡尔积、过滤。内连接是默认的连接方式,所以可以只单独指定JOIN关键字。
内连接的逻辑处理是在关系代数的基础上考虑的,首先对两个表求笛卡尔积,但后根据条件对行进行过滤。如前所述,这只是连接的逻辑处理方法,实际上数据库引擎对查询的物理处理可能会有所不同。
和交叉连接类似,内连接也可以通过在表名之间加个逗号来定义,但是INNER JOIN在某些方面更安全。假如你想写一条内连接查询,但不小心忘记指定连接条件,INNER JOIN的语法会报错,逗号的语法却仍然能执行。
特殊的连接实例
组合连接
组合连接就是连接条件涉及连接两边的多个列的查询。当需要根据主键-外键关系来连接两个表,而且主外键关系是组合的(关系基于多个列)时,通常就要使用组合连接。
假设现在要对TSQLFundamentals2008数据库的OrderDetails表中列值的更新进行审核,为此新建一个名为OrderDetailsAudit的客户审核表:
USE TSQLFundamentals2008;
IF OBJECT_ID('Sales.OrderDetailsAudit', 'U') IS NOT NULL
DROP TABLE Sales.OrderDetailsAudit;
CREATE TABLE Sales.OrderDetailsAudit
(
lsn INT NOT NULL IDENTITY,
orderId INT NOT NULL,
productId INT NOT NULL,
dt DATETIME NOT NULL,
loginName sysName NOT NULL,
columnName sysName NOT NULL,
oldVal SQL_VARIANT,
newVal SQL_VARIANT,
CONSTRAINT PK_OrderDetailsAudit PRIMARY KEY(lsn),
CONSTRAINT FK_OrderDetailsAudit_OrderDetails
FOREIGN KEY(orderId, productId)
REFERENCES Sales.OrderDetails(orderId, productId)
);每行审核记录保存一个日志序列号(lsn)、修改过的行的主键(orderId, productId)、修改过的列的名称(columnName)、更新前和更新后的值(oldVal, newVal)、更新发生时间(dt)、由谁进行的修改(loginName)。这个表有一个定义在orderId、productId两个列上的外键,用于引用OrderDetails表的主键(在其orderId, productId两个列上定义的主键)。
假设已经完成了所有必要的处理,将OrderDetails表中列值发生的变化都记录在了OrderDetailsAudit表中。现在要写一个查询,返回在OrderDetails表中qty列上发生的所有取值变化,而且在每个结果行中还要返回该列在OrderDetails表中的当前值,以及OrderDetailsAudit表中变化前后的值。这就要基于主键-外键关系对两个表进行连接如下:
SELECT OD.orderId, OD.productId, OD.qty,
ODA.dt, ODA.loginName, ODA.oldVal, ODA.newVal
FROM Sales.OrderDetails AS OD
INNER JOIN Sales.OrderDetailsAudit AS ODA
ON OD.orderId = ODA.orderId
AND OD.productId = ODA.productId
WHERE ODA.columnName = 'qty';因为关系是基于多个列的,所以连接条件也是组合的。
不等连接
如果连接条件包括除等号以外的其他运算符,这样的连接叫做不等连接。
多表连接
通常,当FROM子句中包含多个表运算符时,表运算符在逻辑上是按从左到右的顺序处理的。也就是说第一个表运算符的结果表将作为第二个表运算符的输入,第二个表运算符的结果作为第三个表运算符左边的输入,以此类推。所以如果FROM子句中包含多个连接,逻辑上只有第一个连接对两个基础表进行操作,而其他连接则将前一个连接的结果作为其左边的输入。当处理交叉连接和内连接时,为了优化的目的,数据库引擎能够(经常)对连接顺序进行内部调整。
外连接 (OUTER JOIN)
外连接会应用内连接所应用的两个逻辑处理步骤(笛卡尔积和ON过滤),还多一个:添加外部行。
在外连接中,要把一个表标记为”保留的“表,可以在表名之间使用关键字:
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
其中OUTER关键字是可选的。
LEFT关键字表示左边表的行是保留的,RIGHT关键字表示右边表的行是保留的,而FULL关键字则表示左右两边表的行都是保留的。外连接的第三个查询逻辑查询处理步骤就是要识别保留表中按照ON条件在另一个表找不到与之匹配的那些行,再把这些行添加到连接的前两个步骤生成的结果表中;对于来自连接的非保留表的那些列,追加的外部行中的这些列则用NULL作为占位符。
从外连接保留表的角度来看,可以认为外连接结果中的数据行包括两种:内部行和外部行。
使用外连接时,经常会为到底在查询的ON子句中,还是在WHERE子句指定连接条件而感到困惑。从外连接保留表中的行来考虑这个问题,ON子句中的过滤条件不是最终的。换句话说,ON子句中的条件并不能最终决定保留表中部分行是否会在结果中出现,而只是判断是否能够匹配另一边表中的某些行。所以,当需要表达一个非最终的条件时(即这个条件只决定哪些行可以匹配非保留表),就在ON子句中指定连接条件;当在生成外部行以后,要应用过滤器,而且希望过滤条件是最终的,就应该在WHERE子句中指定条件。WHERE子句是在FROM子句之后被处理的,即在处理完所有表运算符,生成了所有外部行以后。此外,与ON子句不同,对于行的过滤来说,WHERE子句是最终的。
以下查询根据客户的客户ID和订单的客户ID对Customer表和Orders表进行连接,并返回没有下任何订单的客户:
SELECT C.custId, C.companyName
FROM Sales.Customers AS C
LEFT JOIN Sales.Orders AS O
ON C.custId = O.custId
WHERE O.orderId IS NULL;
-- 该例子效果等同于如下代码
SELECT C.custId, C.companyName
FROM Sales.Customers AS C
INNER JOIN Sales.Orders AS O
ON C.custId = O.custId选择连接的非预留表中的哪个列作为过滤器也很重要,应该选择只在外部行才取值为NULL的某个列。为此,有3种情形可以考虑安全地使用:
- 主键列(不能为NULL)
- 连接列(如果为NULL,在ON过滤阶段就会被过滤掉)
- 定义为NOT NULL的列
外连接的高级主题
包含缺少值的数据
在查询数据时,可以用外连接来识别和包含缺少的值(即NULL值)。例如,假设现在需要查询TSQLFundamentals2008数据库Orders表的所有订单,要确保对于2006年1月1日到2008年12月31日之间的每个日期至少在输出结果中出现一行。
为了解决这个问题,可以先写一条查询语句返回要求的日期范围内的所有日期序列。再对这个日期集和Orders表执行一个左连接操作。这样就可以在结果中包含没有订单的日期。
那么,如何生成指定范围的日期序列?可以使用一个由数字组成的辅助表。新建一个名为Nums的表,其中包含一个名为n的列,并将这个列的值初始化为整数序列(1, 2, 3, …)。由数字组成的辅助表是一个功能非常强大的通用工具,最终能帮助我们解决很多问题。只需要在数据库中创建一次这样的表,然后用足够数量的数字来填充这个表。
如下代码,在dbo架构中创建Nums表,并为其填充100_000行数据:
SET NOCOUNT ON;
USE TSQLFundamentals2008;
IF OBJECT_ID('dbo.Nums', 'U') IS NOT NULL
DROP TABLE dbo.Nums;
CREATE TABLE dbo.Nums
(
n INT NOT NULL PRIMARY KEY -- 在创建表时,添加主键的方式
);
DECLARE @i INT = 1;
BEGIN TRAN -- 事务
WHILE @i <= 100000
BEGIN
INSERT INTO dbo.Nums VALUES(@i);
SET @i = @i + 1;
END
COMMIT TRAN
SET NOCOUNT OFF;作为解决方案的第一步,要生成指定范围内的所有日期序列。为此,可以先查询Nums表,筛选出与请求日期范围内的天数一样多个整数;再用DATEDIFF函数计算与每个整数对应的日期:
SELECT DATEADD(dd, n-1, '20060101') AS orderDate -- 转化为日期
FROM dbo.Nums
WHERE n <= DATEDIFF(dd, '20060101', '20090101') -- 所需天数
ORDER BY orderDate;最终一条龙的写法:
SELECT DATEADD(dd, Nums.n - 1, '20060101') AS orderDate,
O.orderId, O.custId, O.empId
FROM dbo.Nums
LEFT JOIN Sales.Ordes AS O
ON DATEADD(dd, NUms.n - 1, '20060101') = O.orderDate
WHERE Nums.n <= DATEDIFF(dd, '20060101', '20090101')
ORDER BY orderDate;在多表连接中使用外连接
回想第二章单表查询中同时操作(all-at-once operation)的概念(在同一逻辑查询处理阶段中出现的所有表达式都是同时进行计算的)。这个概念对FROM子句处理阶段中表运算符的处理并不适用。一些有趣的逻辑错误通常与外连接的逻辑处理顺序有关。例如,考虑以下查询语句:
SELECT C.custId, O.orderId, OD.productId, OD.qty
FROM Sales.Customers AS C
LEFT JOIN Sales.Orders AS O
ON C.custId = O.custId
INNER JOIN Sales.OrderDetails AS OD
ON O.orderId = OD.orderId;第一个连接是外连接,返回客户和他们的订单,包括没有下过订单的客户,但第二个连接会将没有下过订单的客户过滤掉。这个问题可以概括为:对于任何外连接,如果后面紧跟着一个内连接或右外连接,且连接条件对来自连接左边的NULL值和连接右边的某些值进行了比较,会抵消掉外连接的外部行。
如果想在输出结果中返回没有订单的客户,有基中变通的方法能够绕过这个问题:
在第二个连接中也使用左外连接:
SELECT C.custId, O.orderId, OD.productId, OD.qty FROM Sales.Customer AS C LEFT JOIN Sales.Orders AS O ON C.custId = O.custId LEFT JOIN Sales.OrderDetails AS OD ON O.orderId = OD.orderId;先用内连接来连接Orders表和OrderDetails表,然后用右外连接来连接Customers表:
SELECT C.custId, O.orderId, OD.productId, OD.qty FROM Sales.Orders AS O INNER JOIN Sales.OrderDetails AS OD ON O.custId = OD.custId RIGHT JOIN Sales.Customer AS C ON O.orderId = C.orderId;把Orders表和OrderDetails表之间的内联用一对圆括号括起来,使其成为一个独立的逻辑处理语句:
SELECT C.custId, O.orderId, OD.productId, OD.qty FROM Sales.Customer AS C LEFT JOIN (Sales.Orders AS O INNER JOIN Sales.OrderDetails AS OD ON O.orderId = OD.orderId) ON C.custId = O.custId;
子查询
SQL支持在查询语句中编写查询,或者嵌套其他查询。最外层查询的结果集会返回给调用者,称为外部査询。内部查询的结果是供外部查询使用的,也称为子查询。内部查询可以取代基于常量或变量的表达式,并在运行时进行计算。与在表达式中使用常量不同的是,子查询的结果可能是变化的,因为被查询的表可能会发生变化。通过使用子查询,可以避免在查询解决方案中把操作分成多个步骤,不必在变量中保存中间查询结果。
子查询可以分成独立子查询(self-contained subquery)和相关子查询(correlated subquery)两类。独立子查询不依赖于它所属的外部查询,而相关子查询则必须依赖它所属的外部查询。子查询可以返回一个单独的值(标量)、多个值或整个表结果。
本章重点介绍返回单个值和多个值的子查询,后面的章节介绍返回整个表的子查询。
独立子查询
独立子查询调试起来非常方便,因为总可以把子查询代码独立出来单独运行,并确保它能够正确实现默认的功能。在逻辑上,独立子查询在执行外部查询之前只要先执行一次,接着外部查询再使用子查询的结果继续进行查询。
独立标量子查询
标量子查询是返回单个值的子查询,而不管它是不是独立子查询。标量子查询可以出现在外部查询中期望使用单个值的任何地方(WHERE、SELECT等等)。
例如,假设现在要查询TSQLFundamentals2008数据库中的Orders表,返回订单ID最大的订单信息。
方法一:通过一个变量,保存从Orders表中取回的最大订单ID。接着筛选出订单ID等于变量值的订单。
USE TSQLFundamentals2008; DECLARE @maxId INT = (SELECT MAX(orderId) FROM Sales.Orders); SELECT orderId, orderDate, empId, custId FROM Sales.Orders WHERE orderId = @maxId;方法二:由一个标量子查询返回最大的订单ID。
SELECT orderId, orderDate, empId, custId FROM Sales.Orders WHERE orderId = (SELECT MAX(O.orderId) FROM Sales.Orders AS O);
有效的标量子查询,它的返回值不能超过一个。如果标量子查询返回了多个值,在运行时可能会失败。如果标量子查询没有返回任何值,其结果就转换为NULL。
独立多值子查询
一些谓词(例如IN谓词)可以处理多值子查询。
可能会遇到很多既可以用子查询,又可以用连接来解决的问题。没有什么可靠的经验法则可以断定子查询和连接之间的优劣。**在一些情况下,数据库引擎对这两种查询的解释是一样的;另一些情况下,对二者的解释则是不同的。**对于给定的任务,可以先用直观的形式写出能解决问题的查询语句;如果对它运行的性能不满意,调整方法之一就是尝试重构查询。
例如,以下查询语句返回没有下过任何订单的客户:
SELECT custId, companyName
FROM Sales.Customers
WHERE custId NOT IN
(SELECT O.custId
FROM Sales.Orders AS O);你可能会问,在子查询中指定一个DISTINCT子句是否会有助于提高性能?因为相同的客户ID在Orders表中可能出现多次。数据库引擎足够聪明,它知道应该删除重复的值,而不必非要显式地要求它这么做。所以这个问题不必我们过多费心。
相关子查询
相关子查询需要依赖外部查询,而不能独立地调用。在逻辑上,子查询会为每个外部行单独计算一次。
例如以下查询,会为每个客户返回其订单ID最大的订单:
USE TSQLFundamentals2008;
SELECT custId, orderId, orderDate, empId
FROM Sales.Orders AS O1
WHERE orderId =
(SELECT MAX(O2.orderId)
FROM Sales.Orders AS O2
WHERE O2.custId = O1.custId);相关子查询通常比独立子查询难理解。为了更好地理解,一种有用的方法是将注意力集中在外部表的某一行,再来理解针对改行所进行的逻辑处理。
相关子查询要依赖于外部查询,这使得它比独立子查询更难调试。为了调试相关子查询,要用一个常量来替换外部行的关联,在确保代码正确以后,再把常量替换为外部行的关联。再举一个相关子查询的例子。假设现在要查询Sales.OrderValues视图,为每个订单返回当前订单金额占客户订单总额的百分比。
第二章单表查询中,提供了使用OVER子句的方案:
SELECT orderId, custId, val,
100. * val / SUM(val) OVER() AS pctAll,
100. * val / SUM(val) OVER(PARTITION BY custId) AS pctCust
FROM Sales.OrderValues;这里介绍使用子查询来解决这个问题。尝试用几种不同的方案来解决同一问题总是个好主意,因为不同解决方案通常再复杂性和性能上都有所不同。
SELECT orderId, custId, val,
CAST(100. * val / (SELECT SUM(O2.val)
FROM Sales.OrderValues AS O2
WHERE O2.custId = O1.custId)
AS NUMERIC(5, 2) AS pct
FROM Sales.OrderValues AS O1;查询中用CAST函数将表达式的数据类型转换为精度为5(数字的总位数)、小数点后保留两位数字的数值类型。
EXISTS 谓词
支持一个名为EXISTS的谓词,它的输入是一个子查询;如果子查询能够返回任何行,该谓词则返回TRUE,否则返回FALSE。
例如,以下查询返回下过订单的西班牙客户:
SELECT custId, companyName
FROM Sales.Customers AS C
WHERE country = 'Spain'
AND EXISTS
(SELECT * FROM Sales.Orders AS O
WHERE O.custId = C.custId);使用EXISTS谓词的一个好处是可以用类似英语的语言来直观地表达查询。EXISTS谓词是如何进行自身优化的呢?即使SQL Server引擎什么也没找到时,也足以决定子查询是否应该返回了,而无须处理所有满足条件的行。可以把这种处理方式看作是一种短路(short-circuit),它能够提高处理效率。
与大多数其他情况不同,对于EXISTS谓词的使用,在其子查询的SELECT列表中使用星号在逻辑上并不是不好的实践方式。EXISTS谓词只关心是否存在匹配行,而不考虑SELECT列表中指定的列,好像整个SELECT子句是多余的一样。SQL Server数据库引擎为了优化,会忽略子查询的SELECT列表。所以按照性能优化来说,指定通配符(*)并没有什么负面影响。不过,使用列通配符时,其解析处理还是会涉及少量的开销,因为要把(*)扩展为列名的完整列表,以确保你有权访问所有列。可以使用常量来代替星号,但这种解析开销通常微不足道,不值得为节省这点开销而牺牲代码的可读性。
最后,EXISTS谓词另一个要注意的有趣方面是:与T-SQL中大多数谓词不同,EXISTS谓词使用的是二值逻辑,因为不知道查询是否有返回行的情况是不存在的。
高级子查询
返回前一个或后一个记录
假设现在要对TSQLFundamentals2008数据库中的Orders表进行查询,对于每个订单,返回当前订单的信息和它的前一个订单的ID,一个这样的逻辑等式的例子是小于当前值的最大值:
SELECT orderId, orderDate, empId, custId
(SELECT MAX(O2.orderId)
FROM Sales.Orders AS O2
WHERE O2.orderId < O1.orderId) AS preOrderId
FROM Sales.Orders AS O1;类似地,可以用大于当前值地最小值来表述下一个的概念。
连续聚合 (Running Aggregate)
连续聚合是一种对累积数据(通常按时间顺序)执行的聚合。本节用Sales.OrderTotalsByYear视图来演示计算连续聚合的技术,这个视图包含每年的总订货量。
假设现在有一个任务,需要返回每年的订单年份、订货量,以及连续几年的总订货量:
SELECT orderYear, qty,
(SELECT SUM(O2.qty)
FROM Sales.OrderTotalByYear AS O2
WHERE O2.orderYear <= O1.orderYear) AS runQty
FROM Sales.OrderTotalsByYear AS O1
ORDER BY orderYear;行为不当 (Misbehaving) 的子查询
这部分将介绍几种子查询的运行结果可能与期望的结果恰好相反的情况,以及为了避免在代码中发生于这些情况有关的逻辑缺陷而应该遵循的最佳实践。
NULL的问题
SELECT custId, companyName
FROM Sales.Customers AS C
WHERE custId NOT IN (SELECT O.custId
FROM Sales.Orders AS O);如果Sales.Orders表中有一行客户ID为NULL的订单,将会返回一个空的结果集。UNKNOWN的一个微妙之处是,当对它取反时,结果仍然是UNKNOWN。如果外部表中的值没有在子查询返回的已知集合中出现,那么外部查询仍然不会返回这个值,因为无法判断这个值是否包含NULL的集合所涵盖的范围。
有什么可以遵循的实践原则能避免这个问题呢?
- 首先,当一个列不应该允许为NULL时,把它定义为NOT NULL很重要。加强数据的完整性定义,比很多人想象得要重要得多。
- 其次,在所写的查询语句中,应该考虑三值逻辑可能出现的三种真值(TRUE、FALSE和UNKNOWN)。明确地考虑一下查询是否要处理NULL值,如果要处理,对NULL值的默认处理是否适合需要,当不合适时,就要对查询语句进行调整。
在上述例子中,外部查询返回空集是因为与NULL的比较。如果想忽略NULL值,就应该在查询中(显式或隐式地)排除:
显式地排除NULL值:
SELECT custId, companyName FROM Sales.Customers AS C WHERE custId NOT IN (SELECT O.custId FROM Sales.Orders AS O WHERE O.custId IS NOT NULL);隐式地排除NULL值:
使用NOT EXISTS谓词取代NOT IN谓词,因为EXISTS使用的是二值谓词逻辑,所以EXISTS总是返回TRUE或FALSE,而不会返回UNKNOWN。
SELECT custId, companyName FROM Sales.Customers AS C WEHRE NOT EXISTS (SELECT * FROM Sales.Orders AS O WHERE O.custId = C.custId);因此,使用NOT EXISTS比使用NOT IN要安全。
表表达式
表表达式是一种命名的查询表达式,代表一个有效的关系表。可以像其他表一样,在数据处理语句中使用表表达式。SQL Server支持4种类型的表表达式:
- 派生表(derived table)
- 公用表表达式(CTE, common table expression)
- 视图
- 内联表值函数(inline TVF, inline table-valued function)
表表达式并不是物理上真实存在的对象,它们是虚拟的。对于表表达式的查询在数据库引擎内部都将转换为对底层对象的查询。使用表表达式的好处通常体现在代码逻辑方面,而不是性能方面。例如,表表达式通过模块化的方法可以简化问题的解决方案,还可以规避语言上的某些限制(如对于在SELECT子句中起的别名,不能在逻辑处理顺序位于SELECT子句之前的子句中引用这些别名)。
派生表(表子查询)
派生表是在外部查询的FROM子句中定义的。派生表的存在范围为定义它的外部查询,只要外部查询一结束,派生表也就不存在了。
定义派生表的查询语句写在一对圆括号内,后面跟着AS子句和派生表的名称。要有效地定义任何类型的表表达式,表中的所有列必须由别名。
使用表表达式的一个好处是:在外部查询的任何子句中都可以引用在内部查询的SELECT子句中分配的列别名。这有助于规避一个限制:不能再逻辑处理顺序先于SELECT子句的其他查询子句(如WHERE或GROUP BY)中对SELECT子句分配的列别名进行引用。
第二章单表查询中提到过:
在WHERE子句和SELECT子句中重复使用表达式YEAR(orderDate),SQL Server能够标识在查询中重复使用的同一表达式,因此,表达式其实只会被计算一次。
如果表达式很长,该怎么办呢?维护同一表达式的两个副本可能会破坏代码的可读性和可维护性,而且也更容易出错。可以利用表表达式这个工具:
SELECT orderYear, COUNT(DISTINCT custId) AS numCusts
FROM (SELECT YEAR(orderDate) AS orderYear, custId
FROM Sales.Orders) AS D
GROUP BY orderYear;如前所述,SQL Server在执行时会扩展表表达式的定义,以便直接访问底层对象。扩展后,上述查询会转换成重复使用同一表达式的形式:
SELECT YEAR(orderDate) AS orderYear, COUNT(DISTINCT custId) AS numCusts
FROM Sales.Orders
GROUP BY YEAR(orderDate);可见,使用表表达式是出于逻辑原因,而与性能无关。一般来说,表表达式既不会对性能产生正面影响,也不会产生负面影响。
SQL Server支持另一种格式来为列起别名,可以把这种格式看成是一种外部命名格式。在这种命名格式中,在表表达式名称后面,用一对圆括号一次性指定所有目标列的名称。如下所示:
SELECT orderYear, COUNT(DISTINCT custId) AS numCusts
FROM (SELECT YEAR(orderDate), custId
FROM Sales.Orders) AS D(orderYear, CustId)
GROUP BY orderYear;通常还是建议内联别名格式,有两点原因:
- 使用内联格式时,如果要调试代码,只要把定义表表达式的查询语句独立出来再运行,在结果中出现的列名就是原来指定的别名。如果使用外部格式,表表达式查询独立出来后,就不能在其中包含目标列名;
- 当表表达式的查询很长,采用外部命名格式可能很难分辨出列别名所属的表达式。
嵌套
如果必须要用一个本身就引用了某个派生表的查询去定义另一个派生表,最终得到的就是嵌套派生表。嵌套一般是编程过程中容易产生问题的一个方面,因为它趋于让代码变得复杂,降低代码的可读性。
派生表的多引用
派生表是在外部查询的FROM子句中定义的,其逻辑处理顺序并不优先于外部查询。当对外部查询的FROM子句进行处理时,派生表其实并不存在。如果要引用派生表的多个实例,必须基于同一查询去定义多个派生表。这让代码变得冗长,难以维护,而且更容易出错。
公用表表达式 (CTE)
公用表表达式(CTE,Common table expression)是和派生表相似的一种表表达式,而且具有一些重要优势。
CTE用WITH子句定义:
WITH <CTE_Name> AS
(
<inner_query_defining_CTE>
)
<outer_query_against_CTE>;举一个简单的例子,以下代码定义了一个名为USACusts的CTE,它的内部查询返回所有来自美国的客户,外部查询则选择了CTE中的所有行:
WITH USACusts AS
(
SELECT custId, companyName
FROM Sales.Customers
WHERE country = 'USA'
)
SELECT * FROM USACusts;和派生表一样,一旦外部查询完成,CTE的生命周期也就结束了。
定义多个 CTE
从表面来看,派生表和CTE之间的区别可能只是语义方面,但是CTE具有几个重要优势,其中之一:如果必须在一个CTE中引用另一个CTE,不需要像派生表那样进行嵌套,而只要简单地在同一WITH子句中定义多个CTE,并用逗号分隔开即可。每个CTE可以引用在它前面定义的所有CTE。
例如,查询返回订单年份和该年处理的客户数,但要求每个订单年份处理的客户数要多于70人:
-- 原先做法
SELECT YEAR(orderDate) AS orderYear, COUNT(DISTINCT custId) AS numCusts
FROM Sales.Orders
GROUP BY YEAR(orderDate)
HAVING COUNT(DISTINCT custId) > 70;
-- CTE方式
WITH C1 AS
(
SELECT YEAR(orderDate) AS orderYear, custId
FROM Sales.Orders
), -- 逗号隔开定义的多个CTE
C2 AS
(
SELECT orderYear, COUNT(DISTINCT custId) AS numCusts
FROM C1 -- 每个CTE可以引用在它前面定义的所有CTE
GROUP BY orderYear
)
SELECT orderYear, numCusts
FROM C2
WHERE numCusts > 70;因为在使用CTE之前就已经定义好了CTE,所以不会得到嵌套的CTE(另外从技术上讲,既不能嵌套CTE,也不能在定义派生表的圆括号内再定义CTE)。每个CTE以模块化的方式在代码中单独出现。与嵌套的派生表方法相比,这种模块化的方法能大大地提高代码地可读性和可维护性。
CTE 的多引用
CTE先定义,再查询的特点带来的另一个优点是可以引用同一个CTE的多个实例。
例如,查询计算当前年份和上一年份处理过的客户数量之差:
WITH YearlyCount AS
(
SELECT YEAR(orderDate) AS orderYear,
COUNT(DISTINCT custId) AS numCusts
FROM Sales.Orders
GROUP BY YEAR(orderDate)
)
SELECT Cur.orderYear,
Cur.numCusts AS curNumCusts, Prv.numCusts AS prvNumCusts,
(Cur.numCusts - Prv.numCusts) AS growth
FROM YearlyCount AS Cur
LEFT JOIN YearlyCount AS Prv
ON Cur.orderYear = Prv.orderYear + 1;递归 CTE
CTE之所以与其他表表达式不同,是因为它支持递归查询。定义一个递归CTE至少需要两个查询,第一个查询称为定位点成员(anchor member),第二个查询称为递归成员(recursive member)。递归CTE的基本格式如下:
WITH <CTE_Name> AS
(
<anchor_member>
UNION ALL
<recursive_member>
)
<outer_query_against_CTE>;定位点成员只是一个返回有效关系结果表的查询,与用于定义非递归表表达式的查询类似。定位点成员查询只被调用一次。
递归成员是一个引用了CTE名称的查询。对CTE名称的引用代表的是在一个执行序列中逻辑上的前一个结果集。
- 第一次调用递归成员时,前一个结果集代表由定位点成员返回的任何结果集。
- 之后每次调用递归成员时,对CTE名称的引用代表对递归成员的前一次调用所返回的结果集。
- 递归成员的递归终止检查是隐式的,递归成员会一直被重复调用,直到返回空的结果集或超出了某种限制条件。
外部查询中的CTE名称引用代表对定位点成员调用和所有对递归成员调用的联合结果集。
以下代码演示了如何使用递归CTE来返回有关某个雇员(Don Funk, empId 为2)及其所有各级(直接或间接)下属的信息:
WITH EmpsCTE AS
(
SELECT empId, mgrId, firstName, lastName
FROM HR.Employees
WHERE empId = 2
UNION ALL
SELECT C.empId, C.mgrId, C.firstName, c.lastName
FROM EmpsCTE AS P
INNER JOIN HR.Employees AS C
ON C.mgrId = P.empId
)
SELECT empId, mgrId, firstName, lastName
FROM EmpsCTE;如果递归成员的连接谓词中存在逻辑错误,或是循环中的数据结果出了问题,都可能会导致递归成员被调用无限多次。为了安全起见,SQL Server默认把递归成员最多可以调用的次数限制为100次。为了修改默认的最大递归数,可以在外部查询的最后指定OPTION(MAXRECURSION n)提示(hint),这里的n是一个范围在0到32767之间的整数。n为0时,表示去掉对递归调用次数的限制。
SQL Server把定位点成员和递归成员返回的临时结果集先保存在tempdb数据库的工作表中。如果去掉对递归次数的限制,万一查询失控,工作表的体积将很快变得非常大。当tempdb数据库的体积不能再继续增长时(例如,磁盘空间耗尽),查询便会失败。
视图
派生表和CTE的作用范围仅限于在单个语句范围内,这意味着它们都不可重用。视图的定义存储在一个数据库对象中,一旦创建就是数据库的永久部分,只有用删除语句显式删除,才会从数据库中移除。
以下代码在TSQLFundamentals2008数据库中的Sales架构中创建了一个名为USAcusts的视图,代表来自美国的所有客户:
USE TSQFundamentals2008;
IF OBJECT_ID('Sales.USAcusts') IS NOT NULL
DROP VIEW Sales.USAcusts;
GO -- CREATE VIEW必须是批处理中仅有的语句
CREATE VIEW Sales.USAcusts
AS
SELECT custId, companyName, contactName, contactTitle, address,
city, region, postalCode, Country, phone, fax
FROM Sales.Customers
WHERE country = 'USA';
GO
-- 创建好视图之后,就可以像查询数据库中的其他表一样来查询视图
SELECT custId, companyName
FROM Sales.USAcusts;因为视图是数据库中的一个对象,所以可以像其他可以查询的数据库对象一样,用权限来控制对视图的访问(如SELECT、INSERT、UPDATE、DELETE权限)。例如,可以禁止对底层数据库对象的直接访问,而只允许访问视图。
一般建议避免对视图使用SELECT * 语句,因为列是在编译视图时进行枚举的,新加的列可能不会自动加到视图中。例如,假设基于 SELECT * FROM dbo.T1这个查询而定义一个视图;在视图创建时,T1表有coll和col2两列。 SQL Server在视图的元数据中只会存储这两列的信息。如果以后又修改了表的定义或增加了几列,这些新增加的列不会自动添加到视图中。用一个名为sp_ refreshview的存储过程可以刷新视图的元数据,但为避免混淆,最好的开发实践就是在视图的定义中显式地列出需要的列名。如果在底层表中添加了列,而且在视图中需要这些新加的列,则可以使用 ALTER VIEW语句对视图定义进行相应的修改。
视图和 ORDER BY 子句
记住,在定义表表达式的查询语句中不允许出现 ORDER BY子句,因为关系表的行之间没有顺序。试图创建一个有序视图的想法也不合理,因为这违反了关系模型定义的关系的基本属性。
只有在创建视图的语句中使用了TOP或FOR XML选项,SQL Server才允许使用ORDER BY子句,这两种情况都不符合SQL标准。并且,这两种情况下的ORDER BY子句也不会用于普通的数据展示,无法保证结果集中的行顺序。
有时,用于定义表表达式的查询会包含TOP选项和 ORDER BY子句,而对该表表达式的查询却没有ORDER BY子句。在这些情况下,输出结果不会保证有什么特定的顺序。如果结果碰巧是有序的,可能是优化处理的原因。因此,当对表表达式进行查询时,除非在外部査询中指定了ORDER BY子句,否则不应该假定输出具有任何顺序。
视图选项
ENCRYPTION 选项
在创建或修改视图、存储过程、触发器及用户定义函数(UDF)时,都可以使用ENCRYPTION选项。如果指定ENCRYPTION选项,SQL Server在内部会对定义对象的文本信息进行混淆(obfuscated)处理。普通用户通过任何目录对象都无法直接看到这种经过混淆处理的文本,只有特权用户通过特殊手段才能访问创建对象的文本。
为了得到视图的定义,可以:
-- 调用OBJECT DEFINITION函数
SELECT OBJECT_DEFINITION(OBJECT_ID('Sales.USAcusts');
-- 使用存储过程sp_helptext
EXEC sp_helptext 'Sales.USAcusts';因为在创建视图时没有指定ENCRYPTION选项,所以能够直接看到定义视图的文本。那么接下来修改视图定义,来包含ENCRYPTION选项:
ALTER VIEW Sales.USAcusts WITH ENCRYPTION
AS
SELECT custId, companyName, contactName, contactTitle, address,
city, region, postalCode, Country, phone, fax
FROM Sales.Customers
WHERE country = 'USA';此时再获取视图定义的文本,结果为NULL。
SCHEMABINDING 选项
视图和UDF支持 SCHEMABINDING选项,该选项可以将对象和列的架构绑定到引用其
对象的架构。也就是说,一旦指定了这个选项,被引用的对象就不能删除,被引用的列也不能删除或修改。这样的操作是为了防止被引用的对象或列的变动导致查询视图时发生运行错误。
CHECK OPTION 选项
CHECK OPTION选项的目的是为了防止通过视图执行的数据修改与视图中设置的过滤
条件(假设在定义视图的查询中存在过滤条件)发生冲突。
上述定义USACusts视图的查询要筛选出country列等于’USA’的客户。该视图的定义目前没有CHECK OPTION选项。这意味着,现在可以通过视图把不是来自美国的客户插入表中;也可以通过视图对现有的客户进行更新,把他们的country列修改为除了美国以外的其他国家。例如如下代码。通过视图,成功插入了一个公司名称为’customerABCDE’、来自英国的客户:
INSERT INTO Sales.USAcusts(
companyname, contactname, contacttitle, address,
city, region, postalcode, country, phone, fax)
VALUES(
'Customer ABCDE', 'contact ABCDE', 'TITLE ABCDE', 'address ABCDE',
'London', NULL, '12345', 'UK', '012-3456789', '012-3456789');这就是所谓的与视图的查询过滤条件相冲突的修改,只需要在定义视图的查询语句末尾加上WITH CHECK OPTION即可:
ALTER VIEW Sales.USAcusts WITH SCHEMABINDING
AS
SELECT custId, companyName, contactName, contactTitle, address,
city, region, postalCode, Country, phone, fax
FROM Sales.Customers
WHERE country = 'USA'
WITH CHECK OPTION;内联表值函数
内联表值函数是一种可重用的表表达式,支持输入参数,其他方面都与视图相似。
例如,以下代码在 TSQLFundamentals2008数据库中创建了一个内联表值函数fn_GetCustOrders:
USE TSQLFundamentals2008;
IF OBJECT_ID(dbo.fn_GetCustOrders) IS NOT NULL
DROP FUNCTION dbo.fn_GetCustOrders;
GO -- CREATE FUNCTION必须是批处理中仅有的语句
CREATE FUNCTION dbo.fn_GetCustOrders
(@cid INT) RETURNS TABLE
AS
RETURN
SELECT orderId, custId, empId, orderDate, requiredDate,
shippedDate, shipperId, freight, shipName, shipAddress, shipCity,
shipRegion, shipPostalcode, shipCountry
FROM Sales.Orders
WHERE custid = @cid;
GO以下代码将内联表值函数与Sales.OrderDetails表进行连接,对客户1的订单和相关的订单明细进行匹配:
SELECT CO.orderId, CO.custId, OD.productId, OD.qty
FROM dbo.fn_GetCustOrders(1) AS CO
INNER JOIN Sales.OrderDetails AS OD
ON CO.orderId = OD.orderId;APPLY 运算符
APPLY运算符是SQL Server的一个非标准表运算符,和其他表运算符一样,这个运算符也在查询的FROM子句中使用。APPLY运算符对两个输入表进行操作,其中第二个可以是一个表表达式,我们将它们分別称为左表和右表。右表通常是一个派生表或内联表值函数。APPLY运算符支持两种形式:CROSS APPLY和OUTER APPLY。
CROSS APPLY
实现了一个逻辑査询处理步骤,把右表表达式应用到左表中的每一行,再把结果集组合起来,生成一个统一的结果表。就目前来看,CROSS APPLY运算符与交叉连接CROSS JOIN非常类似:
SELECT S.shipperId, E.empId
FROM Sales.Shippers AS S
CROSS JOIN HR.Employees AS E;
SELECT S.shipperId, E.empId
FROM Sales.Shippers AS S
CROSS APPLY HR.Employees AS E;但是,与连接不同的是,当使用CROSS APPLY操作符时,对于左表中的每一行,右表表达式可能代表不同的数据行集合。为此,可以在右边使用一个派生表,在派生表的查询中去引用左表列;也可以使用内联表值函数,把左表中的列作为输入参数进行传递。
例如,以下代码使用CROSS APPLY运算符返回每个客户最新的三个订单:
SELECT C.custId, A.orderId, A.orderDate
FROM Sales.Customers AS C
CROSS APPLY
(SELECT TOP(3) orderId, empId, orderDate, requiredDate
FROM Sales.Orders AS O
WHERE O.custId = C.custId
ORDER BY orderDate DESC, orderId DESC) AS A;
-- 利用 表子查询 + 排名函数ROW_NUMBER + OVER子句能达到相同效果
SELECT *
FROM (
SELECT C.custId, O.orderId, O.orderDate,
ROW_NUMBER() OVER(PARTITION BY C.custId ORDER BY orderDate DESC, orderId DESC) rn -- 没有订单时,有一行NULL值,会被赋予rn = 1
FROM Sales.Customers AS C
LEFT JOIN Sales.Orders AS O
ON C.custid = O.custid) A
WHERE rn <= 3 and orderID is not null; -- 剔除没有订单的客户可以把上面查询中的表表达式A看作是一个相关表子查询。就逻辑处理来说,右表表达式要应用于Customers表的每一行。注意,在派生表的查询过滤条件中引用了来自左表的列C.custId。派生表为左表当前行的客户返回他的3个最新订单。对左表的每一行应用派生表,CROSS APPLY运算符就可以返回每个客户最新的3个订单。
出于封装的目的,内联表值函数比派生表用起来更方便,代码也更容易理解和维护。例如,以下代码创建了一个内联表值函数fn_TopOrders,它的输入参数是一个客户ID(@custId)和一个数量(@n),为客户@custId返回其最新的@n个订单:
IF OBJECT_ID('fn_TopOrders') IS NOT NULL
DROP FUNCTION dbo.fn_TopOrders;
GO
CREATE FUNCTION dbo.fn_TopOrders
(@custId INT, @n INT) RETURN TABLE
AS
RETURN
SELECT TOP(@n) orderId, empId, orderDate, requiredDate
FROM Sales.Orders
WHERE custId = @custId
ORDER BY orderDate DESC, orderId DESC;
GO
SELECT C.custId, A.orderId, A.orderDate
FROM Sales.Customers AS C
CROSS APPLY dbo.fn_TopOrders(C.custId, 3) AS A;这样一来,代码就更容易理解和维护了。就物理处理来说,不会发生任何变化,SQL Server在执行査询时会扩展表表达式的定义,在任何情况下,最终都会直接査询底层对象。
如果右表表达式返回的是一个空集, CROSS ALLPY运算符则不会返回相应左边的数据行。如果要在右表表达式返回空集时也照样返回相应左表中的行,则可以用OUTER APPLY运算符代替CROSS APPLY。
OUTER APPLY
OUTER APPLY运算符在逻辑査询处理步骤之外,增加了一个逻辑处理阶段:标识出让右表表达式返回空集的左表中的数据行,并把这些行作为外部行添加到结果表中,来自右表表达式的列用NULL作为占位符。
SELECT C.custId, A.orderId, A.orderDate
FROM Sales.Customers AS C
OUTER APPLY
(SELECT TOP(3) orderId, empId, orderDate, requiredDate
FROM Sales.Orders AS O
WHERE O.custId = C.custId
ORDER BY orderDate DESC, orderId DESC) AS A;
-- 利用 表子查询 + 排名函数ROW_NUMBER + OVER子句能达到相同效果
SELECT *
FROM (
SELECT C.custId, O.orderId, O.orderDate,
ROW_NUMBER() OVER(PARTITION BY C.custId ORDER BY orderDate DESC, orderId DESC) rn -- 没有订单时,有一行NULL值,会被赋予rn = 1
FROM Sales.Customers AS C
LEFT JOIN Sales.Orders AS O
ON C.custid = O.custid) A
WHERE rn <= 3;集合运算
T-SQL支持3种集合运算:
- 并集(UNION)
- 交集(INTERSECT)
- 差集(EXCEPT)
按照定义,集合运算是在两个集合(或多集)之间进行的运算,而且集合本身是无序的,所以,集合运算涉及的两个查询不能包含 ORDER BY子句。包含 ORDER BY子句的查询可以确保结果的排列顺序,因此,这样的查询返回的不是集合,而是游标( cursor)。虽然运算涉及的查询不能包含 ORDER BY子句,但可以为整个集合运算结果选择性地增加一个 ORDER BY子句。
集合运算有个有趣的特点:对行进行比较时,集合运算认为两个NULL相等。
ANSI SQL对每种集合运算都支持两个选项:DISTINCT(默认值)和ALL。SQL Server 2008对3种集合运算,均支持DISTINCT选项,但只在UNION中支持ALL选项。按照语法要求,不能显式指定DISTINCT子句,但如果不显式指定ALL,则默认使用DISTINCT。
UNION 集合运算
从逻辑处理过程来看,UNION(隐含DISTINCT)集合运算通过删除重复记录,可以把两个输入的多集转变为一个集合,即使只在一个输入中有重复的行,结果中也会只出现一次。
从物理处理过程来看,SQL Server不一定必须先删除输入多集中的重复行,再进行集合运算,相反,它可以先把两个多集组合在一起,然后再删除重复行。
如果在合并两个输入集以后不可能会出现重复行,建议使用UNION ALL,以避免SQL Server为检查重复行而带来的额外开销。
INTERSECT 集合运算
INTERSECT DISTINCT 集合运算
如果一个行在两个输入多集中都至少出现一次,那么交集返回的结果中将包含这一行。例如,以下代码返回既是雇员地址,也是客户地址的不同地址:
SELECT country, region, city FROM HR.Employees
INTERSECT
SELECT country, region, city FROM Sales.Customers;前面讲过,集合运算对行进行比较时,认为两个NUL值相等。如果客户和雇员地址中均包含(UK, NULL, London)这个地址,它能在输出中出现非比寻常。除了country和city列以外,当对雇员行中取值为NULL的region列和客户行中取值为NULL的 region列进行比较时,集合运算认为二者相等,所以就返回该行记录。
这种对NULL值的处理方式有一定的优势。例如,代替INTERSECT集合运算的一种方法是使用内连接INNER JOIN,另一种方法是使用EXISTS谓词。在这两种情况下,当对雇员表region列中的NULL值和客户表region列中的NULL值进行比较时,比较结果都是UNKNOWN,这样的行将被过滤掉。因此,除非增加额外的逻辑,以特定方式对NULL进行处理,否则即使(UK, NULL, London)这行记录在运算两边的表中都出现,内连接和 EXISTS的实现方法都不能返回该行。
INTERSECT ALL 集合运算
ANSI SQL支持带有ALL选项的INTERSECT集合运算,但SQL Server 2008还没有实现这种运算。INTERSECT ALL与UNION ALL不同,前者不会返回所有重复行,而只返回重复行数目较少的那个多集的所有重复行。
虽然 SQL Server不支持内建的 INTERSECT ALL运算,但用其他解决方案也能生成相同的结果。可以用ROW NUMBER函数来计算每个输入查询中每行的出现次数(行号)。为此,在函数的PARTITION BY子句中指定所有参与集合运算的列,并在 ORDER BY子句中用 SELECT<常量>来表明行的排列顺序不重要,接着再对两个带有ROW_NUMBER函数的查询应用INTERSECT集合运算。
在排序函数的OVER子句中使用**ORDER BY( SELECT<常量>)**用这种方法可以告诉 SQL Server不必在意行的顺序。 SQL Server足够聪明,它能够意识到将要为所有行分配同一常量,因此,没有必要对数据进行排序,更没有必要为此付出一定的代价。
例如,地址(UK, NULL, London)在Employees表中出现了4次,它们的出现次数分别编为1~4。在Customers表中,地址(UK, NULL, London)出现了6次,其出现次数分别编为1-6。对这两个输入集取其交集时,出现次数编号为1-4的所有行就是它们的交集。
以下是这个解决方案的完整查询语句:
SELECT ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY(SELECT 0)) AS rowNum,
country, region, city
FROM HR.Employees
INTERSECT
SELECT ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY(SELECT 0)) AS rowNum,
country, region, city
FROM Sales.Customers;
-- 如果不想返回行号,则可以在以上基础上【定义一个表表达式(如CTE)】
WITH INTERSECT_ALL
AS
(
SELECT ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY(SELECT 0)) AS rowNum,
country, region, city
FROM HR.Employees
INTERSECT
SELECT ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY(SELECT 0)) AS rowNum,
country, region, city
FROM Sales.Customers
)
SELECT country, region, city
FROM INTERSECT_ALL;EXCEPT 集合运算
EXCEPT运算对两个输入查询的结果集进行操作,返回出现在第一个结果集中,但不出现在第二个结果集中的所有行。
EXCEPT DISTINCT 集合运算
EXCEPT集合运算在逻辑上先删除两个输入多集中的重复行(把多集转变成集合),然后返回只在第一个集合中出现,在第二个集合中不出现的所有行。
EXCEPT运算也可以用其他方法来实现。一种方法是使用外连接,筛选出在连接左边出现而在右边不出现的外部行。另一种方法是使用NOT EXISTS谓词。不过,如果你认为两个NUL值是相等的,集合运算默认才具有这样的行为,所以无须增加额外的处理,但其他两种方法不支持该操作。
EXCEPT ALL 集合运算
虽然 SQL Server没有提供内建的 EXCEPT ALL运算,但用与 INTERSECT ALL的解决方案类似的方法,也可以为 EXCEPT ALL提供替代的解决方案。也就是为每个输入查询增加一个ROW NUMBER计算,算出每行是第几次出现,再对两个输入集应用 EXCEPT运算。这样就只返回出现次数找不到匹配的行。
WITH EXCEPT_ALL
AS
(
SELECT ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY(SELECT 0)) AS rowNum,
country, region, city
FROM HR.Employees
EXCEPT
SELECT ROW_NUMBER() OVER(PARTITION BY country, region, city
ORDER BY(SELECT 0)) AS rowNum,
country, region, city
FROM Sales.Customers
)
SELECT country, region, city
FROM EXCEPT_ALL;集合运算的优先级
SQL定义了集合运算之间的优先级。 INTERSECT运算优先级最高,而UNION和EXCEPT的优先级相等。在包含多个集合运算的查询中,首先计算INTERSECT,然后按照从左到右的出现顺序依次处理优先级相同的运算。当然,要控制集合运算的计算顺序,可以使用圆括号,它总是具有最高的优先级。
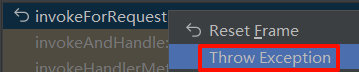
透视、逆透视及分组集
- 透视转换:把数据从行的状态旋转为列的状态。
- 逆透视转换:把数据从列的状态旋转为行的状态。
- 分组集:用于分组的属性集合。
透视转换(PIVOT)
透视数据(pivoting)是一种把数据从行的状态旋转为列的状态的处理,在这个过程中可
能需要对值进行聚合。
本章通篇使用的是一个示例数据表Orders,详见如下代码:
USE tempdb;
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
CREATE TABLE dbo.Orders
(
orderId INT NOT NULL,
orderDate DATE NOT NULL,
empId INT NOT NULL,
custId VARCHAR(5) NOT NULL,
qty INT NOT NULL,
CONSTRAINT PK_Orders PRIMARY KEY(orderid)
);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES
(30001, '20070802', 3, 'A', 10),
(10001, '20071224', 2, 'A', 12),
(10005, '20071224', 1, 'B', 20),
(40001, '20080109', 2, 'A', 40),
(10006, '20080118', 1, 'C', 14),
(20001, '20080212', 2, 'B', 12),
(40005, '20090212', 3, 'A', 10),
(20002, '20090216', 1, 'C', 20),
(30003, '20090418', 2, 'B', 15),
(30004, '20070418', 3, 'C', 22),
(30007, '20090907', 3, 'D', 30);
SELECT * FROM dbo.Orders;先考虑一个需求,生成一个报表,包含每个雇员和客户组合之间的总订货量:
SELECT empId, custId, SUM(qty) AS sumQty
FROM dbo.Orders
GROUP BY empId, custId;该查询生成下列输出:
| empId | custId | sumQty |
|---|---|---|
| 2 | A | 52 |
| 3 | A | 20 |
| 1 | B | 20 |
| 2 | B | 27 |
| 1 | C | 34 |
| 3 | C | 22 |
| 3 | D | 30 |
现在要求按如下格式(行为雇员,列为客户,值为总订货量)来生成输出结果:
| empId | A | B | C | D |
|---|---|---|---|---|
| 1 | NULL | 20 | 34 | NULL |
| 2 | 52 | 27 | NULL | NULL |
| 3 | 20 | NULL | 22 | 30 |
上表是对Orders表中的数据进行聚合和透视转换后的视图,用于生成数据的这种视图的技术被称为透视转换。透视转换涉及三个逻辑处理阶段,每个阶段都有相关的元素:
- 分组阶段:处理相关的分组或行元素
- 扩展(spreading)阶段:处理相关的扩展或列元素
- 聚合阶段:处理相关的聚合元素和聚合函数
上述例子中,必须要在结果中为每个唯一的雇员ID生成一行记录。这就要求对Orders表中的行按照empId列分组。Orders表分别用一个列来保存所有的客户ID值和他们的订货量。透视处理应该为每个唯一的客户ID生成一个不同的结果列,用于保存该客户的聚合订货量。可以将这个处理看作是根据客户ID来扩展订货聚合量的过程,本例中的扩展元素为custId列。最后,由于透视转换涉及分组,所以需要对数据进行聚合,以生成分组元素和扩展元素的交叉位置上的结果值,这就需要标识聚合函数和聚合元素(本例中为SUM函数和qty列)。
总之,透视转换涉及分组、扩展及聚合三个阶段。本例按照empId进行分组,按照custId对订货量进行扩展,最后进行聚合SUM(qty)。在弄清楚透视转换涉及的元素以后,剩下的任务就是在透视转换的某个通用查询模板中把这些元素组装在合适的位置上。下面将介绍两种透视转换的解决方案:
- 标准SQL的解决方案
- T-SQL特定的PVOT运算符的解决方案
使用标准SQL进行透视转换
透视转换的标准解决方案以一种非常直接的方式来处理转换过程中涉及的三个阶段:
- 分组阶段用 GROUP BY子句实现;
- 扩展阶段通过在 SELECT子句中为每个目标列指定CASE表达式来实现。这需要事先知道每个扩展元素的取值,并为每个值指定一个单独的CASE表达式;如果不知道需要扩展的值,而且希望从数据中查询这些值,就得用动态SQL(第10章)去构建查询字符串;
- 聚合阶段通过为每个CASE表达式的结果应用相关的聚合函数来实现。
以下是对订单数据进行透视转换解决方案的完整査询语句,返回每个雇员(按行)和客户(按列)的总订货量:
SELECT empId,
SUM(CASE WHEN custId = 'A' THEN qty END) AS A,
SUM(CASE WHEN custId = 'B' THEN qty END) AS B,
SUM(CASE WHEN custId = 'C' THEN qty END) AS C,
SUM(CASE WHEN custId = 'D' THEN qty END) AS D
FROM dbo.Orders
GROUP BY empId;使用T-SQL PIVOT运算符进行透视转换
和其他表运算符类(如JOIN)类似,PIVOT运算符也是在FROM子句上下文中执行操作。它对某个源表或表表达式进行操作、透视数据,再返回一个结果表:
SELECT ...
FROM <sourceTable_or_tableExpression>
PIVOT(<agg_func>(<aggregation_element>)
FOR <spreading_element>
IN (<list_of_targretColumns>)) AS <resultTableAlias>
...;在PIVOT运算符的圆括号内要指定聚合函数、聚合元素、扩展元素(列)及目标列名的列表。在PIVOT运算的圆括号后面,可以为结果表指定一个别名。
对于PIVOT运算符有个重要的地方需要注意:不需要显式指定分组元素,也就不需要在查询中使用GROUP BY子句。PIVOT运算符隐式地把源表(或表表达式)中既没有指定为扩展元素,也没有指定为聚合元素的那些元素作为分组元素。所以在使用PIVOT运算符时,必须保证PIVOT运算符的源表除了分组、扩展和聚合元素以外,不能再包含其他属性(列),为此,一般不直接把PIVOT运算符应用到源表,而是将其应用到一个表表达式。
上述例子使用PIVOT运算符的写法:
SELECT empId, A, B, C, D
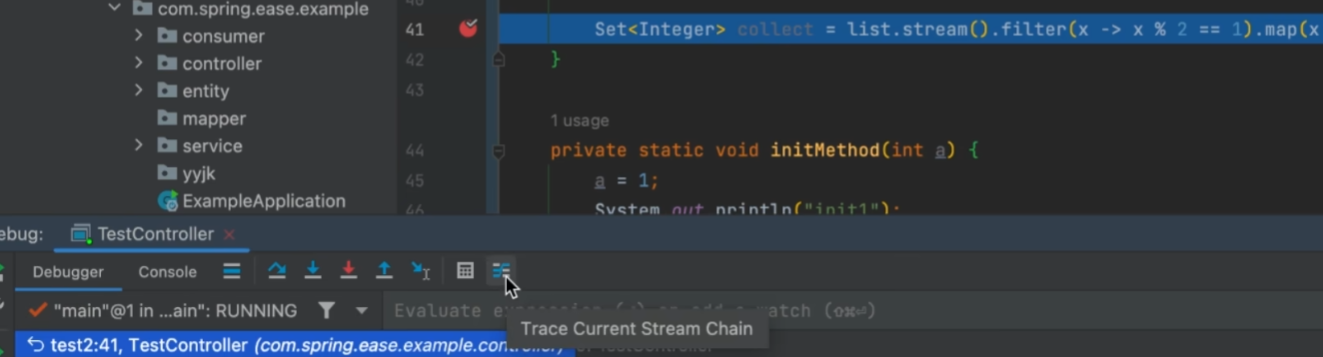
FROM (SELECT empId, custId, qty
FROM dbo.Orders) AS D
PIVOT(SUM(qty) FOR custId IN (A, B, C, D)) AS P;为了深刻理解这里为什么要求使用表表达式,可以看如下直接对Orders表应用PIVOT运算符的查询:
SELECT empId, A, B, C, D
FROM dbo.Orders
PIVOT(SUM(qty) FOR custId IN (A, B, C, D)) AS P;Orders表包含orderId、orderDate、empId、custId和qty列,上述查询会默认将orderId、orderDate、empId认为是分组元素。因此,强烈建议不要直接对基础表进行操作,即使表中只包含用于透视转换的列。因为我们无法预测将来是否会向表中添加新列,从而让查询产生不正确的结果。
逆透视转换(UNPIVOT)
逆透视转换(unpivoting)是一种把数据从列的状态旋转为行的状态的技术。通常,它涉及查询数据的透视状态,将来自单个记录中多个列的值扩展为单个列中具有相同值的多个记录。换句话说,把透视表中的每个源行潜在地转换成多个行,每行代表原透视表的一个指定的列值。
接下来我们通过一个实例来理解。先在tempdb数据库中创建并填充EmpCustOrders表:
IF OBJECT_ID('dbo. Empcustorders','U') IS NOT NULL
DROP TABLE dbo.EmpCustOrders;
SELECT empId, A, B, C, D
INTO dbo.EmpCustOrders
FROM (SELECT empId, custId, qty
FROM dbo.Orders) As D
PIVOT(SUM(qty) FOR custId IN(A, B, C, D)) AS P;
SELECT * FROM dbo.EmpCustOrders;现在对EmpCustOrders表进行逆透视转换数据,为每个雇员和客户组合返回一行记录,其中包含这一组合的订货量。期望的输出结果如下:
| empId | custId | sumQty |
|---|---|---|
| 2 | A | 52 |
| 3 | A | 20 |
| 1 | B | 20 |
| 2 | B | 27 |
| 1 | C | 34 |
| 3 | C | 22 |
| 3 | D | 30 |
使用标准 SQL 进行逆透视转换
逆透视转换的标准SQL解决方案非常明确地要实现3个逻辑处理阶段:
生成副本(为需要逆透视的每个列生成一个副本)
在关系代数和SQL中,可以用笛卡尔积(交叉连接CROSS JOIN)来生成每一行的多个副本。为此,需要在EmpCustOrders表和一个每行代表一个客户的表之间进行交叉连接。
从SQL Server 2008开始,可以用表值构造函数,按照VALUES子句的格式来创建一个虚拟表,该表中每个客户对应一行记录。
SELECT * FROM dbo.EmpCustOrders CROSS JOIN (VALUES ('A'), ('B'), ('C'), ('D')) AS Custs(custId); -- SQL Server 2008之前,需要把上述VALUES子句替换为一系列的SELECT语句,每条---- SELECT语句根据常量构造一行记录,并在各SELECT语句之间用UNION ALL集合运算组合 SELECT * FROM dbo.EmpCustOrders CROSS JOIN (SELECT 'A' AS custId UNION ALL SELECT 'B' UNION ALL SELECT 'C' UNION ALL SELECT 'D') AS Custs;提取元素和删除不相关的交叉
生成一个数据列,返回与当前副本所代表的客户相对应的列值。
具体到本例,如果当前custId的值为A,则qty列应该返回A列的值,以此类推。用一个简单的CASE表达式就可以实现这一步:
SELECT * FROM (SELECT empid, custid, (CASE custid WHEN 'A' THEN A WHEN 'B' THEN B WHEN 'C' THEN C WHEN 'D' THEN D END) AS qty FROM dbo.EmpCustOrders CROSS JOIN (VALUES ('A'), ('B'), ('C'), ('D')) AS Custs(custId)) AS D WHERE qty IS NOT NULL; -- 原始表中NULL值代表不相关的交叉
使用 T-SQL 的 UNPIVOT 运算符进行逆透视转换
对数据进行逆透视转换时,会为源表中想要进行逆透视的任意列生成两个结果列。在这
个例子中,须要对源表列A、B、C和D进行逆透视,为它们生成两个结果列custId和qty,前者用于保存源表列的名称(“A”、“B”、“C”及“D”),后者用于保存源表列的值(本例为订货量)。使用UNPVOT运算符的査询语句的一般格式为:
SELECT ...
FROM <sourceTable_or_tableExpression>
UNPIVOT(<targetCol_to_hold_sourceColValues>
FOR <targetCol_to_hold_sourceColNames>
IN(<list_of_sourceColumns>)) As <resultTableAlias>
...;与 PIVOT运算符类似,UNPIVOT也是作为表运算符,在FROM子句的上下文中执行操作。它的操作对象是源表或表表达式(本例的EmpCustOrders)。在UNPIVOT运算符的圆括号中需要指定的内容包括:用于保存源表列值的目标列名(这里为qty),用于保存源表列名的目标列名(custId),以及源表的列名列表(A、B、C、D)。在UNPIVOT运算符的圆括号后面,可以为表运算符的结果表提供一个别名。
下面使用UNPIVOT运算符来实现这个例子要求的逆透视转换的完整查询方案:
SELECT empId, custId, qty
FROM dbo.EmpCustOrders
UNPIVOT(qty FOR custId IN (A, B, C, D)) AS U;注意, UNPIVOT运算符会执行与前面介绍的逻辑处理阶段相同的几个步骤:生成副本、提取元素和删除交叉位置上的NUL值。与基于标准SQL的解决方案相比, UNPIVOT的最后一个阶段不是可选的。
还要注意,对经过透视转换所得的表再进行逆透视转换,并不能得到原来的表。因为逆透视转换只是把经过透视转换后的值再旋转到另一种新的格式。但是,经过逆透视转换后的表可以再通过透视转换回到原来的状态。换句话说,透视转换中的聚合操作会丢失掉源表中的详细信息,经过透视转换后,保存下来的只是操作之间的所有聚合结果,而逆透视转换则不会丢失任何信息。
分组集(GROUPING SET)
简单来说,分组集就是分组(GROUP BY子句)使用的一组属性(或列名)。在传统的SQL中,一个聚合查询只能定义一个分组集。例如,对于下列4个查询,它们每个都只定义了一个分组集:
SELECT empId, custId, SUM(qty) AS sumQty
FROM dbo.Orders
GROUP BY empId, custId;
SELECT empId, SUM(qty) AS sumQty
FROM dbo.Orders
GROUP BY empId;
SELECT custId, SUM(qty) AS sumQty
FROM dbo.Orders
GROUP BY custId;
SELECT SUM(qty) AS sumQty
FROM dbo.Orders;假设现在不想生成4个单独的结果集,而是希望生成一个统一的结果集,其中包含所有4个分组集的聚合数据。为了实现该目标,可以使用UNION ALL集合运算,将所有4个査询的结果集合并在一起。由于集合运算要求所有结果集包含相同的列数,对应列的架构定义要保持兼容,所以可能须要对查询进行调整,用增加占位符(比如NULL)的办法来代替缺少的列。
虽然设法得到了期望的结果,但这种解决方案存在两个主要问题:代码长度和性能。首先,因为需要为每个分组集指定完整的GROUP BY査询,所以当分组集的数量很大时,查询语句可能变得相当长。其次,为了处理査询, SQL Server需要为每个查询分别单独扫描源表,导致效率低下。
SQL Server 2008引入了很多遵循标准SQL的新功能,能够支持在同一査询语句中定义多个分组集。这些分组集可以是GROUP BY子句的GROUPING SETS、CUBE、ROLLUP从属子句(subClause),以及GROUPING_ID函数。
GROUPING SETS 从属子句
GROUPING SETS从属子句是增强GROUP BY子句的有力保证,主要用于生成报表和数据仓库处理。借助该从属子句,就可以在同一査询中定义多个分组集。只要简单地在GROUPING SETS从属子句的圆括号内列出想要定义的各分组集,分组集之间用逗号分隔开。对于每个分组集,也在圆括号中列出它们各自的成员,成员之间用逗号隔开。例如,下面的查询定义了4个分组集:(empId, custId)、(empId)、(custId)和():
SELECT empId, custId, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY GROUPING SETS (
(empId, custId),
(empid),
(custid),
());这个査询具有两大主要优势:一是需要的代码明显少得多;二是SQL Server能够优化扫描源表的次数,不须要为每个分组集单独对源表进行扫描。
CUBE 从属子句
GROUP BY 子句的CUBE从属子句为定义多个分组集提供了一种简略的方法。在CUBE从属子句的圆括号中,只须要列出由逗号分隔开的元素成员,就可以得到基于输入成员而定义的所有可能的分组集。例如,CUBE(a,b,c)与 GROUPING SETS[(a, b, c), (a, b), (a, c), (b, c), (a), (b), (c), ()]等效。在集合论中,由给定集合的所有子集构成的集合称为幂集( power set)。对于由给定元素构成的一个分组集(如(a, b, c) ),可以把CUBE从属子句看作是用于生成这个分组集的幂集。
前面用GROUPING SETS从属子句定义的4个分组集:(empId, custId)、(empId)、(custId)和( ),也可以简单地使用CUBE(empId, custId)来实现:
SELECT empId, custId, SUM(qty) AS sumQty
FROM dbo.Orders
GROUP BY CUBE(empId, custId);ROLLUP 从属子句
GROUP BY 子句的ROLLUP从属子句也提供了一种定义多个分组集的简略方法。不过,与CUBE从属子句不同的是, ROLLUP并不是生成基于输入成员而定义的所有可能的分组集,而只生成其中的一个子集。 ROLLUP认为输入成员之间存在一定的层次关系,从而生成让这种层次关系有意义的所有分组集。换句话说,CUBE(a,b,c)生成由3个输入成员得到的所有8个可能的分组集;而 ROLLUP认为这3个输入成员存在a > b > c的层次关系,所以只生成4个分组集,在效果上相当于指定了ROUPING SETS((a, b, c), (a, b), (a), () )。
例如,假设现在想按时间层次关系:订单年份 > 订单月份 > 订单日,以这样的关系来定义所有分组集,并为每个分组集返回其总订货量。
-- 如果使用 GROUPING SETS从属子句,就得显式列出所有可能的4个分组集:
GROUPING SETS(
(YEAR(orderDate), MONTH(orderDate), DAY(orderDate)),
(YEAR(orderDate), MONTH(orderDate)),
(YEAR(orderDate)),
() )
-- 而使用逻辑上等效的ROLLUP从属子句,则要更精简得多:
SELECT YEAR(orderDate) AS orderYear
MONTH(orderDate) AS orderMonth,
DAY(orderDate) AS orderday,
SUM(qty) As sumQty
FROM dbo.Orders
GROUP BY ROLLUP(YEAR(orderDate), MONTH(orderDate), DAY(orderDate));在 SQL Server的早期版本中, ROLLUP也有一个非标准的“前身”——非标准的 WITH ROLLUP选项。标准的 GROUPING SETS、CUBE及ROLLUP从属子句比非标准的CUBE和ROLLUP选项更加灵活。可以在同一 GROUP BY子句中组合多个标准的从属子句,从而实现各种各样有趣的功能。而使用非标准的选项,每个查询只能限于使用一个选项。
GROUPING 和 GROUPING_ID 函数
如果一个查询定义了多个分组集,可能还想把结果行和分组集关联起来,也就是说,为每个结果行标识出它是和哪个分组集关联的。只要所有分组元素都定义为NOT NULL,实现这个要求就不难。例如,考虑如下查询:
SELECT empId, custId, SUM(qty) AS sumQty
FROM dbo.Orders
GROUP BY CUBE(empId, custId);因为 Orders表的empId和custId列都定义为NOT NULL,因此这些列中的NULL值只代表个占位符,表示该列并不属于当前的分组集。所以,所有empId和custId均不为NULL的行都与分组集(empId, custId)相关联;所有 empId不为NULL、custId为NULL的行都与分组集(empId)有关联,以此类推。有些人使用ALL或其他类似的标志来代替NULL(假设原始列不允许为NULL),这种做法对生成报表很有用。
但是,如果表中的分组列定义为允许取NULL值,这时就无法区分结果集中的NULL是来自原始数据,还是占位符(表示该列不是分组集的成员)。如果想以确定性的方式来判断分组集的关联(即使分组列允许为NULL),一种方法就是使用 GROUPING函数。这个函数接受一个列名,如果该列是当前分组集的成员,就返回0,否则返回1。例如,以下査询为每个分组元素调用 GROUPING函数:
SELECT GROUPING(empId) AS grpEmp,
GROUPING(custId) AS grpCust,
empId, custId, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empId, custId);这样就不需要再依靠NULL来计算结果行和分组集之间的关联了。
SQL Server 2008引入了一个名为GROUPING_ID的函数,进一步简化了关联结果行和分组集的处理。可以把任何分组集中的所有元素作为 GROUPING_ID的输入(例如,GROUPING_ID(a, b, c, d)),这个函数返回一个整数位图(integer bitmap),该整数的每一位代表一个不同的输入元素(最右边的位代表最右边的元素)。例如,分组集(a, b, c, d)可以用整数0 ($0\times 2^3 + 0\times 2^2 + 0\times 2^1 + 0\times 2^0$)表示,而分组集(a, c)则可以用整数5 ( $0\times 2^3 + 1\times 2^2 + 0\times 2^1 + 1\times 2^0$)表示,以此类推。
除了像在前一个查询中那样为每个分组元素调用 GROUPING函数,也可以只调用一次ROUPING_ID函数,将所有分组元素作为该函数的输入,如下所示:
SELECT GROUPING_ID(empId, custId) AS groupingSet,
empId, custId, SUM(qty) AS sumQty
FROM dbo.Orders
GROUP BY CUBE(empId, custId);数据修改
插入数据
INSERT VALUES 语句
INSERT VALUES语句可以将基于指定值的行插入表。在tempdb数据库中创建一个名为Orders表进行操作(在dbo架构中),用于演示语句。请运行以下代码以创建 Orders表:
USE tempdb;
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
CREATE TABLE dbo.Orders
(
orderId INT NOT NULL
CONSTRAINT PK_orders PRIMARY KEY,
orderDate DATE NOT NULL
CONSTRAINT DFT orderdate DEFAULT(CURRENT_TIMESTAMP),
empId INT NOT NULL,
custId VARCHAR(10) NOT NULL
)
-- 使用INSERT VALUES语句向Orders表中插入一行:
INSERT INTO dbo.Orders(orderId, orderDate, empId, custId)
VALUES(10001, '20090212', 3, 'A');紧接着表名之后,可以指定目标列的名称。虽然显式地指定列名是可选的,但这样做可以对语句中指定的列值和列名之间的关联关系进行控制,而不必单纯地依赖在定义表时(或者在对表结构进行最后一次修改以后)各个列的出现顺序。
如果为某个列指定了一个值, Microsoft SQL Server将使用这个值。如果没有为某个列指定取值, SQL Server将检查是否为该列定义了默认值。如果定义了默认值,则使用该默认值。如果没有定义默认值,但该列允许为NULL值,则为该列使用NULL值。如果在INSERT语句中既没有为某个列指定一个值,也没有什么机制能让它自动获取一个值,这个 INSERT语句的执行就会失败。作为依赖默认值或表达式的一个例子,以下语句向Orders表插入一行没有为 orderdate列指定值的记录,但由于已经为这个列定义了一个默认表达式(CURRENT TIMESTAMP),在这种情况下就使用这个默认值:
INSERT INTO dbo.Orders(orderId, empId, custId)
VALUES(10002, 5, 'B');SQL Server 2008增强了VALUES语句的功能,允许在一条语句中指定由逗号分隔开的多行记录。如下:
INSERT INTO dbo.Orders(orderId, orderDate, empId, custId)
VALUES (10003, '20090213', 4, 'B'),
(10004, '20090214', 1, 'A'),
(10005, '20090213', 1, 'C'),
(10006, '20090215', 3, 'C');上面这个语句是作为原子操作(atomic operation)而处理的,这意味着如果有任何一行在插入表时失败,那么语句中的所有行都不会插入表。
SQL Server 2008不仅增强了INSERT VALUES语句,而且还增强了VALUES子句本身的功能,现在可以用它来构建虚拟表(virtual table)。这种功能称为行值构造函数(Row Value Constructor)或表值构造函数(Table Value Constructor),是符合SQL标准的一种用法。这意味着在SQL Server 2008中可以定义一个基于 VALUES子句的表表达式。下面这个例子就是对一个基于 VALUES子句而定义的派生表进行查询:
SELECT *
FROM (VALUES
(10003, '20090213', 4, 'B'),
(10004, '20090214', 1, 'A'),
(10005, '20090213', 1, 'C'),
(10006, '20090215', 3, 'C'))
As O(orderId, orderDate, empId, custId);INSERT SELECT 语句
INSERT SELECT语句可以将一组由SELECT査询返回的结果行插入目标表中。它的语法和INSERT VALUES语句非常相似,只不过这里是用SELECT査询代替了VALUES子句。
如果想在SQL Server 2008之前版本的 SQL Server中构建一个基于常量值的虚拟表,就不得不使用多个SELECT语句,由每个 SELECT语句返回一个基于常量值的行,再用UNION ALL集合运算把各行合并到一起。如前所述, SQL Server 2008支持表值构造函数,所以实际上不必再使用这种技术了。
在 SQL Server 2008之前的版本中,几乎所有的INSERT SELECT操作都进行完整模式的日志处理(也就是说,所有操作都写入数据库的事务日志)。和以最小方式记录日志的操作相比,以完整模式记录日志的操作可能会相当慢。和以前的版本相比, SQL Server 2008能够在更多的场合中支持以最小方式记录日志的操作,包括INSERT SELECT语句。
INSERT EXEC 语句
INSERT EXEC语句可以把存储过程或动态SQL批处理返回的结果集插入目标表。有关存储过程、批处理及动态SQL的内容将在第10章“可编程对象”中介绍。
例如,以下代码在TSQLFundamentals2008数据库中创建一个名为Sales.usp_getOrders的存储过程,返回要发货到指定输入国家(@country 参数)的订单:
USE TSQLFundamentals2008;
IF OBJECT_ID('sales.usp_getOrders', 'P') IS NOT NULL
DROP PROC Sales.usp_getOrders;
GO
CREATE PROC Sales.usp_getOrders
@country AS NVARCHAR(40)
AS
SELECT orderId, orderDate, empId, custId
FROM Sales.Orders
WHERE shipCountry = @country;
GO
EXEC Sales.usp_getOrders @country = 'France';使用INSERT EXEC语句,可以把该存储过程返回的结果集插入 tempdb数据库的dbo.Orders表:
USE tempdb;
INSERT INTO dbo.Orders(orderId, orderDate, empId, custId)
EXEC TSQLFundamentals2008 Sales.usp_getOrders @country = 'France';SELECT INTO 语句
SELECT INTO语句的作用是创建一个目标表,并用查询返回的结果来填充它。SELECT INTO语句不是一个标准的SQL语句,也就是说,它不是 ANSI SQL标准的一部分。不能用这个语句向已经存在的表中插入数据。按照语法,只要简单地将INTO<目标表名称>加到用于生成结果集的SELECT查询的FROM子句前面就可以了。例如,以下代码在tempdb数据库中创建一个名为dbo.Orders的表,并用TSQLFundamentals2008数据库中Sales.Orders表的所有行填充这个新表:
USE tempdb;
IF OBJECT_ID('dbo.Orders','u') IS NOT NULL
DROP TABLE dbo.Orders;
SELECT orderId, orderDate, empId, custId
INTO dbo.Orders
FROM TSQLFundamentals2008.Sales.Orders;SELECT INTO语句会复制来源表的基本结构(包括列名、数据类型、是否允许为NULL及 IDENTITY属性)和数据。不过,SELECT INTO语句不会复制3样东西:约束、索引及触发器。如果目标表中需要这些东西,则需要亲自创建它们。
SELECT INTO语句的一个优点是:只要不把一个名为恢复模式(Recovery Model)的数据库属性设置成FULL(完整恢复模式),SELECT INTO就会按最小日志记录模式来执行操作。与完整日志记录模式相比,在最小日志记录模式下可以进行非常快速的操作。
如果想使用带有集合操作的 SELECT INTO语句,应该把INTO子句放在第一个査询的FROM子句之前。例如,下面的 SELECT INTO语句创建一个名为 Locations的表,并用一个EXCEPT集合操作的结果来填充这个新表,该集合操作返回的是客户地址,但不是雇员地址的那些行:
USE tempdb;
IF OBJECT_ID('dbo.Locations', 'U') IS NOT NULL
DROP TABLE dbo.Locations
SELECT country, region, city
INTO dbo.Locations
FROM TSQLFundamentals2008.Sales.Customers
EXCEPT
SELECT country, region, city
FROM TSQLFundamentals2008.HR.Employees;BULK INSERT 语句
BULK INSERT语句用于将文件中的数据导入一个已经存在的表。在这个语句中,须要指定目标表、源文件及一些选项。可以指定的选项很多,包括数据文件的类型(例如,是字符格式(char),还是本机数据库类型(native) )、字段终止符和行终止符,所有这些选项都有完整的文档说明。
例如,以下代码将文件”c:\temp\orders.txt”中的数据大容量插入(bulk insert) tempdb的dbo.Orders表,同时指定数据文件类型为字符格式,字段终止符为逗号,行终止符为换行符(\t):
USE tempdb;
BULK INSERT dbo.Orders FROM 'c:\temp\orders.txt'
WITH (
DATAFILETYPE = 'char',
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n');IDENTITY 属性
在SQL Server中可以为列定义一个名为IDENTITY的属性(标识列),它是一个任意整数。当把值插入(INSERT)有标识列的表时,数据库引擎会根据列定义中提供的一个种子(seed, 第1个值)和增量(步长值)自动生成递增的标识值。通常是用这种属性生成代理键(surrogate key),这是一种由系统生成的键,而不是由应用数据派生出来的键。
例如,以下代码在tempdb数据库中创建一个名为dbo.T1的表:
USE tempdb;
IF OBJECT_ID('dbo.T1', 'U') IS NOT NULL
DROP TABLE dbo.T1;
CREATE TABLE dbo.T1
(
keyCol INT NOT NULL IDENTITY(1, 1) -- 种子值和增量值均为1
CONSTRAINT PK_T1 PRIMARY KEY,
dataCol VARCHAR(10) NOT NULL
CONSTRAINT CHK_T1_datacol CHECK(dataCol LIKE '[A-Za-z]%')
);在INSERT语句中,应该完全忽略标识列,就像它们在表中不存在一样。例如,以下代码向该表插入3行数据时,只为 dataCol列指定值:
INSERT INTO dbo.T1(dataCol) VALUES('AAAAA');
INSERT INTO dbo.T1(dataCol) VALUES('CCCCC');
INSERT INTO dbo.T1(dataCol) VALUES('BBBBB');当查询这个表时,自然可以通过标识列的列名来引用它(在这个例子中是 keycol)。SQL Server为引用标识列提供了一种更通用的格式: $identity。例如,以下使用通用格式来查询T1表中的标识列:
SELECT $identity FROM dbo.T1;当在表中新插入一行时, SQL Server会根据表中当前的标识值和增量生成一个新的标识值。如果需要获得这个新生成的标识值(例如,要在引用表中插入子行),可以查询以下两个函数:
@@identity@@identity函数是从以前版本遗留下来的功能,它返回会话最后生成的一个标识值,而不考虑任何作用域。SCOPE_IDENTITY()SCOPE IDENTITY()返回当前作用域(例如,同一存储过程)内会话生成的最后一个标识值。除非是一些非常特殊不需要关心作用域的情况,否则,应该总是使用SCOPE IDENTITY()函数。
例如,以下代码在T1表中插入一行,通过査询SCOPE SCOPE_IDENTITY函数以获得新生成的标识值,并将其赋值给一个变量,然后再查询该变量:
DECLARE @new_key AS INT;
INSERT INTO dbo.T1(dataCo1) VALUES('AAAAA');
SET @new_key = SCOPE_IDENTITY();
SELECT @new_key AS new_key;记住,@@identity和SCOPE_ IDENTITY()都是返回当前会话生成的最后一个标识值。二者都不受其他会话中插入操作的影响。不过,如果你想知道一个表当前的标识值(最后生成的值)而不考虑作用域,则应该使用IDENT_CURRENT函数,并将表名作为其输入参数。例如,从一个新的会话(不是运行先前INSERT语句的那个会话)中运行以下代码:
SELECT SCOPE_IDENTITY() AS [SCOPE_IDENTITY],
@@identity AS [@@identity],
IDENT_CURRENT('dbo.T1') AS [IDENT_CURRENT];@@identity和SCOPE_ IDENTITY返回的都是NULL,因为在运行查询的会话内还没有创建任何标识值。 IDENT_CURRENT的返回值是4,它返回的是表中当前的标识值,不用考虑这个标识值是在哪个会话中生成的。
如果导致当前标识值发生变化的INSERT语句插入失败,或者是该语句所在的事务(transaction)发生了回滚(roll back),表中当前标识值的变化并不会被撤销。这意味着,当你不在意标识值之间有间隔时,应该只依赖标识属性自动生成标识值;否则,应该考虑使用自己的替代机制。
标识属性需要注意的另一个重要地方是,不能在现有的列上增加或删除标识属性,只能用CREATE TABLE语句或旨在增加新列的ALTER TABLE语句,在定义列的同时一起定义标识属性。如果为INSERT操作涉及的表设置了一个名为IDENTITY INSERT的会话选项,SQL Server就可以允许在INSERT语句中显式地指定标识列的取值。不过,没有任何选项可以对标识列进行更新。
例如,以下代码演示了如何在T1表中插入一行数据,并显式指定这行的 keyCol列的取值为5:
SET IDENTITY_INSERT dbo.T1 ON; -- 设置了一个名为IDENTITY INSERT的会话选项
INSERT INTO dbo.T1(keyCol, dataCol) VALUES(5, 'FFFFF');
SET IDENTITY_INSERT dbo.T1 OFF;有趣的是,只有当为标识列显式提供的值大于表的当前标识值时, SQL Serverオ会改变表的当前标识值。
标识属性本身并不会强制限制标识列的唯一性,理解这一点很重要。前面已经说过,当把 IDENTITY INSERT选项设置为ON以后,就可以为标识列显式地指定自己需要的值,但这些值有可能在表的某些行中已经存在了。此外,可以使用DBCC CHECKIDENT命令来重设(reseed)表的当前标识值。有关 DBCC CHECKIDENT命令语法的细节,请参考SQL Server联机从书的“ DBCC CHECKIDENT( Transact-SQL)”一文。总之,标识属性并不会强制实施唯一性约束。如果想要保证标识列的唯一性,可以在标识列上另外同时定义一个主键或唯一性约束。
删除数据
TSOL提供了两个从表中删除数据行的语句:DELETE和TRUNCATE。本节就重点介绍这两个语句。
运行以下代码以创建并填充Customers表和Orders表:
USE tempdb;
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL
DROP TABLE dbo.Customers;
SELECT * INTO dbo.Customers FROM TSQLFundamentals2008.Sales.Customers;
SELECT * INTO dbo.Orders FROM TSQLFundamentals2008.Sales.Orders;
ALTER TABLE dbo.Customers ADD
CONSTRAINT PK_Customers PRIMARY KEY(custId);
ALTER TABLE dbo.Orders ADD
CONSTRAINT PK_orders PRIMARY KEY(orderId),
CONSTRAINT FK_Orders_Customers FOREIGN KEY(custId)
REFERENCES dbo.Customers(custId);DELETE 语句
DELETE语句只有两个子句:用于指定目标表名的FROM子句和用于指定谓词条件的WHERE子句。
DELETE语句采用的是完整模式的日志处理,当删除大量数据时,可能会花费大量时间。
TRUNCATE 语句
TRUNCATE语句不是标准的SQL语句,它用于删除表中的所有行。与DELETE语句不同,TRUNCATE不需要过滤条件。例如,要刑除dbo.TI表的所有行,可以使用以下代码:
TRUNCATE TABLE dbo.T1;和DELETE语句相比,TRUNCATE具有的优点是:TRUNCATE以最小模式记录日志,而DELETE则以完整模式记录日志,二者在性能方面有巨大差异。例如,对于一个包含数百万行记录的表,要删除表中的所有行,如果用 TRUNCATE语句,操作在几秒钟内就能完成:如果用 DELETE语句,操作可能要花费几分钟,甚至几个小时。
当表中有标识列时,TRUNCATE和DELETE在功能上也有所不同。TRUNCATE会把标识值重置为最初的种子(seed),而 DELETE则不会。
当目标表是由外键约束引用的表时,SQL Server将不允许对这样的表使用TRUNCATE语句,即使引用表(referencing table)为空或外键被禁止也是如此。这时要使用TRUNCATE语句,唯一的办法就是删除正在引用目标表的所有外键。
TRUNCATE语句的执行速度非常快,因而有时具有一定的危险。当清空表的内容或删除表时,搞错了要操作的表,类似的事故时有发生。例如,假设你现在同时打开了与产品环境和开发环境相连的两个连接,但提交代码时使用了错误的连接。 TRUNCATE和DROP语句执行得如此迅速,以至于当你意识到错误时,事务已经提交了。为了避免发生这样的事故,可以简单地创建一个虚拟表(dummy table),让虚拟表包含一个指向产品表的外键,这样就可以保护产品表了。甚至还可以禁用虚拟表的外键,以便让虚拟外键不会对性能产生任何影响。如前所述,即使虚拟外键被禁用,它也能够阻止清空被引用表的内容或删除被引用表。
基于连接的 DELETE
T-SQL支持一种基于连接的DELETE语法,这不是一种标准的SQL语法。连接意味着,可以根据对另一个表中相关行的属性定义的过滤器来删除表中的数据行。
例如,以下语句将删除美国客户下的订单:
USE tempdb;
DELETE FROM O
FROM dbo.Orders AS O
INNER JOIN dbo.Customers AS C
ON 0.custId =C.custId
WHERE C.country= 'USA';这个语句和 SELETE语句非常相似, DELETE语句在逻辑上第一个处理的子句是FROM子句(在这个语句的第二行出现)。接着处理的是 WHERE子句处理,最后是 DELETE子句。DELETE语句中基于连接的两个FROM子句可能令人费解。但当开发这段代码时,可以把它当成好像是在开发一个带有连接的 SELETE语句。也就是说,先从带有连接的FROM子句着手,然后转到WHERE子句,最后不是指定 SELECT子句,而是指定一个 DELETE子句,并提供要删除的目标表在连接中的别名。
如前所述,基于连接的DELETE语句不是标准的SQL语句。如果要使用标准代码,可以用子査询来代替连接。例如,以下DELETE语句用子查询也可以完成相同的任务:
DELETE FROM dbo.Orders
WHERE EXISTS
(SELECT *
FROM dbo.Customers AS C
WHERE Orders.custId = C.custId
AND C.country = 'USA');更新数据
本节提供的例子需要对tempdb数据库中创建的Orders表和OrderDetails表进行操作。运行以下代码,以创建并填充这两个表:
USE tempdb;
IF OBJECT_ID('dbo.OrderDetails', 'U') IS NOT NULL
DROP TABLE dbo.OrderDetails;
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
SELECT * INTO dbo.Orders FROM TSQLFundamentals2008.Sales.Orders;
SELECT * INTO dbo.Orderdetails FROM TSQLFundamentals2008.Sales.OrderDetails;
ALTER TABLE dbo.Orders ADD
CONSTRAINT PK_Orders PRIMARY KEY(orderId)
ALTER TABLE dbo.OrderDetails ADD
CONSTRAINT PK_OrderDetails PRIMARY KEY(corderId, productId),
CONSTRAINT FK_OrderDetails_Orders FOREIGN KEY(orderId)
REFERENCES dbo.Orders(orderId);UPDATE 语句
UPDATE语句是标准SQL语句,用于对表中数据行的一个子集进行更新。为了标识作为更新目标的子集行,需要在WHERE子句中指定一个谓词。在SET子句中指定要更改的列和这些列的新值(或表达式),各列之间用逗号分隔。
当然,在进行更新操作前后,可以通过一个具有相同过滤条件的SELECT语句来查看变化。在本章最后还将介绍另一种査看变化的方法:在修改语句的后面使用一个名为OUTPUT的子句。
SQL Server 2008引入了对复合赋值运算符(compound assignment operator)的支持:+=、-=、*=、/=及%=。
用同时操作(第2章单表查询)的思想,你能想出交换col1和col2列值的UPDATE语句是怎样写的吗?在大多数编程语言中,表达式和赋值语句按特定的顺序(通常是从左到右)执行,在这种情况下要交换两个变量,需要一个临时变量。然而,因为在SQL中所有赋值表达式好像都是同时进行计算的,解决这个问题就非常简单:
UPDATE dbo.T1
SET col1 = col2, co12 = coll; -- SET子句中指定要更改的列和这些列的新值(或表达式),各列之间用逗号分隔基于连接的 UPDATE
与DELETE语句类似,T-SQL也支持一种基于连接的UPDATE语法,这不是标准SQL语法。和基于连接的DELETE语句一样,连接在此处也起过滤作用。
在UPDATE关键字之后指定要更新的目标表的别名,然后在SET子句中指定要更改的列和这些列的新值。例如,如下的UPDATE语句为客户1下的订单中的所有商品增加5%的折扣:
UPDATE OD
SET discount += 0.05
FROM dbo.OrderDetails AS OD
INNER JOIN dbo.Orders AS O
ON OD.orderId = O.orderId
WHERE custId = 1;
-- 标准代码通过子查询实现,【推荐】
UPDATE dbo.OrderDetails
SET discount += 0.05
WHERE EXISTS
(SELECT * FROM dbo.Orders AS o
WHERE O。orderId = orderDetails.orderId
AND custId = 1);推荐使用标准代码。不过,在某些情况下,使用连接比使用子查询在性能上更具优势。除了过滤作用,通过连接还可以访问其他表的属性(列),并在SET子句中使用这些属性为列赋值。所以,连接中对其他表的同一访问既可以用于过滤目的,也可以用于在赋值表达式中获取来自其他表的列值。然而,如果使用子査询的方法,每个子查询都是独立地访问另一个表(至少 SQL Server引擎目前就是这样处理子查询的)例如,考虑以下基于连接的非标准 UPDATE语句:
UPDATE T1
SET col1 = T2.Col1,
col2 = T2.co12,
col3 = T2.col3
FROM dbo.T1
INNER JOIN dbo.T2
ON T2.keyCol = T1.keyCol
WHERE T2.Col4 = 'ABC';
-- 如果非要使用标准代码,用子查询来实现这个任务,最终会产生如下冗长的查询语句
UPDATE dbo.T1
SET col1 = (SELECT Col1
FROM dbo.T2
WHERE T2.keyCol = T1.keyCol),
col2 = (SELECT Co12
FROM dbo.T2
WHERE T2.keyCol = T1.keyCol),
co13 = (SELECT co13
FROM dbo.T2
WHERE T2.keyCol = T1.keyCol)
WHERE EXISTS
(SELECT *
FROM dbo.T2
WHERE T2.keyCol = T1.keyCol
AND T2.Col4 = 'ABC');ANSI SQL支持一种称为行构造函数(也称为向量表达式)的功能,SQL Server 2008只实现了其中的部分功能。行构造函数的很多方面在SQL Server中还没有实现,这其中包括在UPDATE语句的SET子句中使用行构造函数的功能,如下所示:
UPDATE dbo.T1
SET (col1, col2, co13) =
(SELECT col1, col2, col3
FROM dbo.T2
WHERE T2.keyCol = T1.keyCol)
WHERE EXISTS
(SELECT *
FROM dbo.T2
WHERE T2.keyCol = T1.keyCol
AND T2.Col4 = 'ABC');赋值 UPDATE
T-SQL支持一种特有的UPDATE语法,可以在对表中的数据进行更新的同时为变量赋值。这种语法使你不须要使用单独的 UPDATE和 SELECTI语句,就能完成同样的任务。
使用这种语法的一种常见情况是:当由于某种原因,标识列不能满足需要时,就得维护一种自定义的序列/自动编号机制,这时就能用到这种语法。其思想是把最后用过的值保存在一个表中,然后使用这种特殊的UPDATE语法来增加表中的值,并把新值赋给一个变量。
运行以下代码,先创建一个Sequence表(具有一个名为val的列),然后为这个表填充一行,其中的val列为0(该值小于你想使用的第一个值):
USE tempdb;
IF OBJECT_ID('dbo.Sequence', 'U') IS NOT NULL
DROP TABLE dbo.Sequence;
CREATE TABLE dbo.Sequence(val INT NOT NULL);
INSERT INTO dbo.Sequence VALUES(0);现在,当须要得到一个新的序列值时,可以使用以下代码:
DECLARE @nextVal AS INT;
UPDATE Sequence
SET @nextVal = val += 1; -- SET子句中的赋值表达式【从右向左执行】
SELECT @nextVal;使用这种特殊语法的UPDATE语句是作为原子操作而运行,因为它只须要访问一次数据,所以比使用单独的UPDATE和SELECT语句的效率要更高。
合并数据
SQL Server 2008引入了一个称为MERGE的语句,它能在一条语句中根据逻辑条件对数据进行不同的修改操作( INSERT、UPDATE和DELETE)。MERGE语句是SQL标准的一部分,而T-SQL版本的MERGE语句也增加了一些非标准的扩展。
一个MERGER语句实现的功能通常可以转换成SQL Server早期版本的多个其他DML语句( INSERT, UPDATE, DELETE)的组合来实现。和其他方法相比,使用 MERGE语句的好处是:用较少的代码就可以表达需求,提高查询性能,因为它可以更少地访问查询涉及表。
为了演示MERGE语句,本节的例子将使用Customers表和CustomersStage表。运行如下代码来创建这两个表,并为它们填充示例数据。
USE tempdb;
IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL
DROP TABLE dbo.Customers;
Go
CREATE TABLE dbo.Customers
(
custId INT NOT NULL,
companyName VARCHAR(25) NOT NULL,
phone VARCHAR(20) NOT NULL,
address VARCHAR(50) NOT NULL,
CONSTRAINT PK_Customers PRIMARY KEY(custId)
);
INSERT INTO dbo.Customers(custId, companyName, phone, address)
VALUES
(1, 'cust 1', '(111) 111-1111', 'address 1'),
(2, 'cust 2', '(222) 222-2222', 'address 2'),
(3, 'cust 3', '(333) 333-3333', 'address 3'),
(4, 'cust 4', '(444) 444-4444', 'address 4'),
(5, 'cust 5', '(555) 555-5555', 'address 5');
IF OBJECT_ID('dbo.CustomersStage','u') IS NOT NULL
DROP TABLE dbo.CustomersStage;
CREATE TABLE dbo.CustomersStage
(
custId INT NOT NULL,
companyName VARCHAR(25) NOT NULL,
phone VARCHAR(20) NOT NULL,
address VARCHAR(50) NOT NULL,
CONSTRAINT PK_CustomersStage PRIMARY KEY(custId)
);
INSERT INTO dbo.CustomersStage(custId, companyName, phone, address)
VALUES
(2, 'AAAAA', '(222) 222-2222', 'address2'),
(3, 'cust 3', '(333) 333-3333', 'address 3'),
(5, 'BBBBB', 'CCCCC', 'DDDDD'),
(6, 'cust 6 (new)', '(666) 666-6666', 'address 6'),
(7, 'cust 7 (new)', '(777) 777-7777', 'address 7');本节将将要演示的第一个MERGE语句的例子是把CustomersStage表(来源表)中的内容合并到Customers表(目标表)中。更具体地说,假设现在想增加一些还不存在的客户,并更新已经存在的客户属性。
在MERGE子句中指定目标表的名称,在USING子句中指定来源表的名称。可以通过在ON子句中指定谓词来定义合并条件,这一点非常像连接。合并条件用于定义来源表中的哪些行在目标表中有匹配,哪些行没有匹配。在 MERGE语句中既可以在WHEN MATCHEDE THEN子句中定义当找到匹配时要进行的操作,也可以在WHEN NOT MATCHED THEN子句中定义当没有找到匹配时要进行的操作。
以下是第一个关于 MERGE语句的例子:增加还不存在的客户,并更新已经存在的客户:
MERGE INTO dbo.Customers AS TGT
USING dbo.CustomersStage AS SRC
ON TGT.custId = SRC.custId
WHEN MATCHED THEN
UPDATE SET
TGT.companyName = SRC.companyName,
TGT.phone = SRC.phone,
TGT.address = SRC.address
WHEN NOT MATCHED THEN
INSERT (custId, companyName, phone, address)
VALUES (SRC.custId, SRC.companyName, SRC.phone, SRC.address);WHEN MATCHED子句用于定义当目标表的一个行和来源表的一个行能够匹配时应该采取的操作。WHEN NOT MATCHED子句用于定义当目标表中没有行能够和来源表中的行进行匹配时应该采取的操作。T-SQL还支持第3种子句WHEN NOT MATCHED BY SOURCE,它用于定义对于目标表的一个行,在来源表中没有与之匹配的行时应该采取的操作。例如,假设现在想为前面的MERGE例子增加以下逻辑处理:当目标表中的某一行在来源表中找不到匹配行时,就删除目标表中的这一行。需要做的只是増加一个带有DELETE操作的WHEN NOT MATCHED BY SOURCE子句,如下所示:
MERGE dbo.Customers AS TGT
USING dbo.CustomersStage AS SRC
ON TGT.custId = SRC.custId
WHEN MATCHED THEN
UPDATE SET
TGT.companyName = SRC.companyName,
TGT.phone = SRC.phone,
TGT.address = SRC.address
WHEN NOT MATCHED THEN -- 不存在匹配时,将【来源表】中的数据行插入目标表
INSERT (custId, companyName, phone, adress)
VALUES (SRC.custId, SRC.companyName, SRC.phone, SRC.address);
WHEN NOT MATCHED BY SOURCE THEN -- 在【来源表】中找不到匹配行
DELETE;回到前面第一个MERGE例子,在这个例子中需要更新已经存在的客户和增加不存在的客户,可以看到,这个例子使用的方法并不是最有效的。在重写现有客户的属性之前,语句没有检查列值是否真的发生过变化。也就是说,即使来源表和目标表的行完全相同,仍然要修改客户行。用AND选项能够为不同的操作子句增加谓词条件,除了最初的条件以外,只有其他额外的谓词条件计算结果为TRUE时,才会执行相应的操作。在本例中,为了调整UPDATE操作,需要在WHEN MATCHED AND子句中增加一个谓词,以保证要修改的客户行中至少有一个属性发生过变化。完整的 MERGE语句如下所示:
MERGE dbo.Customers AS TGT
USING dbo.CustomersStage AS SRC
ON TGT.custId = SRC.custId
WHEN MATCHED AND
(TGT.companyName != SRC.companyName
OR TGT.phone != SRC.phone
OR TGT.address != SRC.address)
THEN UPDATE SET
TGT.companyName = SRC.companyName,
TGT.phone = SRC.phone,
TGT.address = SRC.address
WHEN NOT MATCHED THEN
INSERT (custId, companyName, phone, address)
VALUES (SRC.custId, SRC.companyName, SRC.phone, SRC.address);可以看到, MERGE语句的功能非常强大。与其他方法相比, MERGE语句在表达修改的逻辑处理时使用的代码更少,但在性能上更强。
虽然通常都是在需要根据逻辑条件来采取不同的操作的情况下,才会考虑使用MERGE语句;但当需要根据一个核心谓词条件为TRUE就采取一种操作时,也可以使用 MERGE语句。换句话说,MERGE语句可以和WHEN MATCHED子句分开使用,而不必非得需要WHEN NOT MATCHED子句。
通过表表达式修改数据
SQL Server并没有限制在表表达式(派生表、CTE、视图及内联表值的UDF)中使用的操作只能是SELECT,相反,它允许在表表达式中使用其他DML语句(INSERT、UPDATE、DELETE及MERGE)。可以这么想:表表达式并不真正包含数据,它只是基础表中底层数据的一种反映。从这个角度来看,可以把对表表达式的修改看作是通过表表达式对底层表中数据的修改,就像使用 SELECT语句的表表达式一样。当使用数据修改语句时,同样也会对表表达式的定义进行扩展,所以实际操作还是对底层的表进行的修改。
通过表表达式修改数据须要满足以下逻辑限制,例如:
- 如果定义表表达式的查询需要对表进行连接,则在同一修改语句中的修改只能影响连接的一边,而不能同时影响连接的两边。
- 不能对作为计算结果的列进行更新; SQL Server不会尝试对值进行反向工程(或反向解析)。
- 如果表表达式中至少有一列没有赋值,也无论如何都不能自动获取其值(没有默认值,不允许为NUL,也没有 IDENTITY属性),则不能通过该表表达式向表中插入数据行。
在SQL Server 联机丛书中可以找到一些其他限制,可以看到,这些要求都有一定的意义。
通过表表达式修改数据,可以更好地调试和解决问题。例如,前述的一处代码包含以下UPDATE语句:
USE tempdb;
UPDATE OD
SET discount += 0.05
FROM dbo.OrderDetails AS OD
INNER JOIN dbo.Orders AS O
ON OD.orderId = O.orderId
WHERE custId = 1;假设为了解决问题,想先看看这个语句将要修改哪些行,但不真的进行修改。一种选择是修改代码,让它使用SELECT语句。解决了问题以后,再把代码修改回UPDATE语句。除了像这样在SELECT和UPDATE语句之间来回修改的方法以外,还可以简单地使用表表达式的方法。也就是说,可以在以上包含连接的SELECT语句基础上先定义一个表表达式,再对该表表达使用 UPDATE语句。
-- 使用CTE:
WITH C AS
(
SELECT custId, OD.orderId,
productId, discount, discount + 0.05 AS newDiscount
FROM dbo.OrderDetails AS OD
INNER JOIN dbo.Orders AS O
ON OD.orderId = O.orderId
WHERE custId = 1
)
UPDATE C
SET discount = newDiscount;
-- 使用派生表:
UPDATE D
SET discount = newDiscount
FROM (SELECT custId, OD.orderId
productId, discount, discount + 0.05 AS newDiscount
FROM dbo.OrderDetails AS OD
INNER JOIN dbo.Orders AS O
ON OD.orderId = O.orderId
WHERE custId = 1) AS D;**当使用表表达式时,解决问题就简单多了,因为总是可以把定义表表达式的SELECT语句单独分离出来再运行,这样就不会修改任何数据。**在这个例子中,使用表表达式只是为了方便。然而,对于某些问题,使用表表达式并不是选择与否的问题,而是必须使用。为了演示这个问題,将使用一个名为T1的表作为例子,以下代码用于创建和填充这个表:
USE tempdb;
IF OBJECT_ID('dbo.T1', 'U') IS NOT NULL
DROP TABLE dbo.T1;
CREATE TABLE dbo.T1(Col1 INT, Co12 INT);
INSERT INTO dbo.T1(col1) VALUES(10);
INSERT INTO dbo.T1(col1) VALUES(20);
INSERT INTO dbo.T1(col1) VALUES(30);假设现在想更新这个表,把col2列设置为一个包含ROW_NUMBER函数的表达式的结果。问题出现了,UPDATE语句的SET子句中不允许包含ROW_NUMBER函数。如下代码运行会报错:
UPDATE dbo.T1
SET col2 = ROW_NUMBER() OVER(ORDER BY COl1);为了避开这个问题,可以定义一个表表达式,由它返回须要更新的列(col2)和一个包含ROW_NUMBER函数的表达式的结果列(称为rowNum)。对表表达式进行查询的外部査询将是一个UPDATE语句,由它将col2列设置为rowNum。以下是用CTE方法实现的代码:
WITH C AS
(
SELECT col1, col2, ROW_NUMBER() OVER(ORDER BY col1) AS rowNum
FROM dbo.T1
)
UPDATE C
SET co12 = rowNum;带有 TOP 选项的数据更新
SQL Server 2008把对TOP选项的支持扩展到新增的MERGE语句。当使用TOP选项时,如果已经处理过的行数达到指定的数量或百分比后,SQL Server将会立即停止处理修改语句。不幸的是,与SELECT语句不同,不能为修改语句中的TOP选项指定逻辑上的ORDER BY子句。事实上,SQL Server最初访问到哪些行,修改操作就会影响到哪些行。
下面将使用tempdb数据库中的Orders表来演示带有TOP选项的修改操作,运行以下代码以创建这个表,并用示例数据填充该表:
USE tempdb;
IF OBJECT_ID('dbo.OrderDetails', 'U') IS NOT NULL
DROP TABLE dbo.OrderDetails;
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
SELECT * INTO dbo.Orders FROM TSQLFundamentals2008.Sales.Orders;下面这个例子演示了用带有TOP选项的 DELETE语句来删除Orders表的50行数据
DELETE TOP(50) FROM dbo.Orders;因为不允许为修改语句中的TOP选项指定逻辑上的ORDER BY子句,所以,上面这个査询就会有一定问题:无法控制将要删除哪50行数据。这个问题暴露了在修改语句中使用TOP选项的局限性。
当然,在实际应用中,通常会在意修改将影响哪些行,而不能有选择地修改哪些行。为了避开这个问题,可以借助表表达式来修改数据。可以在带有TOP选项的SELECT查询的基础上定义一个表表达式,这样就能用一个逻辑上的ORDER BY子句来定义各行之间的优先关系。接下来就要编写修改语句,在修改语句中再使用表表达式。
例如,以下代码将删除具有最小订单ID值的50个订单,而不是随机删除50行:
WITH C AS
(
SELECT TOP(50)
FROM dbo. Orders
ORDER BY orderid
)
DELETE FROM C;同样,以下代码将更新具有最大订单ID值的50个订单,将其freight列的值增加10:
WITH C AS
(
SELECT TOP(50)
FROM dbo.Orders
ORDER BY orderId DESC
)
UPDATE C
SET freight += 10.00;OUTPUT 子句
例如,考虑UPDATE语句,除了修改数据以外,对于发生更新的列,UPDATE语句还可以返回这个列更新之前和更新之后的值。在排除问题、审核等其他情况下,这样的功能很有用处。
SQL Server 2005引入了一个名为OUTPUT的子句,通过在修改语句中添加 OUTPUT子句,就可以实现从修改语句中返回数据的功能。在 OUTPUT子句中,可以指定希望从修改过的行中要返回的列和表达式。SQL Server2008还支持在新的MERGE语句中使用OUTPUT子句。
OUTPUT子句的考虑方式和SELECT子句非常像,也就是说,它们都是把想要返回的列或基于现有列的表达式依次列举出来。按照OUTPUT子句的语法,不同之处在于需要在列名之前加上inserted或deleted关键字。在INSERT语句中需要引用inserted,在DELETE语句中需要引用deleted。而在UPDATE语句中,如果需要更新前行的映像(Image),则引用deleted;如果需要更新后行的映像,则引用inserted。
对于在OUTPUT子句中请求的各个属性,它会把来自修改过的各行中的相应值作为结果集而返回,这一点和SELECT语句的处理非常像。如果想把结果集导入另一个表,可以增加一个INTO子句,并提供目标表的名称。如果既想把修改过的行返回给调用者,又想把这些数据导入另一个表,则可以指定两个OUTPUT子句(一个有INTO子句,另一个没有)。
带有 OUTPUT 的 INSERT 语句
当需要为包含标识列的表插入数据行,同时又想知道所有新生成的标识值时,在INSERT语句中使用OUTPUT子句将非常有用。 SCOPE_IDENTITY函数只能返回当前范围内会话最后生成的标识值,但对于一次插入多行(即一个行集)的 INSERT语句,如果要返回生成的所有标识值,SCOPE_IDENTITY函数就帮不上多少忙了。而有了OUTPUT子句,解决问题就非常简单了。为了演示这种技术,按如下代码创建表:
USE tempdb;
IF OBJECT_ID('dbo.T1', 'U') IS NOT NULL
DROP TABLE dbo.T1;
CREATE TABLE dbo.T1
(
keyCol INT NOT NULL IDENTITY(1, 1) CONSTRAINT PK_71 PRIMARY KEY,
dataCol NVARCHAR(40) NOT NULL
);假设现在想把对TSQLFundamentals2008数据库中HR.Employees表的一个查询结果插入T1表。为了返回由INSERT语句新产生的所有标识值,只要简单地增加一个OUTPUT子句,并指定想要返回的列:
INSERT INTO dbo.T1(dataCol)
OUTPUT inserted.keyCol, inserted.dataCol
SELECT lastName
FROM TSQLFundamentals2008.HR.Employees
WHERE country = 'USA';如前所述,也可以把结果集导入另一个表。该表可以是一个真实存在的表、临时表或一个表变量。如果把结果集保存在目标表中,则可以通过查询该表来操作这些数据。例如,以下代码首先声明一个名为@ NewRows的变量,然后将另一个结果集插入T1,最后将OUTPUT子句返回的结果集导入表变量。接着再用代码来查询该表变量,以显示存储到其中的数据:
DECLARE @NewRows TABLE(keyCol INT, dataCom NVARCHAR(40)); -- 表变量
INSERT INTO dbo.T1(dataCol)
OUTPUT inserted.keyCol, inserted.dataCol
INTO @NewRows
SELECT lastName
FROM TSQLFundamentals2008.HR.Employees
WHERE country = 'UK';
SELECT * FROM @NewRows;带有 OUTPUT 的 DELETE 语句
接下来,举例说明如何在DELETE语句中使用OUTPUT子句。
USE tempdb;
IF OBJECT_ID('dbo.orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
SELECT * INTO dbo.Orders
FROM TSQLFundamentals2008.Sales.Orders;以下代码将删除2008年之前下过的所有订单,并使用 OUTPUT子句返回被删除行中的一些列:
DELETE FROM dbo.Orders
OUTPUT
deleted.orderId,
deleted.orderDate,
deleted.empId,
deleted.custId
-- INTO ...
WHERE orderDate < '20080101';如果想对被删除的各行进行归档,只要简单地增加一个INTO子句,并指定用于归档的表名作为其目标表。
带有 OUTPUT 的 UPDATE 语句
在UPDATE语句中使用OUTPUT子句时,既可以通过将deleted关键字作为列名的前缀来引用被修改的行在发生变化之前的映像,也可以通过将inserted关键字作为列名的前缀来引用被修改的行在发生变化之后的映像。用这种方法就可以返回更新过的列的新、旧两个版本。
在演示如何在UPDATE语句中使用OUTPUT子句之前,先运行以下代码,在tempdb数据库中以dbo架构创建一个 TSQLFundamentals2008数据库中 Sales.OrderDetails表的复本:
USE tempdb;
IF OBJEC_ID('dbo.OrderDetails', 'U') IS NOT NULL
DROP TABLE dbo.OrderDetails;
SELECT * INTO dbo.OrderDetails
FROM TSQLFundamentals2008.Sales.Orderdetails;以下UPDATE语句为与产品51相关的所有订单详情增加5%的折扣,并使用OUTPUT子句从修改过的行中返回产品ID、原来的折扣值和新的折扣值:
UPDATE dbo.OrderDetails
SET discount += 0.05
OUTPUT
inserted.productId,
deleted.discount AS oldDiscount,
inserted.discount AS newDiscount
WHERE productId = 51;带有 OUTPUT 的 MERGE 语句
在MERGE语句中同样也可以使用OUTPUT子句,但要记得一个MERGE语句可以根据条件逻辑调用多个不同的DML操作。这意味着一个MERGE语句可能返回由不同DML操作生成的OUTPUT子句行。为了标识输出行由哪个DML操作生成,可以在OUTPUT子句中调用一个名为$Saction的函数,它会返回一个代表相应操作的字符串(“INSERT”、“UPDATE”及“DELETE”)。为了演示在MERGE语句中如何使用OUTPUT子句,这里将使用本章前面“合并数据”一节中的例子。为了运行这个例子,务必再次运行“合并数据”一节中的代码,重新在tempdb数据库中创建Customers表和CustomersStage表,并为其填充示例数据。
以下代码将CustomersStage表的内容合并到Customers表,如果客户已经在目标表中存在,则更新该客户的一些属性,否则将客户添加到目标表中:
MERGE INTO dbo.Customers AS TGT
USING dbo.CustomersStage AS SRC
ON TGT.custId = SRC.custId
WHEN MATCHED THEN
UPDATE SET
TGT.companyName = SRC.companyName,
TGT.phone = SRC.phone,
TGT.address = SRC.address
WHEN NOT MATCHED THEN
INSERT (custId, companyName, phone, address)
VALUES (SRC.custId, SRC.companyName, SRC.phone, SRC.address)
OUTPUT $action, inserted.custId,
deleted.companyName AS oldCompanyName,
inserted.companyName AS newCompanyName,
deleted.phone AS oldPhone,
inserted.phone AS newPhone,
deleted.address AS oldAddress,
inserted.address AS newAddress;以上MERGE语句使用OUTPUT子句返回被修改过的行的新、旧版本的值。当然,对于INSERT操作不存在旧版本的值,因此所有引用deleted的列都返回NULL。$action函数可以告诉我们输出行是由UPDATE,还是由INSERT操作生成的。
可组合的 DML
OUTPUT子句为每个修改过的行返回一个输出行。但是,如果出于审核的目的,只需要把修改过的行的一个子集导入一个表,应该怎么做呢?以前在SQL Server 2005中,必须先把所有行导入一个临时表(staging table),然后再将需要的子集行从临时表复制到审核表中。SQL Server 2008则引入了一种称为组合DML(composable DML)的功能,可以通过这种功能来跳过临时表的处理阶段,直接从被修改过的行的全部集合中将需要的子集行插入最终的目标表。
为了演示这种功能,先运行以下代码,在tempdb数据库以dbo架构创建一个Products表( TSQLFundamentals2008数据库的Production.Products表的复本)和ProductsAudit表:
USE tempdb;
IF OBJECT_ID('dbo.ProductsAudit', 'U') IS NOT NULL
DROP TABLE dbo.ProductsAudit;
IF OBJECT_ID('dbo.Products', 'U') IS NOT NULL
DROP TABLE dbo.Products;
SELECT * INTO dbo.Products FROM TSQLFundamentals2008.Production.Product;
CREATE TABLE dbo.ProductsAudit
(
LSN INT NOT NULL IDENTITY PRIMARY KEY,
TS DATETIME NOT NULL DEFAULT(CURRENT_TIMESTAMP),
productId INT NOT NULL,
colName SYSNAME NOT NULL,
oldVal SQL_VARIANT NOT NULL,
newVal SQL_VARIANT NOT NULL
);假设现在须要更新由供应商1提供的所有产品,将其价格提高15%。同样,还需要审核那些被更新的产品的原有价格和新价格,但只审核原来的价格低于20,而新价格高于或等于20的那些产品。
可以用组合DML来实现该这一需求。先编写一个带有OUTPUT子句的UPDATE语句,然后基于该UPDATE语句定义一个派生表。再写一个对派生表进行查询的INSERT SELECT语句,只筛选出需要的行。以下是解决方案的完整查询语句:
INSERT INTO dbo.ProductsAudit(productId, colName, oldVal, newVal)
SELECT productId, 'unitPrice', oldVal, newVal
FROM (UPDATE dbo.Products
SET unitPrice *= 1.15
OUTPUT
inserted.productId,
deleted.unitPrice AS oldVal,
inserted.unitPrice AS newVal
WHERE SupplierID = 1) AS D
WHERE oldVal < 20.0 AND newVal >= 20.0;事务和并发
事务
事务是作为单个工作单元而执行的一系列操作,如查询和修改数据,甚至可能是修改数据定义。
定义事务边界的方式有显式和隐式两种:
显式事务的定义需要以
BEGIN TRAN语句作为开始,如果想提交事务,则应该以COMMIT TRAN语句显式结束事务;如果不想提交事务(撤消事务中的修改),则应该以ROLLBACK TRAN语句显式结束事务。下面的例子将两个INSERT语句封装在由BEGIN TRAN和COMMIT TRAN定义的一个事务边界中:
BEGIN TRAN; INSERT INTO dbo.T1(keyCol, col1, co12) VALUES(4, 101, 'C'); INSERT INTO dbo.T2(keyCol, col1, co12) VALUES(4, 201, 'X'); COMMIT TRAN;如果不显式定义事务的边界,SQL Server会默认把每个单独的语句作为一个事务;换句话说, SQL Server默认在执行完每个语句之后就自动提交事务。
提示:通过查询@@TRANCOUNT函数,在代码的任何位置都可以用编程方式来判断当前是否位于一个打开的事务当中。如果不在任何打开的事务范围内,则该函数返回0;如果在某个打开的事务范围内,则返回一个大于0的值。
可以通过IMPLICIT_TRANSACTIONS会话选项来改变 SQL Server处理隐式事务的方式。该选项默认是OFF。当把这个选项设置为ON时,就不必用BEGIN TRAN语句来标明事务开始,但每个事务仍需要以COMMIT TRAN或ROLLBACK TRAN语句来标明事务完成。
事务必须有四个属性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),这4个属性的首字母可以缩写为ACID。
原子性 (Atomicity)
事务必须是是原子工作单元。这意味着在事务中进行的修改,要么全都执行,要么全都不执行。如果在事务完成之前(在提交指令被记录到事务日志之前)系统出现故障或是重新启动,SQL Server将会撤消在事务中进行的所有修改。同样,如果在事务处理中遇到错误, SQL Server通常会自动回滚事务,但是也有少数例外。一些不太严重的错误不会引发事务的自动回滚,例如主键冲突(primary key violation)、锁超时(在本章后面会讨论这个问题)等。可以使用错误处理代码来捕获这些错误,并采取某种操作(例如,把错误记录在日志中,再回滚事务)。第10章“可编程对象”概述如何用代码进行错误处理。
一致性 (Consistency)
事务的一致性这个术语指的是,同时发生的事务在修改和查询数据时不发生冲突,通过 RDBMS访问的数据要保持一致的状态。可以想到,一致性是一个具有一定主观性的术语,取决于应用程序的需要。在本章后面的“隔离级别”一节中会介绍 SQL Server默认采用的一致性级别,以及如果默认的行为不适合实际应用时,如何对一致性进行控制。
隔离性 (Isolation)
隔离性是一种用于控制数据访问的机制,能够确保事务只访问处于期望的一致性级别下的数据。 SQL Server使用锁对各个事务之间正在修改和查询的数据进行隔离。本章后面的“锁”这一小节提供了有关隔离级别的更多细节。
持久性 (Durability)
在将数据修改写入到磁盘上数据库的数据分区之前,总是先把这些修改写入到磁盘上数据库的事务日志中。把提交指令记录到磁盘的事务日志中以后,即使数据修改还没有应用到磁盘的数据分区,也可以认为事务是持久化的。这时如果系统重新启动(正常启动或在发生系统故障之后启动), SQL Server会检查每个数据库的事务日志,进行恢复(recovery)处理。恢复处理一般包括两个阶段:重做阶段(redo)和撤消阶段(undo)。
- 在重做阶段,对于提交指令已经写入到日志,但数据修改还没有应用到数据分区的事务,数据库引擎会重做(replaying)这些事务所做的所有修改,这个过程也称为“前滚( rolling forward)”。
- 在撤消阶段,对于提交指令还没有记录到日志中的事务,数据库引擎会撤消(undoing)这些事务所做的修改,这个过程也称为“回滚(rolling back)”。
例如,以下代码定义了一个事务,把关于一个新订单的数据记录到TSQLFundamentals2008数据库中:
USE TSQLFundamentals2008;
-- 开始一个新的事务
BEGIN TRAN;
-- 声明一个变量
DECLARE @newOrderId AS INT;
-- 将一个新订单入到Sa1es.Orders表
INSERT INTO Sales.Orders
(custId, empId, orderDate, requiredDate, shippedDate,
shipperId, freight, shipName, shipAddress, shipCity,
shipPostalCode, shipCountry)
VALUES (85, 5, '20090212', '20090301', '20090216',
3, 32.38, 'Ship to 85-B', '6789 rue de 1''abbaye', 'Reims',
'10345', 'France');
-- 将新的订单ID保存在变量中(由于orderId列具有IDENTITY属性,所以在插入订单时, SQL Server会自动生成新的订单ID)
SET @newOrderId = SCOPE_IDENTITY();
-- 返回新的订单ID
SELECT @newOrderId AS newOrderId;
-- 将新订单的订单明细行插入到Sales.OrderDetai1s表
INSERT INTO sales.OrderDetails
(orderId, productId, unitPrice, qty, discount)
VALUES(@newOrderId, 11, 14.00, 12, 0.000);
INSERT INTO Sales.OrderDetails
(orderId, productId, unitPrice, qty, discount)
VALUES(@newOrderId, 42, 9.80, 10, 0.000);
INSERT INTO Sales.OrderDetails
(orderId, productId, unitPrice, qty, discount)
VALUES(@newOrderId, 72, 34.80, 5, 0.000);
-- 提交事务
COMMIT TRAN;注意,这个例子没有进行错误处理,因而也就没有提供出错时的 ROLLBACK(回滚)语句。为了进行错误处理,可以把事务封装在一个TRY/CATCH代码结构中。第10章概述了如何用代码进行错误处理。
操作完成后,运行以下代码清理测试数据:
DELETE FROM Sales.OrderDetails
WHERE orderId > 11077;
DELETE FROM Sales.Orders
WHERE orderId > 11077;
DBCC CHECKIDENT('Sales.Orders', RESEED, 11077); -- 【重设表的当前标识值】锁定和阻塞
SQL Server使用锁(lock)来实施事务隔离属性。本节将详细介绍锁定( locking)的相关细节,以及如何解决由冲突的锁定请求而引起阻塞的问题。
锁
锁是事务获取的一种控制资源,用于保护数据资源,防止其他事务对数据进行冲突的或不兼容的访问。这部分首先介绍SQL Server支持的几种重要的锁模式(lock mode)和它们的兼容性,接着再讲述可以锁定的资源类型。
锁模式及其兼容性
开始学习事务和并发性时,应该首先熟悉两种主要的锁模式——排他锁(exclusive lock)和共享锁(shared lock)。其他类型的锁模式(更新锁、意向锁、架构锁)是更高级的锁模式。
当试图修改数据时,事务会为所依赖的数据资源请求排他锁,一旦授予,事务将一直持有排他锁,直至事务完成。这种锁模式之所以称为排他锁,是因为对于相同的数据资源,如果有其他事务已经获得了该资源的任何类型的锁,就不能再获得该资源的排他锁;如果有其他事务已经获得了该资源的排他锁,就不能再获得该资源的任何类型的锁。这是修改行为的默认处理方式,而且这种默认行为不能改变一一不能改变为修改数据资源而请求的锁模式(排他锁),也不能改变持有锁的时间长度(直到事务完成)。
当试图读取数据时,事务默认会为所依赖的数据资源请求共享锁,读操作一完成,就立即释放资源上的共享锁。这种锁模式之所以称为共享锁,是因为多个事务可以同时持有同一数据资源上的共享锁。虽然当修改数据时不能改变请求的锁模式和持续时间,但当读取数据时可以对如何处理锁定进行控制。本章后面的“隔离级别”一节将对此作详细介绍。
事务之间的相互制约关系就是锁的兼容性。下表给出了排他锁和共享锁之间的兼容性,其中列代表已经授予的锁模式,行代表请求授予的锁模式。
| 请求模式 | 已经授予排他锁(X) | 已经授予共享锁(S) |
|---|---|---|
| 授予请求的排他锁? | 否 | 否 |
| 授予请求的共享锁? | 否 | 是 |
用简单的话来总结一下事务之间锁的相互制约关系:如果数据正在由一个事务进行修改,其他事务就既不能修改该数据,也不能读取(至少默认不能)该数据,直到第一个事务完成。如果数据正在由另一个事务读取,其他事务就不能修改该数据(至少默认不能)。
可锁定资源的类型
SQL Server可以锁定不同类型或粒度的资源,这些资源类型包括RID或KEY(行)、PAGE(页)、对象(例如表)、数据库等。行位于页中,而页则是包含表或索引数据的物理数据块。你应该先熟悉这些资源类型,到了更高级的阶段再去了解其他可锁定的资源类型,如 EXTENT(区)、分配单元(ALLOCATION_UNIT)、堆(HEAP)以及B树(B-tree)。
为了获得特定资源类型上的锁,事务必须先在更高的粒度级别上获得相同模式的意向锁。例如,为了获得某一行的排他锁,事务必须先在包含那一行的页上获取意向排他锁,并在包含那一页的数据对象上也获取意向排他锁。同样,要获得某一粒度级别上的共享锁,事务就必须先在更高的粒度级别上获取意向共享锁。意向锁的目的是为了在较高的粒度级别上有效地检测不兼容的锁定请求,防止授予不兼容的锁。例如,如果一个事务持有一个行锁,而其他事务想在包含那一行的整个页或表上请求不兼容的锁模式,这时SQL Server可以很容易地识别出这种冲突,因为第一个事务已经获取了相关页和表上的意向锁。意向锁不会干预较低粒度上的锁定请求。例如,一个页上的意向锁不会阻止其他事务在该页内的行上获取不兼容的锁模式。下表对锁兼容性的内容进行了扩展,增加了意向排它锁(IX锁, Intent Exclusive)和意向共享锁(IS锁)。
| 请求模式 | 已经授予排他锁(X) | 已经授予共享锁(S) | 已经授予意向排他锁(IX) | 已经授予意向共享锁(IS) |
|---|---|---|---|---|
| 授予请求的排他锁? | 否 | 否 | 否 | 否 |
| 授予请求的共享锁? | 否 | 是 | 否 | 是 |
| 授予请求的意向排他锁? | 否 | 否 | 是 | 是 |
| 授予请求的意向共享锁? | 否 | 是 | 是 | 是 |
SQL Server动态决定应该锁定哪种类型的资源。自然,为了获得理想的并发性,最好是只锁定需要的资源,即只锁定受影响的那些行。但是,锁定需要占用内存资源和内部的管理开销,所以 SQL Server在选择锁定哪种类型的资源时会同时考虑并发性和系统资源。
SQL Server可以会先获得细粒度的锁(例如,行或页),在某些情况下再尝试将细粒度的锁升级为更粗粒度的锁(例如,表)。例如,当单个语句获得至少5,000个锁时,就会触发锁升级;如果由于锁冲突而导致无法升级锁,则 SQL Server每当获取1,250个新锁时便会触发锁升级。
在 SQL Server 2008之前,不能显式地禁止锁升级,所以在表上总是会进行锁升级。在SQL Server 2008中,可以用ALTER TABLE语句为表设置一个LOCK_ESCALATION选项,以控制锁升级的处理方式。如果愿意,你可以禁止锁升级,或自己决定**锁升级是在表上进行(默认)**还是在分区(partition)上进行。表在物理上可以划分成多个更小的单元,即分区。
检测阻塞
如果一个事务持有某一数据资源上的锁,而另一事务请求相同资源上的不兼容的锁,则对新锁的请求将被阻塞,发出请求的事务进入等待状态。在默认情况下,被阻塞的请求会一直等待,直到原来的事务释放相关的锁。本章后面会介绍如何在会话中定义一个锁定超时期限,这样就可以限制被阻塞的请求在超时之前要等待的时间。
只要能够在合理的时间范围内满足请求,系统中的阻塞就是正常的。但是,如果一些请求等待了太长的时间,可能就需要手工排除阻塞状态,看看能采取什么措施来防止这样长时间的延迟。例如,事务的运行时间过长,会导致持有锁的时间也过久:这时可以尝试缩短事务处理,把不属于工作单元的操作移到事务外面。在某些情况下,应用程序中的bug也可能导致事务一直打开;这时可以先把这样的bug找出来,修复它,确保在所有情况下都可以关闭事务。
本节以一个阻塞情况为例,一步一步地教你如何排除这种阻塞。先在SSMS中打开3个单独的查询窗口(在本例中分别称这3个窗口为Connection 1、Connection 2 和 Connection 3)。确保把它们全都连接到TSQLFundamentals2008样例数据库。
在Connection 1中运行以下代码,对Production.Products表的一行进行更新,为产品2的当前单价19.00增加1.00:
BEGIN TRAN;
UPDATE Production.Products
SET unitPrice += 1.00
WHERE productId = 2;为了更新这一行,会话必须先获得一个排他锁,如果更新成功,SQL Server会向会话授予这个锁。回顾前面介绍的内容,事务会一直持有排他锁,直到事务完成;因为这个例子中的事务一直保持打开,所以它会一直持有排他锁。
在Connection 2中运行以下代码,试着查询同一行:
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;在默认情况下,为了读取数据,这个会话需要一个共享锁,但是因为这一行已经被其他会话持有的排他锁锁定,而且共享锁和排他锁不兼容,所以第二个会话被阻塞,进入等待状态。
假设系统中发生了这样的阻塞情况,而且被阻塞的对话最终等待了很长时间,你可能会想排除这种阻塞状况。在此,提供一些对动态管理对象(包括视图和函数)的查询,当排除阻塞时,可以在Connection 3中运行这些查询。
要得到有关锁的信息(包括已经授予的锁和当前会话正等待授予的锁),可以在Connection 3中查询动态管理视图(DMV, dynamic management view)sys.dm_tran_locks:
SELECT request_session_id AS SPID,
resource_type AS resType,
resource_database_id AS dbId,
DB_NAME(resource_database_id) AS dbName,
resource_description AS res,
resource_associated_entity_id AS resId,
request_mode AS mode,
request_status AS status
FROM sys.dm_tran_locks;当我运行这段代码(没有打开其他查询窗口)时,得到以下输出:
每个会话都由唯一的服务器进程标识符(SPID, server process ID)进行标识,可以通过查询@@SPID函数来查看会话的SPID。如果你正在使用SSMS,在屏幕底部的状态栏中显示了当前登陆的用户名,在用户名右边的圆括号内显示的就是当前会话的SPID,在已经连接到数据库的查询窗口的标题条中也能够找到SPID。
从对sys.dm_tran_lock进行查询的输出中可以看到,3个会话(61, 62, 63)目前都持有锁,具体包括以下信息:
- resType:被锁定资源的类型(例如,取值之一的KEY代表索引中的行锁)
- dbId & dbName:被锁定资源所位于的数据库的ID,可以用
DB_NAME函数把这个ID转换成相应的数据库名称 - res & resId:资源说明和与资源相关联的实体ID
- mode:锁模式
- status:已经授予了锁,还是会话正在请求授予锁
注意,以上只是该视图属性的一部分:建议査阅这个视图的其他属性,看看还能得到什么其他有关锁的信息。
在前面查询的输出中,可以观察到进程62正在等待请求TSQLFundamentals2008示例数据库中一个行上的共享锁(用DB_NAME函数获得数据库名称)。注意,进程61持有同行上的一个排他锁。如果你能观察到这两个进程锁定的行具有相同的res和resid值,就能意识到这一事实。沿着进程61或62的锁层次结构向上检查在包含那一行的页或对象(表)上的意向锁,便可以搞明白锁定所涉及到的表。用OBJECT_NAME函数能够把对象锁的resId属性列中出现的对象ID(此例中为709577566)转换为对象名称。你会发现锁定涉及到的表是Production.Product。
sys.dm_tran_locks视图只提供当前阻塞链中涉及到的进程的ID信息,除此之外没有其他关于进程的信息。为了获得与阻塞链中涉及到的进程相关联的连接的信息,可以查询一个名为sys.dm_exec_connections的动态管理视图,只筛选阻塞链中涉及到的那些SPlD:
SELECT session_id AS SPID,
connect_time,
last_read,
last_write,
most_recent_sql_handle
FROM sys.dm_exec_connections
WHERE session_id IN (61, 62);注意,这里指定的进程ID是我的系统中阻塞链涉及的进程D(61和62)。当你在系统中运行这里演示的查询时,要确保把进程ID替换成在你的系统阻塞链中找到的进程ID。
这个查询将返回以下输出结果:

这个査询给出的关于连接的信息包括以下内容:
connect_time:连接建立的时间
last_read & last_write:连接中最后一次发生读操作和写操作的时间
most_recent_sql_handle:一个二进制值标记(handle),用于代表此连接上执行的最后一个SQL批处理
可以把这个标记值作为输入参数提供给表函数
sys.dm_exec_sql_text,由这个函数返回该标记值代表的SQL代码。
査询表函数时可以显式地传递二进制标记值,但方便的方法可能是使用第5章”表表达式”中介绍的APPLY表运算符,为每个连接行应用这个表函数,如下所示(在Connection 3中运行):
SELECT session_id, text
FROM sys.dm_exec_connections
CROSS APPLY sys.dm_exec_sql_text(most_recent_sql_handle) AS ST
WHERE session_id IN(61, 62);运行以上査询,就可以在得到的输出中显示阻塞链涉及的每个连接最后调用的批处理代码:

以上显示了被阻塞进程(进程62)正在等待执行的代码,因为这是该进程最后执行的一个操作。对于阻塞进程来说,通过这个例子能够看到是哪条语句导致了问题,但要记住:阻塞进程可能在不断地运行,所以在代码中看到的最后一个操作不一定就是导致问题的语句。
对于阻塞状态中涉及到的会话,用动态管理视图sys.dm_exec_sessions也能找到很多有用的信息。以下査询返回的只是有关会话的可用属性中的一小部分:
SELECT session_id AS SPID,
login_time,
host_name,
program_name,
login_name,
nt_user_name,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions
WHERE session_id IN(61, 62);本例中的这个查询将返回以下输出:

这段输出提供的信息包含建立会话的时间(login_time)、特定于会话的客户端工作站名称(host name)、初始化会话的客户端程序的名称(program_name)、会话所使用的SQL Server登录名(login_name)、客户端的Windows用户名(nt_user_name)、最近一次会话请求的开始时间(last_request_start_time)、最近一次会话请求的完成时间(last_request_ end_time)。这些信息可以详细地告诉你会话正在做什么。
对于排除阻塞状态,另一个可能很有用的动态管理视图是sys.dm_exec_requests。这个视图的每一行代表一个活动的请求(包括被阻塞的请求)。实际上,可以容易地区分被阻塞请求,因为这些请求的blocking_session_id属性值大于0。例如,以下查询只筛选被阻塞的请求:
SELECT session_id AS SPID,
blocking_session_id,
command,
sql_handle,
database_id,
wait_type,
wait_time,
wait_resource
FROM sys.dm_exec_requests
WHERE blocking_session_id > 0;这个查询将返回以下输出:

从这些信息中可以容易地识别出阻塞链涉及到的会话、争用的资源、被阻塞会话等待了多长时间(以毫秒为单位)等信息。
如果需要终止导致阻塞的进程(例如,当你发现事务一直保持打开是由于程序中的bug造成的,而且程序中没有关闭事务的处理),可以使用**KILL <spid>命令**(现在先不要这样做)。
前面提到,在默认情况下会话不会设置锁定的超时期限。如果想限制会话等待锁释放的时间,则可以设置LOCK_TIMEOUT选项。该选项以毫秒为单位,即5000表示5秒,0表示立刻超时,-1(默认值)表示无限期等待,以此类推。为了演示这个选项,先终止Connection 2中进行的査询。然后运行以下代码,将会话的超时期限设置为5秒,再重新运行原来的查询:
SET LOCK_TIMEOUT 5000;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;因为Connection 1还没有完成更新的事务,所以这时Connection 2中的查询仍然将被阻塞,但如果超过5秒钟以后,锁定请求还不能被满足,SQL Server就会终止查询,返回以下错误消息:
消息 1222,级别 16,状态 51,第 4 行
已超过了锁请求超时时段。
注意锁定超时不会引发事务回滚。
为了取消锁定超时期限,将该选项设置回默认值(无限期等待),再次进行查询,在Connection 2中运行以下代码:
SET LOCK_TIMEOUT -1;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;为了演示终止Connection 1中的更新事务而产生的效果,在Connection 3中运行以下代码:
KILL 61;这个语句会引起Connection 1中事务的回滚(这意味着将会撤消产品单价从19.00到20.00的更新操作),同时释放排他锁。再回到Connection 2,这时查询将得到取消单价变化后的结果(即单价未改变时的值)。
隔离级别
隔离级别用于决定如何控制并发用户读写数据的操作。读操作可以是任何检索数据的语句,默认使用共享锁。写操作是指任何对表做出修改的语句,需要使用排他锁。对于操作获得的锁,以及锁的持续时间来说,虽然不能控制写操作的处理方式,但可以控制读操作的处理方式。当然,作为对读操作的行为进行控制的一种结果,也将隐含地影响写操作的行为方式。为此,可以在会话级别上用会话选项来设置隔离级别,也可以在查询级别上用表提示(table hint)来设置隔离级别。
可以设置的隔离级别有6个:READ UNCOMMITTED(未提交读)、READ COMMITTED(已提交读)(默认值)、REPEATABLE READ(可重复读)、SERIALIZABLE(可序列化)、SNAPSHOT(快照)和READ COMMITTED SNAPSHOT(已经提交读隔离)。最后两个级别是在 SQL Server2005中引入的。要设置整个会话的隔离级别,可以使用以下命令:
SET TRANSACTION ISOLATION LEVEL <isolation Name>;
-- 也可以使用【表提示】来设置查询的隔离级别:
SELECT ... FROM <table> WITH (<isolationName>);注意,使用会话选项时,如果隔离级别的名称是由多个单词组成的,则需要在各单词之间指定一个空格,例如REPEATABLE READ。而使用查询提示时,则不必在各单词之间指定任何空格,例如WITH (REPEATABLEREAD)。此外,一些作为表提示用的隔离级别名称也有同义词,例如, NOLOCK相当于指定 READUNCOMMITTED,HOLDLOCK相当于指定REPEATABLEREAD。
默认的隔离级别是READ COMMITTED。如果你选择改变这个默认的隔离级别,那么选择的结果对数据库用户的并发性和他们获取数据的一致性都会产生影响。对于SQL Server2005之前可用的四个隔离级别,隔离级别越高,读操作请求的锁定就越严格,锁持有的时间也更长;因此,隔离级别越高,一致性也就越高,并发性就越低。当然,反过来也一样。对于其他两个基于快照的隔离级别,SQL Server能够把以前提交过的行保存到tempdb数据库中。当读操作发现行的当前版本和它们预期的不一致时,可以立即得
到行的以前版本,从而不用请求共享锁也能取得预期的一致性。
下面各小节将分别介绍 SQL Server支持的6个隔离级别,演示它们的行为方式。
READ UNCOMMITTED 未提交读
READ UNCOMMITTED是最低级的隔离级别。在这个隔离级别运行的事务,读操作不会请求共享锁。如果读操作不请求共享锁,就绝对不会和持有排他锁的写操作发生冲突。这意味着读操作可以读取未提交的修改(也称为脏读)。同时也意味着读操作不会妨碍写操作请求排他锁。也就是说,当运行在READ UNCOMMITTED隔离级别下的读操作正在读取数据时,写操作可以同时对这些数据进行修改。
为了演示什么是未提交读(脏读,dirty read),打开两个査询窗口(将这两个窗口分别称为Connection 1和Connection 2)。确保两个窗口都连接到样例数据库TSQLFundamentals2008。
在Connection 1中运行以下代码,打开一个事务,更新产品2的单价,为其当前值(19.00)增加1.00,然后查询该产品:
BEGIN TRAN;
UPDATE Production.Products
SET unitPrice += 1.00
WHERE productId = 2;
SELECT productId, unitPrice
FROM Production.Products
WHERE productid = 2;注意,以上代码中的事务保持打开,这意味着产品2所在的行将一直被Connection 1持有的排他锁锁定。
在Connection 2中,运行以下代码,将会话的隔离级别设置为READ UNCOMMITTED,再查询产品2所在的行:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;因为这个读操作不用请求共享锁,所以它不会和其他事务发生冲突。该査询返回产品2所在行修改后的状态,即使这一修改还没有被提交。
Connection 1在事务中可能会对行再进行更多的修改,或者在某一点上回滚事务。例如,在 onnection1中运行以下代码以回滚事务:
ROLLBACK TRAN;这个回滚操作会撤消对产品2的更新,把它的价格修改回19.00,读操作此前获得的20.00再也不会被提交了。这就是脏读的一个例子。
READ COMMITTED 已提交读
如果想避免读取未提交的修改,则需要使用要求更严格的隔离级别。能够防止脏读的最低隔离级别是READ COMMIITTED,这也是所有版本的 SQL Server默认使用的隔离级别。如其名称所示,这个隔离级别只允许读取已经提交过的修改。它要求读操作必须获得共享锁才能进行操作,从而防止读取未提交的修改。这意味着,如果写操作持有排他锁,读操作提出的共享锁请求就会和写操作发生冲突,所以读操作不得不等待。一旦写操作提交了事务,读操作就能获得它请求的共享锁,而这时再读取到的只能是修改提交过的数据。
下面这个例子演示在READ COMMITTED隔离级别下,读操作只能读取修改提交过的数据。
在 Connection1中运行以下代码,打开事务,更新产品2的价格,再査询该行以显示新价格:
BEGIN TRAN;
UPDATE Production.Products
SET unitPrice += 1.00
WHERE productId = 2;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;Connection 1现在以排他锁锁定了产品2的数据行。
在Connection 2中运行以下代码,将会话的隔离级别设置为READ COMMITTED,再查询产品2所在的行:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;READ COMMITTED是SQL Server默认的隔离级别,所以除非以前修改过会话的隔离级别,否则不需要显式地设置该隔离级别。执行该査询时,SELECT语句会被阻塞,因为这时它需要获取共享锁才能够进行读操作,而该共享锁请求与Connection 1中写操作持有的排他锁相冲突。
接下来,在 Connection1中运行以下代码,提交事务:
COMMIT TRAN;与 READ UNCOMMITTED不同,在READ COMMITTED隔离级别下,不会读取脏数据,相反,只能读取已经提交过的修改。
按照锁的持有时间来说,在READ COMMITTED隔离级别中,读操作一完成,就立即释放资源上的共享锁。读操作不会在事务持续期间内保留共享锁;实际上,甚至在语句结束前也不能一直保留共享锁。这意味着在一个事务处理内部对相同数据资源的两个读操作之间,没有共享锁会锁定该资源。因此,其他事务可以在两个读操作之间更改数据资源,读操作因而可能每次得到不同的取值。这种现象称为不可重复读(non-repeatable read)或不一致的分析(inconsistent analysis)。在许多应用程序中,这种现象是可以接受的,但是也有些程序不允许这种现象发生。
操作完成后,在每个打开的连接中运行以下代码以清理测试数据:
UPDATE Production.Products
SET unitPrice = 19.00
WHERE productId = 2;REPEATABLE READ 可重复读
如果想保证在事务内进行的两个读操作之间,其他任何事务都不能修改由当前事务读取的数据,则需要把隔离级别升级为REPEATABLE READ。在这种隔离级别下,事务中的读操作不但需要获得共享锁才能读取数据,而且获得的共享锁将一直保持到事务完成为止。这意味着一旦获得数据资源上的共享锁以读取数据,在事务完成之前,没有其他事务能够获得排他锁以修改这一数据资源。这样,就可以保证实现可重复的读取,或一致的分析。
下面这个例子演示了如何实现可重复读。在Connection 1中运行以下代码,将会话的隔离级别设置为REPEATABLE READ,打开事务,再査询产品2所在的行:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN TRAN;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;Connection 1这时仍然持有产品2上的共享锁,因为在REPEATABLE READ隔离级别下,共享锁一直要保持到事务完成为止。在Connection 2中运行以下代码,尝试对产品2这一行进行修改:
UPDATE Production.Products
SET unitPrice += 1.00
WHERE productId = 2;注意,SQL Server会阻塞这一修改尝试,因为修改操作请求的排他锁与前面读操作授予的共享锁冲突。如果读操作是在READ UNCOMMITTED或READ COMMITTED隔离级别下运行的,事务此时将不再持有共享锁,尝试修改该行的操作应该能成功。
回到Connection 1,运行以下代码,再次査询产品2所在的行,并提交事务:
SELECT productId, unitPrice
FROM Production.Products
WHERE productid = 2;
COMMIT TRAN;注意,第二次查询产品2的单价得到的结果与第一次相同。现在读操作的事务已经提交了,共享锁也释放了,所以 Connection 2中的修改操作就能获得它正等待的排他锁,对行进行更新。
REPEATABLE READ隔离级别能够防止的另一种并发负面影响是丢失更新(lost update),而较低的隔离级别则不能防止这种问题。丢失更新是指当两个事务读取了同一个值,然后基于最初读取的值进行计算,接着再更新该值,就会发生丢失更新的问题。因为在比REPEATABLE READ更低的隔离级别中,读取完数据之后就不再持有资源上的任何锁,两个事务都能更新这个值,而最后进行更新的事务则是“赢家”,覆盖由其他事务所作的更新,这将导致数据丢失。在REPEATABLE READ隔离级别下,两个事务在第一次读操作之后都将保留它们获得的共享锁,所以任何一个事务都不能获得为了更新数据而需要的排他锁。这种情况最终会导致死锁(deadlock),不过却避免了更新冲突。本章后面会详细介绍死锁问题。
操作完成后,运行以下代码以清理测试数据
UPDATE Production.Products
SET unitPrice = 19.00
WHERE productId = 2;SERIALIZABLE 可序列化
在REPEATABLE READ隔离级别下运行的事务,读操作获得的共享锁将一直保持到事务完成为止。因此可以保证在事务中第一次读取某些行后,还可以重复读取这些行。但是,事务只锁定査询第一次运行时找到的那些数据资源(例如,行),而不会锁定查询结果范围以外的其他行。因此,在同一事务中进行第二次读取之前,如果其他事务插入了新行,而且新行也能满足读操作的查询过滤条件,那么这些新行也会出现在第二次读操作返回的结果中。这些新行称为幻影(phantom),这种读操作也称为幻读(phantom read)。
为了避免幻读,需要将隔离级别设置为更高级的SERIALIZABLE。大多数时候,SERIALIZABLE隔离级别的处理方式和 REPEATABLE READ类似:即读操作需要获得共享锁才能读取数据,并保留共享锁直到事务完成。不过,SERIALIZABLE隔离级别增加了一个新内容一一逻辑上,这个隔离级别会让读操作锁定满足查询搜索条件的键的整个范围。这就意味着读操作不仅锁定了满足査询搜索条件的现有的那些行,还锁定了未来可能满足查询搜索条件的行。或者更准确地说,如果其他事务试图增加能够满足读操作的査询搜索条件的新行,当前事务就会阻塞这样的操作。
以下例子演示了如何用SERIALIZABLE隔离级别来避免幻读。在Connection 1中运行以下代码,将会话的事务隔离级别设置为SERIALIZABLE,打开事务,查询产品分类等于1的所有产品:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRAN;
SELECT productId, productName, categoryId, unitPrice
FROM Production.Products
WHERE categoryId = 1;在Connection 2中,运行以下代码,尝试插入一个分类等于1的新产品:
INSERT INTO Production.Products
(productName, supplierId, categoryId,
unitPrice, discontinued)
VALUES('Product ABCDE', 1, 1, 20.00, 0);在所有低于SERIALIZABLE的隔离级别下,这样的插入操作将会成功。而在SERIALIZABLE隔离级别下,这样的操作将被阻塞。
回到Connection 1,运行以下代码,再次查询分类1包括的产品,并提交事务:
SELECT productId, productName, categoryId, unitPrice
FROM Production.Products
WHERE categoryId = 1;
COMMIT TRAN;得到的输出结果和前面的一样,没有幻影行。现在读操作的事务已经提交了,共享键的范围锁也随之释放,所以Connection 2中的修改操作就获得了等候已久的排他锁,插入新行。
操作完成后,运行以下代码以清理测试数据:
DELETE FROM Production.Products
WHERE productId > 77;
DBCC CHECKIDENT ('Production.Products', RESEED, 77);在所有打开的连接中运行以下代码,将会话的隔离级别设置为默认值:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;SNAPSHOT 快照
可以把事务开始时,可用的上一个提交版本保存在tempdb数据库中,这是SQL Server 2005引入的一个新功能。以这种行版本控制技术为基础,SQL Server增加了两个新的隔离级别SNAPSHOT和READ COMMITTED SNAPSHOT。SNAPSHOT隔离级别在逻辑上和SERIALIZABLE隔离级别类似,它们能解决或不能解决的一致性问题都一样;READ COMMITTED SNAPSHOT隔离级别和READ COMMITTED隔离级别类似。不过,在基于快照的隔离级别下,读操作不需要使用共享锁,所以即使请求的数据被其他事务以排他锁锁定,读操作也不会等待,而且仍然可以得到和SERIALIZABLE和READ COMMITTED隔离级别类似的一致性。如果行的目前版本与预期的不同,读操作可以从tempdb的版本库中获得预期的版本。
注意,如果启用任何一种基于快照的隔离级别,DELETE和UPDATE语句在做出修改前会把行的当前版本复制到tempdb数据库中;INSERT语句不需要在tempdb中进行版本控制,因为这时还没有行的旧版本。但是也应该特别注意:无论使用哪种基于快照的隔离级别,都会对数据更新和删除操作的性能产生负面影响。不过,读操作的性能通常会有所提高,因为读操作不用先获得共享锁,当数据被其他事务的排他锁锁定或其版本不是预期的时候,也不需要等待。接下来的部分就详细介绍基于快照的隔离级别,演示它们的行为方式。
SNAPSHOT 隔离级别
在SNAPSHOT隔离级别下,当读取数据时,可以保证读操作读取的行是事务开始时可用的最后提交的版本。这意味着这种隔离级别可以保证读取的是已经提交过的数据,而且可以实现可重复读,也能确保不会幻读(就像SERIALIZABLE隔离级别一样)。不过,这一隔离级别使用的不是共享锁,而是行版本控制。如前所述,不论修改操作(主要是更新和删除数据)是否在某种基于快照的隔离级别下的会话中执行,快照隔离级别都会带来性能上的开销。因此,为了启用SNAPSHOT隔离级别,需要先在数据库级上设置相关选项(如果不做该项设置,虽然能设置SNAPSHOT隔离级别,但之后的语句执行会报错)。在任意打开的查询窗口中运行以下代码:
-- 查询数据库系统中的【所有数据库的快照隔离状态】
SELECT name, user_access, user_access_desc, snapshot_isolation_state,
snapshot_isolation_state_desc, is_read_committed_snapshot_on
FROM sys.databases;
-- 设置【允许快照隔离】
ALTER DATABASE TSQLFundamentals2008
SET ALLOW_SNAPSHOT_ISOLATION ON;下面的例子演示了SNAPSHOT隔离级别的行为方式。在 Connection 1中运行以下代码,打开事务,更新产品2的价格,把它的当前价格(19.00)增加1.00,然后再查询该产品,显示更新后的新价格:
BEGIN TRAN;
UPDATE Production.Products
SET unitPrice += 1.00
WHERE productId = 2;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;注意,即使Connection 1中的事务在默认的READ COMMITTED隔离级别下运行,SQL Server也必须在更新之前把行的一个版本(副本)(价格为19.00)复制到tempdb数据库。这是因为SNAPSHOT隔离级别是在数据库级启用的,如果使用SNAPSHOT隔离级别启动事务,在更新之前就会请求行的版本。例如,在Connection 2中运行以下代码,将隔离级别设置为SNAPSHOT,打开一个事务,查询产品2所在的行:
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRAN;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;如果这个事务是在SERIALIZABLE隔离级别下运行的,那么查询将被阻塞。但因为现在是在NAPSHOT下运行的,能够得到行数据在事务启动时可用的最后提交的版本。这个版本(产品价格为19.00)不是当前的版本(价格为20.00),SQL Server会从保存的行版本中得到合适的版本。
回到Connection 1,提交修改这一行的事务:
COMMIT TRAN;此时,产品2所在行的价格为20.00,这个版本现在是已经提交的版本。但是,如果在Connection 2中再次读取数据,得到的将仍然是事务开始时可用的上一次提交的版本(价格为19.00)。在Connection 2中运行以下代码,再次读取数据,然后提交该事务:
SELECT productId, unitPrice
FROM Production.Products
WHERE productid = 2;
COMMIT TRAN;会得到价格还是19.00的输出(之前开启的事务在这次查完价格后才结束)。
继续在 Connection 2中运行以下代码,打开一个新的事务,査询数据,最后提交该事务:
BEGIN TRAN;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;
COMMIT TRAN;这次,当事务开始时可用的上一次提交的版本是价格为20.00的版本。
快照清理线程每隔1分钟会运行一次,现在由于没有事务需要价格为19.00的那个行版本了,所以清理线程下一次运行时会把这个行版本从 tempdb中删除掉。
操作完成后,运行以下代码以清理测试数据:
UPDATE Production.Products
SET unitPrice = 19.00
WHERE productId = 2;冲突检测
REPEATABLE READ和SERIALIZABLE隔离级别通过产生死锁状态而避免更新冲突,SNAPSHOT隔离级别也能够避免更新冲突,但与前面两种隔离级别不同,当检测到更新冲突时,SNAPSHOT隔离级别下的快照事务将因失败而终止。SNAPSHOT隔离级别通过检査保存的行版本,就能够检测出更新冲突。它能判断出在快照事务的一次读操作和一次写操作之间是否有其他事务修改过数据。
下面先演示一个没有发生更新冲突的例子,再演示一个发生了更新冲突的例子。在Connection 1中运行以下代码,将事务的隔离级别设置为SNAPSHOT,打开一个事务,读取产品2所在的行:
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRAN;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;假设在读取到的数据的基础上进行了一些计算之后,仍然在Connection 1中运行以下代码,把先前查询到的产品的价格修改为20.00,再提交事务:
UPDATE Production.Products
SET unitPrice = 20.00
WHERE productId = 2;
COMMIT TRAN;在快照事务进行读取、计算、修改操作期间没有其他事务对行进行过修改:因此,没有发生更新冲突, SQL Server将允许更新操作执行。
运行以下代码,把产品2的价格修改回19.00:
UPDATE Production.Products
SET unitPrice = 19.00
WHERE productId = 2;接下来,在Connection 1中再次运行以下代码,打开一个事务,读取产品2所在的行:
BEGIN TRAN;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;显示产品2的当前价格是19.00。
这时,在Connection 2中运行以下代码,将产品2的价格修改为25.00:
UPDATE Production.Products
SET unitPrice = 25.00
WHERE productId = 2;假设根据刚才读取的价格(19.00)进行了一些计算之后,想在Connection 1中把产品的价格修改为20.00:
UPDATE Production.Products
SET unitPrice = 20.00
WHERE productId = 2;这次SQL Server检测到在读取和写入操作之间有另一个事务修改了数据;因此SQL Server让当前事务因失败而终止。当然,当检测到更新冲突时,可以使用错误处理代码尝试再次执行整个事务。
操作完成后,运行以下代码以清理测试数据:
UPDATE Production.Products
SET unitPrice = 19.00
WHERE productId = 2;最后关闭所有数据库上的连接。注意,如果没有关闭所有连接,可能导致例子的运行结果与本章所述的内容不一致。
READ COMMITTED SNAPSHOT 隔离级别
READ COMMITTED SNAPSHOT隔离级别也是基于行版本控制,但与SNAPSHOT隔离级别有所不同:在READ COMMITTED SNAPSHOT隔离级别下,读操作读取的数据行不是事务启动前最后提交的版本,而是语句启动前最后提交的版本。此外,READ COMMTTTED SNAPSHOT隔离级别不进行更新冲突检测。这样一来,READ COMMITTED SNAPSHOT的逻辑行为就与READ COMMITTED隔离级别非常类似,只不过读操作不用获得共享锁,当请求的资源被其他事务的排他锁锁定时,也不用等待。
要在数据库中启用READ COMMITTED SNAPSHOT隔离级别,需要打开一个和启用SNAPSHOT隔离级别不同的数据库选项。运行以下代码,以便在TSQLFundamentals2008数据库中启用READ COMMITTED SNAPSHOT隔离级别:
ALTER DATABASE TSQLFundamentals2008
SET READ_COMMITTED_SNAPSHOT ON;注意,要成功运行这一代码,当前连接必须是到TSQLFundamentals2008数据库的唯一连接。
激活这个数据库选项时有趣的一点是,与SNAPSHOT隔离级别不同,这个选项其实是把默认的READ COMMITTED隔离级别的含意变成了READ COMMITTED SNAPSHOT。这意味着当打开这个数据库选项时,除非显式地修改会话的隔离级别,否则READ COMMITTED SNAPSHOT将成为默认的隔离级别。
下面演示READ COMMITTED SNAPSHOT隔离级别的用法,先打开两个连接。
在Connection 1中运行以下代码,打开一个事务,更新产品2所在的行,再读取这一行,并一直保持事务打开:
USE TSQLFundamentals2008;
BEGIN TRAN;
UPDATE Production.Products
SET unitPrice += 1.00
WHERE productid = 2;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;产品的价格已经变成了20.00。
在 Connection 2中,打开事务,读取产品2所在的行,并一直保持事务打开:
BEGIN TRAN;
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;得到的是语句启动之前最后提交的行版本(价格为19.00)。
在Connection 1中运行以下代码,提交事务:
COMMIT TRAN;这时在Connection 2中再运行以下代码,再次读取产品2所在的行,并提交事务:
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;
COMMIT TRAN;如果这段代码是在SNAPSHOT隔离级别下运行的,得到的价格将会是19.00;但是,因为现在代码是在READ COMMITTED SNAPSHOT隔离级别下(是连接该数据库的所有会话的隔离级别)运行,得到的是语句启动前最后提交的版本(价格为20.00),而不是事务启动之前的版本(价格为19.00)。
回想一下,这种现象称为不可重复读或者不一致的分析。
操作完成后,运行以下代码以清理测试数据:
UPDATE Production.Products
SET unitPrice = 19.00
WHERE productId = 2;关闭所有连接,然后在一个新的连接中运行以下代码,以禁用TSQLFundamentals2008数据库中基于快照的隔离级别:
ALTER DATABASE TSQLFundamentals2008 SET ALLOW_SNAPSHOT_ISOLATION OFF;
ALTER DATABASE TSQLFundamentals2008 SET READ_COMMITTED_SNAPSHOT OFF;隔离级别总结
下表总结了每种隔离级别能否解决各种逻辑一致性问题,以及隔离级别是否会检测更新冲突,是否使用了行版本控制。
| 隔离级别 | 未提交读? | 不可重复读? | 丢失更新? | 幻读? | 检测更新冲突? | 使用行版本控制? |
|---|---|---|---|---|---|---|
| READ UNCOMMITED | 是 | 是 | 是 | 是 | 否 | 否 |
| READ COMMITTED | 否 | 是 | 是 | 是 | 否 | 否 |
| READ COMMITED SNAPSHOT | 否 | 是 | 是 | 是 | 否 | 是 |
| REPEATABLE READ | 否 | 否 | 否 | 是 | 否 | 否 |
| SERIALIZABLE | 否 | 否 | 否 | 否 | 否 | 否 |
| SNAPSHOT | 否 | 否 | 否 | 否 | 是 | 是 |
死锁
死锁(deadlock)是指一种进程之间互相永久阻塞的状态,可能涉及两个或更多的进程。两个进程发生死锁的例子是,进程A阻塞了进程B,而进程B又阻塞了进程A。超过两个进程发生死锁的例子是,进程A阻塞了进程B,进程B阻塞了进程C,而进程C又阻塞了进程A。在任何一种情况下,SQL Server都可以检测到死锁,并选择终止其中一个事务以干预死锁状态。如果SQL Server不干预,死锁涉及到的进程将永远保持死锁状态。
除非指定了其他方式,SQL Server会选择终止做过的操作最少的事务,因为这样可以让回滚开销降低到最少。不过,用户也可以自己指定死锁情况下会话的优先级。自从SQL Server 2005以后,可以将会话选项DEADLOCK PRIORITY设置为范围**(-10到10)之间的任一整数值**;而在SQL Server 2005之前的版本中,死锁优先级只有LOW和NORMAL两个可用的属性值。如果两个进程的死锁优先级不同,不管它们的回滚开销有多少,数据库引擎都会选择优先级较低的进程作为死锁牺牲品。如果两个进程的死锁优先级相同,则会选择回滚开销最低的进程作为死锁牺牲品。
下面的例子演示了一个简单的死锁。然后再介绍如何将系统中发生死锁的机会降至最低。
打开两个连接,确保都连接到TSQLFundamental2008数据库。在Connection 1中运行以下代码,打开一个新事务,更新Production.Products表中产品2的行,并保持事务一直打开:
USE TSQLFundamentals2008;
BEGIN TRAN;
UPDATE Production.Products
SET unitPrice += 1.00
WHERE productId = 2;在Connection 2中运行以下代码,打开一个新事务,更新Sales.Orderdetails表中产品2的订单明细,并保持事务打开:
BEGIN TRAN;
UPDATE Sales.OrderDetails
SET unitPrice += 1.00
WHERE productId = 2;此时Connection 1中的事务持有Production.Products表中产品2这一行的排他锁,Connection 2中的事务持有Sales.OrderDetails表中产品2的订单明细行上的排他锁。两个査询都成功执行,还没有发生阻塞。
在Connection 1中运行以下代码,尝试在 Sales.OrderDetails表中査询产品2的订单明细,再提交事务:
SELECT orderId, productId, unitPrice
FROM Sales.OrderDetails
WHERE productId = 2;
COMMIT TRAN;这段代码是在默认的READ COMMITTED隔离级别下运行的;因此Connection 1中的事务需要一个共享锁才能读数据。因为有其他事务持有同一资源上的排他锁,所以Connection1中的事务被阻塞。此时只是发生了阻塞而不是死锁。当然,要是Connection 2可以完成事务,释放所有的锁,则Connection1中的事务就能获得请求的锁。
接下来,在Connection 2中运行以下代码,尝试在Production.Products表中查询产品2,再提交事务:
SELECT productId, unitPrice
FROM Production.Products
WHERE productId = 2;
COMMIT TRAN;Connection 2中的事务需要获得Production.Products表中产品2所在行上的共享锁,才能读取数据。所以这个请求和Connection 1中事务在同一资源上持有的排他锁冲突。这两个进程互相阻塞,发生了死锁。 SQL Server通常会在几秒钟内检测到死锁,并从这两个进程中选择一个作为死锁牺牲品,终止其事务。
在本例中, SQL Server选择终止Connection 1中的事务。因为没有设置死锁优先级,而且两个事务进行的工作量也差不多一样,所以任何一个事务都有可能被终止。
解除死锁要付出一定的系统开销,因为这个过程会涉及撤销已经执行过的处理。可以遵循一些最佳实践,将系统中发生死锁的机会降至最低:
- 显然,事务处理的时间越长,持有锁的时间就越长,死锁的可能性也就越大。应该尽可能保持事务简短,把逻辑上可以不属于同一工作单元的操作移到事务以外。
- 当事务以相反的顺序来访问资源时会发生死锁。例如,在上面的例子中,Connection 1先访问Production.Products表中的行,然后访问Sales.OrderDetails表中的行;而Connection 2先访问Sales.OrderDetails表中的行,然后访问Production.Products表中的行。如果两个事务按同样的顺序来访问资源,则不会发生这种类型的死锁。通过交换其中一个事务中的操作顺序,就可以避免发生这种类型的死锁(假设交换顺序不必改变程序的逻辑)。
- 上述列举的这个死锁例子有真实的逻辑冲突,因为两个事务都试图访问相同的行。不过,死锁发生时也经常没有真实的逻辑冲突,比如因为査询筛选条件缺少良好的索引支持而造成的死锁。例如,假设 Connection 2中的事务有两条语句要产品5进行筛选。既然Connection 1中的语句要处理产品2, Connection 2中的语句要处理产品5,所以它们不应该有任何冲突。但是,如果在表的productId列上没有索引来支持查询筛选,SQL Server就必须扫描(并锁定)表中的所有行。这样当然就会导致死锁。总之,良好的索引设计将有助于减少引发这种没有真正的逻辑冲突的死锁。
操作完成以后,运行以下代码以清理测试数据:
UPDATE Production.Products
SET unitPrice = 19.00
WHERE productId = 2;
UPDATE Sales.OrderDetails
SET unitPrice = 19.00
WHERE productId = 2
AND orderId > 10500;
UPDATE Sales.OrderDetails
SET unitPrice = 15.20
WHERE productId = 2
AND orderId < 10500;可编程对象
本章的目的旨在对这些可编程对象提供总体介绍,而不会深入到每个技术细节。阅读本章时应该着重理解可编程对象的逻辑处理和功能,不必尝试理解所有代码元素和它们的技术细节。有关可编程对象的细节和更深入的介绍,请参考“ Inside Microsoft SQL Server2008:T- SQL Programming”一书。
变量
变量用于临时保存数据值,以供在声明它们的同一批处理语句中引用。批处理稍后才会介绍,不过现在只要知道批处理是发送到SQL Server的一组单条或多条T-SQL语句,SQL Server会将批处理中的语句编译为单个可执行单元。
用DECLARE语句可以声明一个或多个变量,用SET语句可以把一个变量设置成指定的值。SQL Server 2008增加了对在同一语句中同时声明和初始化变量的支持。没有初始化的变量的默认值是NULL。
例如,以下代码先声明一个数据类型为INT的变量@i,再将它赋值为10:
DECLARE @i AS INT;
SET @i = 10;
-- SQL Server 2008新增加了对在同一语句中同时声明和初始化变量的支持
DECLARE @i AS INT = 10;当为标量(scalar)变量赋值时,变量值必须是标量表达式的结果。表达式可以是标量子査询。例如,以下代码声明了一个变量@empName,再把一个标量子查询的结果赋值给这个变量,而由这个子査询返回ID等于3的雇员的全名:
USE TSQLFundamentals2008;
DECLARE @empName AS NVARCHAR(61);
SET @empName = (SELECT firstName + ' ' + lastName
FROM HR.Employees
WHERE empId = 3);
SELECT @empName AS empName;SET语句每次只能对一个变量进行操作,所以如果需要把值赋值给多个变量(或列属性),就必须使用多个SET语句。当从同一行取出多个列的值时,这可能会带来一些不必要的开销。例如,以下代码使用两个单独的SET语句,把ID等于3的雇员的姓名分别赋值给两个变量:
DECLARE @firstName AS NVARCHAR(20), @lastName AS NVARCHAR(40);
SET @firstName = (SELECT firstName
FROM HR.Employees
WHERE empId = 3);
SET @lastname = (SELECT lastName
FROM HR.Employees
WHERE empId = 3);
SELECT @firstName AS firstName, @lastName AS lastName;SQL Server还支持一种非标准的赋值SELECT语句,允许在单独的语句中既査询数据也把从同一行中获得的多个值分配给多个变量。以下是这种用法的一个例子:
DECLARE @firstName AS NVARCHAR(20), @lastName AS NVARCHAR(40);
SELECT @firstName = firstName,
@lastName = lastName
FROM HR.Employees
WHERE empId = 3;
SELECT @firstName As firstName, @lastName AS lastName;当满足条件的査询结果只有一行时,赋值SELECT语句的行为和我们预料的一样。但是注意,如果査询返回多个满足条件的结果行,这段代码也不会失败。对于每个满足条件的结果行,都会进行赋值:当访问每一行时,就会用当前行的值覆盖掉变量中的原有值。当赋值SELECT语句完成时,变量中保存的值是SQL Server随机访问到的最后一行中的值。
SET语句比赋值SELECT语句更安全,因为它要求使用标量子査询来从表中提取数据。记住,如果在运行时,标量子查询返回了多个值,则査询会失败。
批处理
批处理是从客户端应用程序发送到SQL Server的一组单条或多条TSQL语句,SQL Server将批处理语句作为单个可执行的单元。批处理要经历的处理阶段有:分析(语法检査)、解析(检査引用的对象和列是否存在、是否具有访问权限)、优化(作为一个执行单元)。
不要把事务和批处理搞混。事务是工作的原子工作单元,而一个批处理可以包含多个事务,一个事务也可以在多个批处理中的某些部分提交。当事务在执行中途被取消或回滚时, SQL Server会撤消自事务开始以来进行的部分活动,而不考虑批处理是从哪里开始的。
客户端应用程序的API(如ADO.NET)提供的方法可以把要执行的批处理代码提交到SQL Server。而诸如SQL Server Management Studio、SQLCMD以及OSQL之类的SQL Server实用工具则提供了一个客户端命令GO,可以发出一批T-SQL语句结束的信号。注意,GO命令是客户端工具的命令,而不是T-SQL服务器的命令。
批处理是语句分析的单元
批处理是作为一个单元而进行分析和执行的一组命令。如果分析成功,SQL Server接着就会尝试执行批处理。如果批处理中存在语法错误,整个批处理就不会提交到SQL Server执行。例如,以下代码包含3个批处理,其中第二个存在语法错误(第二个査询中的FOM应该是FROM):
-- Valid batch
PRINT 'First batch';
USE TSQLFundamentals2008;
GO
-- Invalid batch
PRINT 'Second batch';
SELECT custId FROM Sales.Customers;
SELECT orderId FOM Sales.Orders;
GO
-- Valid batch
PRINT 'Third batch';
SELECT empId FROM HR.Employees;因为第2个批处理存在语法错误,所以该批处理不会提交到 SQL Server执行。而第1个和第3个批处理能够通过语法检查,因而可以提交到 SQL Server执行。即(同一个会话中,执行多个批处理,前面批处理的出错不会影响之后批处理的执行)。
批处理和变量
变量是属于定义它们的批处理的局部变量,如果试图引用在其他批处理中定义的变量,SQL Server引擎将会报告引用的变量还没有定义。
不能在同一批处理中编译的语句
下列语句不能在同一批处理中和其他语句同时编译: CREATE DEFAULT、 CREATE FUNCTION、 CREATE PROCEDURE、 CREATE RULE、 CREATE SCHEMA、 CREATE TRIGGER及CREATE VIEW。例如,以下代码包含一个IF语句,之后在同一批处理中跟着一个CREATE VIEW语句,因此这样的批处理是无效的:
IF OBJECT_ID('Sales.MyView', 'V') IS NOT NULL
DROP VIEW Sales.MyView;
CREATE VIEW Sales.MyView
AS
SELECT YEAR(orderDate) AS orderYear, COUNT(*) As numOrders
FROM sales.Orders
GROUP BY YEAR(orderDate);
GO为了避开这一问题,可以在IF语句之后添加一个GO命令,从而把IF和CREATE VIEW语句分隔到不同的批处理中。
批处理是语句解析的单元
批处理是语句解析的单元。这意味着检查数据对象和列是否存在,是在批处理级上进行的。当设计批处理的边界时,应该牢记这一事实。如果对数据对象的架构定义进行了修改,并试图在同一批处理中对该数据对象进行处理,那么 SQL Server可能还不知道架构定义发生了变化,因而无法执行数据处理语句,报告解析错误。下面将通过一个例子来演示这个问题,再对此推荐能够避免这一问题的最佳实践。
运行以下代码,在tempdb数据库中创建一个T1表,它包含一个列col1:
USE tempdb;
IF OBJECT_ID('dbo.T1', 'U') IS NOT NULL
DROP TABLE dbo.T1;
CREATE TABLE dbo.T1(col1 INT);接着,向T1表中新增一个col2列,并在同一个批处理中查询该新列:
ALTER TABLE dbo.T1 ADD col2 INT;
SELECT col1, col2 FROM dbo.T1;即使这段代码看起来可能相当有效,但批处理在解析期间还是会失败。
当解析SELECT语句时,T1表还只有一个列,对col2列的引用将导致错误。避免这种问题的最佳实践就是把DDL语句和DML语句分隔到不同的批处理中。
GO n 选项
SQL Server 2005对GO命令这个客户端工具进行了增强,让它可以支持一个正整数参数,表示GO之前的批处理将执行指定的次数。当需要重复执行批处理时,就可以使用这个新选项。为了演示增强的GO命令,先在tmepdb数据库中创建一个T1表,它只有一个标识列:
IF OBJECT_ID('dbo.T1', 'U') IS NOT NULL
DROP TABLE dbo.T1;
CREATE TABLE dbo.T1(col1 INT IDENTITY);接着,运行以下代码,阻止DML语句在生成的结果中默认显示受影响的行数:
SET NOCOUNT ON;最后,运行以下代码,定义一个由INSERT DEFAULT VALUES语句组成的批处理,再执行100次:
INSERT INTO dbo.T1 DEFAULT VALUES;
GO 100;记住,GO是一个客户端命令,而不是服务器端的T-SQL命令。这意味着,无论连接到的数据库引擎的版本是什么,只要使用的客户端工具是SQL Server 2005或更高版本中的,就可以支持GO n命令。
流程控制元素
IF … ELSE 流程控制元素
IF…ELSE元素用于根据条件来控制代码的执行流程。如果条件取值为TRUE,则执行指定的语句或语句块;如果条件取值为FALSE或UNKNOWN,则执行指定的另一语句或语句块(此部分为可选的)。
例如,以下代码检査今天是否是一年的最后一天(今天的年份和明天的年份不同)。如果是,代码就打印输出消息,说今天是一年的最后一天;如果不是,代码就打印输出消息,说今天不是一年的最后一天:
IF YEAR(CURRENT_TIMESTAMP) != YEAR(DATEADD(day, 1, CURRENT_TIMESTAMP))
PRINT 'Today is the last day of the year.'
ELSE
PRINT 'Today is not the last day of the year.'在这个例子中,用PRINT语句来指示代码的哪一部分被执行,哪一部分没有被执行。当然,也可以指定其他任何语句。
记住,T-SQL使用的是三值逻辑,当条件取值为 FALSE或 UNKNOWN时都可以激活ELSE语句块。如果条件取值可能为 FALSE或 UNKNOWN(例如,涉及到NULL值),而且对每种情况需要进行不同的处理时,必须用IS NULL谓词对NULL值进行显式地测试。
如果需要控制的流程分支超过两个,则可以使用嵌套的IF…ELSE元素。例如,以下代码对3种情况进行不同的处理:
- 今天是一年的最后一天;
- 今天是一个月的最后一天,但不是一年的最后一天;
- 今天不是一个月的最后一天。
IF YEAR(CURRENT_TIMESTAMP) != YEAR(DATEADD(day, 1, CURRENT_TIMESTAMP))
PRINT 'Today is the last day of the year.'
ELSE IF MONTH(CURRENT_TIMESTAMP) != MONTH(DATEADD(day, 1, CURRENT_TIMESTAMP))
PRINT 'Today is the last day of the month but not the last day of the year.'
ELSE
PRINT 'Today is not the last day of the month.';如果需要在IF或ELSE部分运行多条语句,则可以使用语句块。语句块的边界是用一对BEGIN和END关键字标识的。例如,如果今天是一个月的第1天,则对TSQLFundamentals2008样例数据库进行完整备份;如果今天是一个月的最后1天,则对TSQLFundamentals2008样例数据库进行差异备份(只保存上一次完整备份以来做过的更新),以下代码可以实现这样的备份策略:
IF DAY(CURRENT_TIMESTAMP) = 1
BEGIN
PRINT 'Today is the first day of the month.';
PRINT 'Starting a full database backup.';
BACKUP DATABASE TSQLFundamentals2008
TO DISK = 'C:\Temp\TSQLFundamenta1s2008_full.BAK' WITH INIT;
PRINT 'Finished full database backup';
END
ELSE IF MONTH(CURRENT_TIMESTAMP) = MONTH(DATEADD(day, 1, CURRENT_TIMESTAMP))
BEGIN
PRINT 'Today is the last day of the month.'
PRINT 'Starting a differential database backup.';
BACKUP DATABASE TSQLFundamentals2008
TO DISK ='C:\Temp\TSQLFundamentals2008_Diff.BAK' WITH DIFFERENTIAL;
PRINT 'Finished differential database backup.';
END注意,以上代码中的BACKUP DATABASE语句假设C:\Temp这个目录已经存在。
WHILE 流程控制元素
T-SQL提供的WHILE流程控制元素可以用于循环执行代码。当在WHILE关键字后指定的条件取值为TRUE时, WHILE元素可以重复执行一条语句或语句块。当指定的条件取值为FALSE或UNKNOWN时,循环将会终止。
T-SQL没有提供执行预定循环次数的内建元素,不过,用 WHILE循环和一个变量可以容易地模拟这样的元素。例如,以下代码演示了如何编写一个执行10次的循环:
DECLARE @i AS INT;
SET @i = 1;
WHILE @i <= 10
BEGIN
PRINT @i;
SET @i += 1;
END;如果想在循环体内部的某一处退出当前循环,继续执行循环体之后的语句,则可以使用BREAK命令。例如,以下代码当变量@i的值等于6时,就会退出循环:
DECLARE @i AS INT;
SET @i = 1;
WHILE @i <= 10
BEGIN
IF @i = 6 BREAK;
PRINT @i;
SET @i += 1;
END;如果想在循环体内的某处忽略当前循环的剩余处理,继续进行下一次循环,则可以使用CONTINUE命令。例如,以下代码演示了如何在第6次进入循环体时,忽略从IF语句之后直到循环体结束之前出现的其他操作:
DECLARE @i AS INT;
SET @i = 1;
WHILE @i <= 10
BEGIN
SET @i += 1;
IF @i = 6 COUNTINUE;
PRINT @i;
END;使用 IF 和 WHILE 的一个例子
以下代码组合使用了IF和WHILE元素。这个例子的目的是要在 tempdb数据库中创建1个dbo.Nums表,再为这个表填充1,000行数据,每行中的列n依次从1到1000中的取一个值:
SET NOCOUNT ON;
USE tempdb;
IF OBJECT_ID('dbo.Nums', 'U') IS NOT NULL
DROP TABLE dbo.Nums;
CREATE TABLE dbo.Nums(n INT NOT NULL PRIMARY KEY);
GO
DECLARE @i AS INT;
SET @i = 1;
WHILE @i <= 1000
BEGIN
INSERT INTO dbo.Nums(n) VALUES(@i);
SET @i += 1;
END游标 cursor
在第2章“单表査询”一章中曾经介绍过,不带ORDER BY子句的査询返回的是一个集合(或多集),而带有ORDER BY子句的査询返回的是一种ANSI称为游标(cursor)的对象,因为这种结果的行之间具有固定的顺序,所以不是关系的结果。在第2章讨论的上下文中,游标这一术语的使用仅限于表达一种概念。T-SQL也支持一种称为游标的对象,可以用它来处理査询返回的结果集中的各行,以指定的顺序一次只处理一行。这种处理方式与使用基于集合的查询(不带游标的普通査询)相反,普通的查询是把集合或多集作为一个整体来处理,不依赖任何顺序。
这里要强调的是,在默认情况下应该使用基于集合的查询,只在有令人信服的理由时才考虑使用游标。这一建议基于以下几个原因:
- 首先也是最重要的,如果使用游标,就严重违背了关系模型,关系模型要求按照集合来考虑问题。
- 其次,游标逐行对记录进行操作会带来一定的开销。和基于集合的操作相比,游标分别对每一记录进行操作,这肯定会带来一定的额外开销。
- 第三,使用游标,需要为解决方案的物理操作编写很多代码,换句话说,得写很多代码来描述如何处理数据(声明游标、打开游标、循环遍历游标记录、关闭游标、释放游标)。而使用基于集合的解决方案,则主要关注于问题的逻辑方面,也就是说,只要描述要获取什么,而不必描述如何获取它们。因此,与基于集合的解决方案相比,基于游标的解决方案通常代码更长,可读性更低,也更加难以维护。
对于大多数人来说,当开始学习SQL时,就马上能按集合的方式来考虑问题可能并不容易。与关系模型需要的思维方式相比,从游标的角度来考虑问题(以固定的顺序一次只处理一条记录)对大多数人来说可能更直观。结果,游标无形中被广泛使用,但大多数情况下是错误地使用;也就是说,使用游标的地方,往往也有更好的基于集合的解决方案存在。请在头脑中有意地努力保持基于集合的状态,真正地按集合来考虑问题。虽然这样做可能要多花些时间(可能要几年),但是,只要你驾驭了这种基于关系模型的语言,就找到了考虑问题所需的正确途径。
使用游标,就像是用鱼杆钩鱼,一次只能钩到一条鱼一样。另一方面,使用集合,就像是用渔网捕鱼,一次能捕到整整一网鱼。再打个比方,考虑有两种橘子包装工厂,一种是旧式的,另一种是新式的。工厂需要按3种不同的大小(小、中、大)把橘子分装到不同的盒子中。旧式工厂是以游标模式进行处理的,传送带把橘子带进来,在每条传送带的末端由专人负责检査每个橘子,根据橘子的大小把它放到正确的盒子中。当然,这种处理方式非常慢。此外,处理顺序在这里也很重要:如果传送带送过来的橘子是已经按大小排序的,处理起来就更容易了,这样就能把传送带的速度设置得更高。新式工厂是以集合模式进行处理的:所有橘子都放在一个大容器中,容器底部有一个带有小孔的网格。机器可以抖动这个容器,只有小橘子才能通过网格上的小孔。机器接着把橘子移到一个带有中型孔的容器中,再抖动容器,这时只有体积中等的橘子才能通过底部的孔。最后容器中剩下的就是大橘子。
即使你确信基于集合的解决方案是你的默认选择,理解一些例外也很重要,总会有应该使用游标的时候。一个例子是需要为某个表或视图中的每一行应用特定的操作。例如,可能需要为 SQL Server实例中的每个数据库(或数据库中的每个表)执行某种管理性任务。在这种情况下,用游标来循环遍历数据库名或表名,每次遍历为每个对象执行相关的任务,就变得有意义了。在后面的“动态SQL”一节将提供这种用法的例子。
应该考虑使用游标的另一个例子是当基于集合的解决方案执行情况不好,用基于集合的各种调整方法也无济于事时。如前所述,基于集合的解决方案通常要快得多,但是在某些情况下,基于游标的解决方案会更快。这样的情况通常是些计算型的操作,对于相应的基于集合的解决方案,即使在经过 SQL Server(SQL Server 2008及其早期版本)目前的优化处理以后,如果按固定顺序一次处理一行的游标方式涉及到的数据访问比前者要少得多,则使用游标会更加有效。连续聚合( running aggregate)就是这样的一个例子。在第4章“子查询”的“连续聚合”一节中曾经提供过一种使用子查询实现的基于集合的解决方案。性能优化已经超出了本书的讨论范围,所以在此不详细介绍为什么和基于集合的解决方案相比,用游标来实现连续聚合是目前更加有效的方法。如果准备处理T-SQL查询的性能优化问题,可以在Inside Microsoft SQL Server2008: T- SQL Querying一书中找到相关的细节。在这里只是希望读者明白,在大多数情况下,基于集合的解决方案在速度上通常比游标解决方案要快得多,但是在某些情况下,因为能进行更多的优化,因而游标执行起来仍然更快。
正如本章介绍所说的,本章只是提供对可编程对象的一个概览。所以接下来演示一个游标的例子可能更合适。
使用游标通常涉及以下步骤:
- 在某个查询的基础上声明游标;
- 打开游标;
- 从第1个游标记录中把列值提取到指定的变量;
- 当还没有超出游标的最后一行时(
@@FETCH_ STATUS函数的返回值是0),循环遍历游标记录:在每一次遍历中,从当前游标记录中把列值提取到指定的变量,再为当前行执行相应的处理; - 关闭游标;
- 释放游标。
下面这个例子使用游标来计算Sales.CustOrders视图中每个客户每个月的连续总订货量:
SET NOCOUNT ON;
USE TSQLFundamentals2008;
DECLARE @Result TABLE
(
custId INT,
orderMonth DATETIME,
qty INT,
runqty INT,
PRIMARY KEY(custId, orderMonth)
);
DECLARE @custId INT, @prvCustId INT,
@orderMonth DATETIME, @qty INT,
@runQty INT;
DECLARE C CURSOR FAST_FORWARD /*read only, forward only */ -- 声明游标
FOR
SELECT custId, orderMonth, qty -- 从Custorders视图中按照客户ID和订单月份的顺序返回基本数据行
FROM Sales.CustOrders
ORDER BY custId, orderMonth;
OPEN C -- 打开游标
FETCH NEXT FROM C INTO @custId, @orderMonth, @qty; -- 取值到指定的变量
SELECT @prvCustId = @custId, @runQty = 0; -- 既查询,又赋值
WHILE @@FETCH_STATUS = 0 -- 循环遍历
BEGIN
IF @custId != @prvCustId
SELECT @prvCustId = @custId, @runQty = 0;
SET @runQty += @qty;
INSERT INTO @Result
VALUES(@custId, @orderMonth, @qty, @runQty);
FETCH NEXT FROM C INTO @custId, @orderMonth, @qty;
CLOSE C; -- 关闭游标
DEALLOCATE C; -- 释放游标
SELECT custId,
CONVERT(VARCHAR(7), orderMonth, 121) AS orderMonth,
qty,
runQty
FROM @Result
ORDER BY custId, orderMonth;代码首先根据一个查询声明了一个游标,该查询用于从Custorders视图中按照客户ID和订单月份的顺序返回基本数据行;之后通过循环来遍历每个记录。代码会跟踪客户的当前连续总订货量,并把其值保存在变量@runQty中,并在每次找到一个新客户时重置这个变量。对于查询结果中返回的每一行,代码把当前月份的订货量(@qty)和变量@runQty相加,就可以计算出当前月份的连续总订货量,再把客户ID、订单月份、当前月份的订货量、以及连续总订货量作为一行插入到表变量@Result中。当代码处理完所有的游标记录后,再查询表变量以显示生成的连续聚合值。
临时表
有时需要把数据临时保存到表中,而且在某些情况下,你可能并不想使用水久性的表。例如,假设你需要让数据只对当前会话可见,或者甚至只对当前批处理可见。另一个例子是,假设你想让数据对所有用户都可见,允许他们看到完整的DDL和进行所有DML访问,但却没有在任何用户数据库中创建表的权限。
在这种情况下,使用临时表可能会更方便。 SQL Server支持三种类型的临时表:局部临时表、全局临时表及表变量。接下来的内容就分别介绍这三种临时表。
局部临时表
要创建局部临时表,只需要在命名时以单个#作为前缀,例如#T1。所有三种类型的临时表都是在tempdb数据库中创建的。
局部临时表只对创建它的会话在创建级和调用堆栈内部级(内部的过程、函数、触发器、以及动态批处理)可见。当创建级例程弹出调用堆栈,SQL Server就会自动删除相应的临时表。例如,假设一个存储过程Proc 1调用了另一个存储过程Proc 2,而Proc 2又调用了另一个存储过程Proc 3,Proc 3又调用了存储过程Proc 4。Proc 2在调用Proc 3之前创建了一个临时表#T1。这时表#T1对Proc 2、Proc 3和Proc 4是可见的,而对Proc 1是不可见的,当Proc 2完成时, SQL Server就会自动删除这个临时表。如果临时表是在会话最外层嵌套的一个特殊的批处理(@@NESTLEVEL函数的返回值是0)中创建的,则这个表对所有随后的批处理也是可见的,只有当创建会话从SQL Server实例断开时SQL Server才会自动删除它。
SQL Server内部会为临时表名称增加一个后缀,使表名称在tempdb数据库中保持唯一。并且只有你的会话才可以访问你的局部临时表。
可以使用临时表的一个明显场合是,当你的处理需要把中间结果临时保存起来(如在一个循环中),以供以后查询这些临时数据。
另一种场合是需要多次访问某个开销昂贵的处理结果。例如,假设需要对TSQLFundamentals2008数据库中的Sales.Orders和Sales.OrderDetails表进行连接,按订单年份对订货量进行聚合,之后再对聚合数据的两个实例进行连接,以比较每年的总订货量和前一年的总订货量。样例数据库中的Orders和OrderDetails表非常小,但是在实践中,这些表包含的数据可能达到数百万行。一种选择是使用表表达式,但记住表表达式是虚拟的。开销昂贵的工作涉及扫描所有数据、连接Orders和OrderDetails表、对数据进行再次聚合。所以,让所有开销昂贵的的工作只进行一次(把结果保存到一个局部临时表中),再对临时表的两个实例进行连接,这样做具有一定意义,尤其是因为开销昂贵的操作的结果是个非常小的集合,每个订单年份只有一行记录。
以下代码演示了使用局部临时表实现的解决方案:
USE TSQLFundamentals2008;
IF OBJECT_ID('tempdb.dbo.#MyOrderTotalsByYear') IS NOT NULL
DROP TABLE dbo.#MyOrderTotalsByYear;
GO
SELECT YEAR(O.orderDate) AS orderYear,
SUM(OD.qty) As qty
INTO dbo.#MyOrderTotalsByYear
FROM Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderId = O.orderId
GROUP BY YEAR(orderDate);
SELECT Cur.orderYear, Cur.qty AS curYearQty, Prv.qty AS prvYearQty
FROM dbo.#MyOrderTotalsByYear AS Cur
LEFT JOIN dbo.#MyOrderTotalsByYear AS Prv
ON Cur.orderYear = Prv.orderYear + 1;全局临时表
如果创建的是全局临时表,则它对其他所有会话都可见。当创建临时表的会话断开数据库的连接,而且也没有活动在引用全局临时表时, SQL Server会自动删除相应的全局临时表。要创建全局临时表,只需要在命名时用两个#作为前缀,如##T1。
当需要和所有人共享临时数据时,就可以用全局临时表。访问全局临时表不需要任何特殊的权限,所有人都可以获取完整的DDL和DML访问。当然,每个人都可以完全访问也意味着任何人都可以删除这个表,所以也应该谨慎考虑全局临时表的副作用。
例如,以下代码创建了一个全局临时表##Globals,它包含id和val两个列:
CREATE TABLE dbo.##Globals
(
id sysName NOT NULL PRIMARY KEY,
val SQL_VARIANT NOT NULL
);这个表在这里是想模仿全局变量( SQL Server不支持全局变量)。列id的数据类型是sysname( SQL Server在内部用这个类型来代表标识符),列val的数据类型是SQL_VARIANT(一种通用的类型,差不多可以保存任何基础类型的值)。
任何人都可以向全局临时表中插入数据行。例如,运行以下代码,在该临时表中插入代表变量i的一行,并将它的值初始化为整数10:
INSERT INTO dbo.##Globals(id, val) VALUES('i', CAST(10 AS INT));任何人都能够修改和检索全局临时表中的数据。例如,在任何会话中运行以下代码,就可以查询到变量i的当前值:
SELECT val FROM dbo.##Globals WHERE id = 'i';如果需要在每次SQL Server启动时都创建一个全局临时表,而且也不想让SQL Server自动删除它,则需要从一个标识为启动过程(startup procedure)的存储过程中创建全局临时表。相关的细节,可以参阅 SQL Server联机丛书的“自动执行存储过程(Automatic Execution of Stored Procedures)。
表变量
表变量和局部临时表在某些方面有相同之处,也有不同之处。声明表变量的方式和声明其他变量类似,使用的都是DECLARE语句。
和使用局部临时表一样,表变量在tempdb数据库中也有对应的表作为其物理表示,而不是像通常所理解的那样,以为表变量只在内存中存在。和局部临时表类似,表变量也只对创建它的会话可见,但允许访问的范围更有限,它只对当前批处理可见。表变量对调用堆栈中当前批处理的内部批处理是不可见的,对会话中随后的批处理也是不可见的。
如果回滚一个显式事务,在事务中对临时表所做的更改也将回滚:不过,通过语句对表变量进行的更改,如果在事务中已经完成了,则不会被回滚。只有通过活动语句进行的更改,而且操作失败或在完成之前被终止了,这样的更改才会被撤消。
临时表和表变量在性能优化方面也有区别,但这些内容超出了本书的讨论范围。现在只能说,从性能上考虑,对于少量的数据(只有几行),使用表变量更有意义,否则,应该使用临时表。
例如,以下代码没有使用局部临时表,而是使用表变量来比较每个订单年份和前一年的总订货量:
DECLARE @MyOrderTotalsByYear TABLE
(
orderYear INT NOT NULL PRIMARY KEY,
qty INT NOT NULL
);
INSERT INTO @MyOrderTotalsByYear(orderYear, qty)
SELECT YEAR(O.orderDate) AS orderYear, SUM(OD.qty) AS qty
FROM Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderId = O.orderId
GROUP BY YEAR(orderDate);
SELECT Cur.orderyear, Cur.qty AS curYearQty, Prv.qty AS prvYearQty
FROM @MyOrderTotalsByYear AS Cur
LEFT JOIN @MyOrderTotalsByYear AS Prv
ON Cur.orderYear = Prv.orderYear + 1;表类型
SQL Server 2008引入了对表类型的支持。通过创建表类型,可以把表的定义保存到数据库中,以 后在定义表变量、存储过程和用户定义函数的输入参数时,可以将表类型作为表的定义而重用。
例如, 以下代码在TSQLFundamentals2008数据库中创建了一个表类型dbo.OrderTotalsByYear:
USE TSQLFundamentals2008;
IF TYPE_ID('dbo.OrderTotalsByYear') IS NOT NULL
DROP TYPE dbo.OrderTotalsByYear;
CREATE TYPE dbo.OrderTotalsByYear AS TABLE
(
orderYear INT NOT NULL PRIMARY KEY,
qty INT NOT NULL
);创建好表类型以后,每当需要根据表类型的定义来声明表变量时,就不需要重复表定义代码,只要简单的将变量的类型指定为dbo.OrderTotalsByYear就可以,如下所示:
DECLARE @MyOrderTotalsByYear AS dbo.OrderTotalsByYear; 作为一个更复杂的例子,以下代码先声明了一个变量@MyOrderTotalsByYear,其数据类型为新定义的表类型;再查询Orders和OrderDetails表,按订单年份计算总订货量;再把查询的结果保存到表变量中;最后査询表变量,以显示它的内容:
DECLARE @MyOrderTotalsByYear AS dbo.MyOrderTotalsByYear;
INSERT INTO @MyOrderTotalsByYear(orderYear, qty)
SELECT YEAR(O.orderDate) AS orderYear,
SUM(OD.qty) AS qty
FROM Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderId = O.orderId
GROUP BY YEAR(orderDate);
SELECT orderYear, qty
FROM @MyOrderTotalsByYear;表变量的表类型只是为了有助于精简代码,不过从功能概念上来说,其实并没有引入什 么新功能。 但是如前所述,表类型也可以作为存储过程和函数的输入参数的类型,这种非常有用的功能从概念上来说算是新的。
动态 SQL
SQL Server允许用字符串来动态构造T-SQL代码的一个批处理,接着再执行这个批处理。
这种功能称为动态SQL(dynamic SQL)。SQL Server提供了两种执行动态SQL的方法:使用EXEC( EXECUTE的缩写)命令和使用sp_ executesql存储过程。
动态SQL可以用于以下几种用途:
- 自动化管理任务。
例如,对于数据库实例中的每个数据库,査询其元数据,为其执行BACKUP DATABASE语句。 - 改善特定任务的性能。
例如,构造参数化的特定查询,以重用以前缓存过的执行计划(稍后对此详细介绍)。 - 在对实际数据进行查询的基础上,构造代码元素。
例如,当事先不知道在 PIVOT运算符的IN子句中应该出现哪些元素时,动态构造PIVOT査询。
注意:当把用户的输入拼接为代码中的一部分时,要特别小心。黑客们经常会试图注入(inject) 你不想运行的代码。要防止SQL注入,最好的办法就是避免将用户的输入拼接为代码 的一部分(例如,通过使用参数)。但是如果你确实需要将用户的输入拼接为代码的一 部分,务必要对用户的输入进行彻底检查,看看有没有SQL注入的企图。 SQL Server 联机丛书中的“SQL注入( SQL Injection)”是一篇介绍这方 面内容的优秀文章。
EXEC 命令
EXEC命令是T-SQL中最早提供的一种用于执行动态SQL的方法。EXEC接受一个字符串作为在圆括号中输入的参数,执行字符串中包含的批处理代码。EXEC命令的输入既支持普通字符,也支持Unicode字符。
首先以一个非常基本的用EXEC调用动态SQL的例子作为开始。以下例子在变量@sql中保存了一个字符串,该字符串中包含一条PRINT语句,再用EXEC命令调用保存在变量中的批处理代码:
DECLARE @sql AS VARCHAR(100);
SET @sql = 'PRINT ''This message was printed by a dynamic SQL batch.'';';
EXEC(@sql);注意,以上代码中对于字符串中的字符串,需要用两个单引号来代表一个单引号。
下面这个例子使用游标对INFORMATION_SCHEMA.TABLES视图进行查询,以获取TSQLFundamentals2008数据库中表的名称。 对于每个表,代码将构造和执行一个批处理代码,对当前表调用sp_spaceused存储过程以获取其磁盘空间使用信息:
USE TSQLFundamentals2008;
DECLARE @sql NVARCHAR(300),
@schemaName sysName,
@tableName sysName;
DECLARE C CURSOR FAST_FORWARD FOR
SELECT TABLE_SCHEMA, TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE';
OPEN C
FETCH NEXT FROM C INTO @schemaName, @tableName;
WHILE @@fetch_status = 0
BEGIN
SET @sql = 'EXEC sp_spaceused '''
+ QUOTENAME(@schemaName) + '.'
+ QUOTENAME(@tableName) + ''';';
EXEC(@sql);
FETCH NEXT FROM C
INTO @schemaName, @tableName;
END
CLOSE C;
DEALLOCATE C;在以上代码中,你可能会对QUOTENAME函数的使用感到好奇,这个函数用于分隔输入的值。 QUOTENAME的第二个参数用于指定用作分隔符的单字符字符串,如果不指定这个参数,则默认使用方括号。所以,如果@tableName的值是'My Table',则QUOTENAME(@tableName)将返回'[My Table]',使变量值成为有效的标识符。
这段代码会显示出数据库中所有表的磁盘空间使用信息。
sp_executesql 存储过程
sp_executesql存储过程是继EXEC命令之后引入的另一种执行动态SQL的方法。从sp_executesql的调用接口来说,使用这个存储过程更安全和更灵活,因为它支持输入和 输出参数。注意,与EXEC命令不同的是,sp_executesql存储过程只支持使用Unicode 字符串作为其输入的批处理代码。
正因为在动态SQL代码中可以使用输入和输出参数,这样就有助于写出更安全和更有效的代码。从安全性的角度来说,在代码中出现的参数并不是代码的一部分,而只是表达式中的运算对象。所以,通过使用参数,就可以不必受SQL注入的困扰了。sp_executes存储过程的执行性能要比EXEC命令更好,因为它的参数化有助于重用缓存过的执行计划。执行计划是SQL Server为查询生成的物理处理计划,包含了一组指 令,说明要访问哪些对象、以什么顺序、使用哪个索引、如何访问它们、使用什么连接算法、等等。为 了简化处理,如果要重用以前缓存过的执行计划,必须满足的条件之一就是査询字符串应该和缓存中已经存在的执行计划的查询字符串相同。所以,有效重用查询执行计划最好的方法就是使用带有参数的存储过程。这样一来,即使参数值发生了 变化,可查询字符串仍然保持相同。但如果你出于自己的原因而决定使用特定的代码, 而不使用存储过程,至少你仍然可以尽可能地使用参数。只不过如果使用sp_ executesql存储过程,则会增加重用执行计划的机会。sp_executesql存储过程有两个输入参数和一个参数赋值部分。在第一个参数@stmt中,需要指定包含想要运行的批处理代码的Unicode字符串。第二个参数@params是一个Unicode字符串,包含@stmt中所有输入和输出参数的声明。接着为输入和输出参数指定取值,各参数之间用逗号分隔。
下面这个例子构造了一个对 Sales.Orders表进行查询的批处理代码,在其查询过滤条件中使用了一个输入参数@orderId:
DECLARE @sql NVARCHAR(100);
SET @sql = 'SELECT orderId, custId, empId, orderDate
FROM Sales.Orders
WHERE orderId = @orderId;';
EXEC sp_executes
@stmt = @sql,
@params = '@orderId AS INT',
@orderId = 10248;代码中将输入参数的取值指定为10248,即使采用不同的值再运行这段代码,代码字符串仍然保持相同,这样就可以增加重用以前缓存过的执行计划的机会。
为了使用输出参数,只需要简单地在参数声明部分和参数赋值部分同时指定OUTPUT关键字。下面的例子演示了输出参数的用法。这段代码将查询INFORMATION_SCHEMA.TABLES视图,获取数据库中表和视图名称的列表,再使用游标来循环遍历对象名称。在每次循环中,代码会构造一个动态SQL批处理,以查询当前对象中的行数,并把査询结果保存在一个输出参数@n中。之后,将输出参数@n中的值传递到局部变量@numRows(该参数被指定为输出参数)。在循环结尾,代码将对象名称和当前对象的行数作为一个新行插入到表变量@Counts中。当代码循环遍历完游标记 录后,再查询表变量,以显示计数结果。以下是例子的完整代码:
DECLARE @Counts TABLE
(
schemaName sysName NOT NULL,
tableName sysName NOT NULL,
numRows INT NOT NULL,
PRIMARY KEY(schemaName, tableName)
);
DECLARE @sql NVARCHAR(350),
@schemaName sysName,
@tableName sysName,
@numRows INT;
DECLARE C CURSOR FAST_FORWARD FOR
SELECT TABLE_SCHEMA, TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES;
OPEN C
FETCH NEXT FROM C INTO @schemaName, @tablename;
WHILE @@fetch_status = 0
BEGIN
SET @sql = 'SET @n = (SELECT COUNT(*) FROM '
+ QUOTENAME(@schemaName) + '.'
+ QUOTENAME(@tableName) + ');';
EXEC sp_executesql
@stmt = @sql,
@params = '@n AS INT OUTPUT',
@n = @numRows OUTPUT;
INSERT INTO @Counts(schemaName, tableName, numRows)
VALUES(@schemaName, @tableName, @numRows);
FETCH NEXT FROM C INTO @schemaName, @tableName;
END
CLOSE C;
DEALLOCATE C;
SELECT schemaName, tableName, numRows
FROM @Counts;在 PIVOT 中使用动态 SQL
如前所述,在静态査询中,必须事先知道在 PIVOT运算符的IN子句中应该指定哪些值。以下是一个使用PIVOT运算符进行静态査询的例子:
SELECT *
FROM (SELECT shipperId, YEAR(orderDate) AS orderYear, freight
FROM Sales.Orders) AS D
PIVOT(SUM(freight) FOR orderYear IN([2006], [2007], [2008])) AS P; 这个例子査询 Sales.Orders表,对数据进行透视转换,以便返回的数据中以送货人ID作为行,以订单年份作为列,在每个送货人和订单年份的交叉位置上是总的运费。
对于静态查询,必须事先知道在PIVOT运算符的IN子句中应该指定哪些值(在以上例子中是订单年份)。这意味着对于不同的年份,都得调整代码。相反,也可以从数据中查询不同的订单年份,根据查询到的年份来构造一个动态SOL代码的批处理,再执行这个动态SQL批处理,如下所示:
DECLARE @sql NVARCHAR(1000),
@orderYear INT,
@first INT;
DECLARE C CURSOR FAST_FORWARD FOR
SELECT DISTINCT(YEAR(orderDate)) AS orderYear
FROM Sales.Orders
ORDER BY orderer;
SET @first = 1;
SET @sql = 'SELECT *
FROM (SELECT shipperId, YEAR(orderDate) AS orderYear, freight
FROM Sales.Orders) AS D
PIVOT(SUM(freight) FOR orderYear IN(';
OPEN C
FETCH NEXT FROM C INTO @orderYear;
WHILE @@fetch_status = 0
BEGIN
IF @first = 0
SET @sq1 = @sql + ',';
ELSE
SET @first = 0;
SET @sql = @sql + QUOTENAME(@orderYear);
FETCH NEXT FROM C INTO @orderYear;
END
CLOSE C;
DEALLOCATE C;
SET @sql = @sql + ')) AS P;';
EXEC sp_executesql @stmt = @sql;例程
例程( routine)是为了计算结果或执行任务而对代码进行封装的一种编程对象。SQL Server支持三 种例程:用户定义函数、存储过程,以及触发器。
从 SQL Server 2005开始,开发程序例程时可以选择是用T-SQL开发,还是用NET代码在集成到产品中的公共语言运行时(CLR, Common Language Runtime)的基础上进行开发。因为本书的重点是T-SQL,所以这里演示的例子将使用T-SQL。一般来说,当任务主要涉及数据处理时,T-SQL通常是更好的选择。当任务侧重于交互逻辑、字符串处理、或计算密集的操作时,NET通常是更好的选择。
用户定义函数
用户定义函数(UDF, user- defined function)的目的是要封装计算的逻辑处理,有可能需要基于输入的参数,并返回结果。
SQL Server支持两种用户定义函数:标量UDF和表值UDF。标量UDF只返回单个数据值。而表值UDF则返回一个表。使用UDF的优点之一是可以在査询中集成UDF。对于査询中返回单个值的表达式,在其出现的位置上,也能够使用标量UDF(例如,在SELECT列表中)。表值UDF只能在査询的FROM子句中出现。这里将提供一个标量UDF的例子。
UDF不允许有任何副作用。这一规定明显的含义是UDF不能对数据库中的任何架构或数据进行修改。此外,其他一些引起副作用的操作则不那么明显。例如,调用RAND函数返回一个随机值,或调用NEWID函数返回一个全局唯一标识符(GUID),就有副作用。每当调用RAND函数,但不指定种子值时, SQL Server就会根据以前对RAND的调用而生成一个随机的种子值。因此,当调用RAND函数时, SQL Server内部需要保存相关的信息。与之类似,每当调用NEWID函数时,系统也需要设置某种信息,以便下一次调用NEWID时使用。因为RAND和NEWD函数 都有副作用,所以在UDF中不允许使用它们。
例如,以下代码创建了一个用户定义函数dbo.fn_age,对于给定出生日期(@birthDate参数)和事件日期(@eventDate),这个函数可以返回某个人在事件日期当时的年龄:
USE TSQLFundamentals2008;
IF OBJECT_ID('dbo.fn_age') IS NOT NULL
DROP FUNCTION dbo.fn_age;
GO
CREATE FUNCTION dbo.fn_age
(
@birthDate DATETIME,
@eventDate DATETIME
)
RETURNS INT
AS
BEGIN
RETURN DATEDIFF(year, @birthDate, @eventDate)
- CASE WHEN 100 * MONTH(@eventDate) + DAY(@eventDate)
< 100 * MONTH(@birthDate) + DAY(@birthDate)
THEN 1 ELSE O
END
END
GO这个函数按照年份来计算生日年份和事件年份的差值,以作为其年龄,如果事件日期的月份和天数小于出生日期的月份和天数,则还需要在差值中再减去1。表达式100 * month + day是拼接月份和天数的一种简单技巧。
注意,一个函数体内可以包含多个RETURN子句,也可以包含流程控制代码、计算代码, 等等。但是函数必须由一个RETURN子句返回一个值。
为了演示在查询中使用UDF,以下代码对HR.Employees表进行查询,在SELECT列表中调用fn_age函数以计算每个雇员在查询当天的年龄:
SELECT empId, firstName, lastName, birthDate,
dbo.fn_age(birthDate, CURRENT_TIMESTAMP) AS age
FROM HR.Employees;存储过程
存储过程是封装了T-SQL代码的服务器端例程。存储过程可以有输入和输出参数,可以返回多个査询的结果集,也允许调用具有副作用的代码。通过存储过程不但可以对数据进行修改,也可以对数据库架构进行修改。
和使用特定的普通代码相比,使用存储过程可以获得以下好处:
- 存储过程可以封装逻辑处理。
- 通过存储过程可以更好地控制安全性。
可以授予用户执行某个存储过程的权限,而 不是授予用户直接执行底层操作的权限。例如,假设现在想允许特定用户可以删除数据库中的客户数据, 但是不想授予他们直接从Customers表中删除数据行的权限。而且还需要确保删除客户的请求是有效的(例如,检査客户是否有延期交货的订单、 是否有未清的债务等等),也可能需要对请求进行审核。不是授权直接删除Customers表中的客户,而是通过能够处理这一任务的某个存储过程进行授权,这样就可以确保执行所有要求的检查和审核处理。此外,存储过程也有助于避免SQL注入,尤其是从客户端通过参数来替换特殊的SQL的注入形式。 - 在存储过程中可以整合所有的错误处理,当有错误发生时,默默地进行纠正错误的操作。错误处理将在本章后面介绍。
- 存储过程可以提高执行性能。
在前面曾经讨论过重用以前缓存过的执行计划的内容。存储过程在默认情况下是重用执行计划的,而 SQL Server对其他特殊计划的重用有更多的限制。此外,存储过程计划失效的速度也没有其他特殊计划的失效速度那么快。 - 使用存储过程的另一个好处是可以减少网络通信流量。
客户端应用程序只需要向SQL Server服务器提交存储过程的名称和参数。服务器会处理存储过程的所有代码,向调用者只返回输出结果。对于处理过程的中间步骤,不需要任何往返的网络 通信流量。
作为一个简单的例子,以下代码创建了一个存储过程Sales. usp_GetCustomerOrders。该存储过程接受一个客户ID(@custId)和一个日期范围(@fromDate和@toDate)作为输入参数,返回Sales.Orders表中由指定客户在指定日期范围内所下的订单组成的结果集,同时也将受査询影响的行为作为输出参数(@numRows) 。
USE TSQLFundamentals2008;
IF OBJECT_ID('SALES.usp_GetCustomerOrders', 'P') IS NOT NULL
DROP PROC Sales.usp_GetCustomerOrders;
GO
CREATE PROC Sales.usp_GetCustomerOrders
@custId INT,
@fromDate DATETIME = '19000101',
@toDate DATETIME = '99991231',
@numRows INT OUTPUT
AS
SET NOCOUNT ON;
SELECT orderId, custId, empId, orderDate
FROM Sales.Orders
WHERE custId = @custId
AND orderDate >= @fromDate
AND orderDate < @toDate;
SET @numRows = @@rowCount;
GO当执行这个存储过程时,如果没有在@fromDate参数中指定任何值,则存储过程将使用默认的1900001;如果没有在@toDate参数中指定任何值,则存储过程将使用默认的99991231。注意关键字OUTPUT的使用,它用于标识参数@numRows是一个输出参数。命令SET NOCOUNT ON用于禁止显示DML语句(如存储过程中的SELECT语句)影响了多少行的消息。
下面这个例子执行该存储过程,请求由客户ID等于1的客户在2007年中下过的所有订单。代码将输出参数@numRows的值提取到局部变量@rc中,再返回这个变量的值,以显示查询影响了多少行记录:
DECLARE @rc INT;
EXEC Sales.usp_GetCustomerOrders
@custId = 1,
@fromDate = '20070101',
@toDate = '20080101',
@numRows = @rc OUTPUT;
SELECT @rc AS numRows;当然,这只是一个非常基础的例子,用存储过程能做其他更多的事情。
触发器
触发器是一种特殊的存储过程,一种不能被显式执行,而必须依附于一个事件的过程。只要事件发生,就会调用触发器,运行它的代码。SQL Server支持把触发器和两种类型的事件相关联:数据操作事件(如INSERT)和数据定义事件(如CREATE TABLE),和这两种事件关联的触发器分别称为DML触发器和DDL触发器。
触发器有很多用途,包括审核数据、实施不能通过约束而实现的完整性规则、实施一定的策略,等等。
可以把触发器看成是某个事务的一个组成部分,该事务包含能够触发触发器的事件。在 触发器的代码中执行ROLLBACK TRAN命令将会导致触发器内发生的所有更改,以及和触发器关联的事务中进行的所有更改都发生回滚。
在 SQL Server中,触发器是按照语句触发的,而不是按照被修改的行而触发。
DML 触发器
SQL Server支持两种DML触发器:AFTER触发器和INSTEAD OF触发器。 AFTER触发器是在与之关联的事件完成后才触发的,只能在持久化的表上定义这种触发器。 INSTEAD OF触发器的触发是为了代替与之关联的事件操作,可以在持久化的表或视图上定义这种类型的触发器。
在触发器代码中,可以访问称为inserted和deleted的两个表,它们包含导致触发器触发的修改操作而影响的记录行。inserted表包含当执行INSERT和UPDATE语句时受影响行的新数据的镜像。 deleted表则包含当执行DELETE和UPDATE语句时受影响行的旧数据的镜像。对于INSTEAD OF触发器,inserted和deleted表包含导致触发器触发的修改操作打算要影响的行。
下面演示一个简单的AFTER触发器的例子,对插入到表的数据进行审核。运行以下代码,在tempdb数据库中创建表dbo.T1和表dbo.T1_Audit,用表dbo.T1_Audit保存对T1表的插入进行审核后的信息:
USE tempdb;
IF OBJECT_ID('dbo.T1_Audit', 'U') IS NOT NULL
DROP TABLE dbo.T1_Audit;
IF OBJECT_ID('dbo.T1', 'U') IS NOT NULL
DROP TABLE dbo.T1;
CREATE TABLE dbo.T1
(
keyCol INT NOT NULL PRIMARY KEY,
dataCol VARCHAR(10) NOT NULL
);
CREATE TABLE dbo.T1_Audit
(
audit_lsn INT NOT NULL IDENTITY PRIMARY KEY,
dt DATETIME NOT NULL DEFAULT(CURRENT_TIMESTAMP),
login_name sysName NOT NULL DEFAULT(SUSER_SNAME()),
keyCo1 INT NOT NULL,
dataCol VARCHAR(10) NOT NULL
);在审核表中,audit_Isn列具有标识属性,由它代表审核日志的序列号。dt列代表插入操作发生的日期和时间,并使用默认的表达式CURRENT_TIMESTAMP。login_name列代表执行插入操作的登录用户的用户名,该插入操作使用默认的表达式SUSER_SNAME()。
接下来,运行以下代码,在T1表上创建AFTER INSERT触发器trg_T1_insert_audit,以审核插入操作:
CREATE TRIGGER trg_T1_insert_audit ON dbo.T1 AFTER INSERT
AS
SET NOCOUNT ON;
INSERT INTO dbo.T1_Audit(keyCol, dataCol)
SELECT keyCol, dataCol FROM inserted;
GO可以看到,触发器只是简单地把对inserted表的查询结果插入到审核表。在INSERT语句中没有显式列出的审核表中的列值是由前面讲述的几个默认表达式生成的。为了测试触发器,请运行以下代码:
INSERT INTO dbo.T1(keyCol, dataCol) VALUES(10, 'a');
INSERT INTO dbo.T1(keyCol, dataCol) VALUES(30, 'x');
INSERT INTO dbo.T1(keyCol, dataCol) VALUES(20, 'g');每条语句成功执行后,都会触发触发器。接下来,査询审核表:
SELECT audit_lsn, dt, login_name, keyCol, dataCol
FROM dbo.Tl_Audit;只有dt和login_name列的值反映的是你运行插入语句时的日期和时间,以及连接到SQL Server使用的登录用户名。
DDL 触发器
SQL Server 2005引入了对DDL触发器的支持,它们可以用于在数据库中执行审核、增强策略、变化管理等任务。
SQL Server支持在两个作用域内创建DDL触发器(数据库作用域和服务器作用域),这要取决于事件的作用域。例如,对于具有数据库作用域的事件(如CREATE TABLE),可以创建数据库作用域内的触发器;对于具有服务器作用域的事件(如CREATE DATABASE),可以创建服务器作用域内的触发器。SQL Server只支持AFTER类型的DDL触发器,而不支持BEFORE或INSTEAD OF类型的DDL触发器。
在触发器中,通过查询EVENTDATA函数(该函数将事件信息作为XML值返回),可以获取关于导致触发器触发的事件信息。再用XQuery表达式从XML值中提取各种事件属性,如提交时间、事件类型、 登录名称等。
下面演示一个DDL触发器的例子,对数据库中所有的DDL活动进行审核。首先,运行以下代码,创建一个名为testdb的数据库,再使用它:
USE master;
IF DB_ID('testdb') IS NOT NULL
DROP DATABASE testdb;
CREATE DATABASE testdb;
GO
USE testdb;接下来,运行以下代码,创建表dbo. AuditDDLEvents,用它来保存审核信息:
IF OBJECT_ID('dbo.AuditDDLEvents', 'U') IS NOT NULL
DROP TABLE dbo.AuditDDLEvents;
CREATE TABLE dbo.AuditDDLEvents
(
audit_lsn INT NOT NULL IDENTITY,
pastTime DATETIME NOT NULL,
eventType sysName NOT NULL,
loginName sysName NOT NULL,
schemaName sysName NOT NULL,
objectName sysName NOT NULL,
targetObjectName sysName NULL,
eventData XML NOT NULL,
CONSTRAINT PK_AuditDDLEvents PRIMARY KEY(audit_lsn)
);注意这个表中有个名为eventData的列,它的数据类型为XML。除了可以保存触发器从事件信息中提取到的单个属性,在eventData列中也可以保存完整的事件信息。
运行以下代码,在数据库上通过事件组DDL_DATABASE_LEVEL_EVENTS来创建审核触发器trg_audit_ddl_events,这个事件组代表数据库级上的所有DDL事件:
CREATE TRIGGER trg_audit_ddl_events
ON DATABASE FOR DDL_DATABASE_LEVEL_EVENTS
AS
SET NOCOUNT ON;
DECLARE @eventData AS XML;
SET @eventData = eventData();
INSERT INTO dbo.AuditDDLEvents(
postTime, eventType, loginName, schemaName,
objectName, targetObjectName, eventData)
VALUES(@eventData.value('(/EVENT_INSTANCE/PostTime)[1]', 'VARCHAR(23)'),
@eventData.value('(/EVENT_INSTANCE/EventType)[1]', 'sysName'),
@eventData.value('(/EVENT_INSTANCE/LoginName)[1]', 'sysName'),
@eventData.value('(/EVENT_INSTANCE/SchemaName)[1]', 'sysName'),
@eventData.value('(/EVENT_INSTANCE/ObjectName)[1]', 'sysName'),
@eventData.value('(/EVENT_INSTANCE/TargetObjectName)[1]', 'sysName'),
@eventData);
GO触发器代码首先把从EVENTDATA函数获得的事件信息保存到变量@eventData中。接着使用 Xquery表达式,通过.value方法提取事件信息的各属性,并把这些属性和完整事件信息的XML值作为新行插入到审核表中。
为了测试这个触发器,运行以下包含了几条DDL语句的代码:
CREATE TABLE dbo.T1(Col1 INT NOT NULL PRIMARY KEY);
ALTER TABLE dbo.T1 ADD co12 INT NULL;
ALTER TABLE dbo.T1 ALTER COLUMN Col2 INT NOT NULL;
CREATE NONCLUSTERED INDEX idx1 ON dbo.T1(co12);接着,执行以下代码查询审核表:
SELECT * FROM dbo.AuditDDLEvents;操作完成后,运行以下代码以清理测试数据:
USE master;
IF DB_ID('testdb') IS NOT NULL
DROP DATABASE testdb;错误处理
SQL Server提供了在T-SQL代码中用于处理错误的工具。进行错误处理的主要工具是种称为TRY...CATCH的结构,它是在SQL Server 2005中引入的。SQL Server也提供了 一组函数,调用它们可以获得 有关错误的信息。本节将先用一个基本的例子作为开始, 演示TRY...CATCH结构的使用,接着再用一个更详细的例子来演示错误函数的用法。
当使用TRY...CATCH结构时,通常是把T-SQL代码放在TRY块中(放在BEGIN TRY和END TRY关键字之间),而把错误处理代码放在紧接其后的CATCH块中(放在BEGIN CATCH和END CATCH关键字之间)。如果TRY块中的代码没有错误, SQL Server就 会简单地忽 略 CATCH块。如果TRY块发生了错误,流程控制就会转移到相应的CATCH块。注意,如果TRY…CATCH块捕获并处理了错误,则对于调用者来说,它不会看到有错误发生。
运行以下代码,它演示了在TRY块中没有发生错误的情形:
BEGIN TRY
PRINT 10 / 2;
PRINT 'No error';
END TRY
BEGIN CATCH
PRINT 'Error';
END CATCHTRY块中的所有代码都成功完成:因此,CATCH块将被忽略。接下来,运行一段类似的代码,但这次有条语句中除法运算的除数为0,这会发生错误:
BEGIN TRY
PRINT 10 / 0;
PRINT 'NO error';
END TRY
BEGIN CATCH
PRINT 'Error';
END CATCH当TRY块中第一条PRINT语句因为除数为零而引发错误时,控制流程就会转移到相应的CATCH块。 而原来TRY块中的第二条PRINT语句则不会执行。
通常,在CATCH块中进行的错误处理会涉及检査导致错误的原因,采取某种处理操作SQL Server可以通过一组函数来反馈有关错误的信息。ERROR_NUMBER函数将返回一个整数,代表错误的错误号,这可能算是最重要的一个错误函数。CATCH块通常包含一些流程控制代码,通过检査错误号来决定应该采取什么处理操作。ERROR_MESSAGE函数将返回错误的消息文本。要得到错误号和错误消息的列表,可以查询sys.messages目录视图。ERROR_SEVERITY和ERROR_STATE函数可以分别返回错误的严重级别和状态号。ERROR_LINE函数可以返回发生错误的行号。最后,ERROR_PROCEDURE函数可以返回发生错误的存储过程或触发器的名称,如果在过程中没有发生错误,则返回NULL。
接下来演示一个更详细的,使用错误函数进行错误处理的例子。首先运行以下代码,在tempdb数据库中创建一个名为dbo.Employees的表:
USE tempdb;
IF OBJECT_ID('dbo.Employees') IS NOT NULL
DROP TABLE dbo.Employees;
CREATE TABLE dbo.Employees
(
empId INT NOT NULL,
empName VARCHAR(25) NOT NULL,
mgrId INT NULL,
CONSTRAINT PK_Employees PRIMARY KEY(empId),
CONSTRAINT CHK_Employees_empid CHECK(empid > 0),
CONSTRAINT FK_Employees_Employees
FOREIGN KEY(mgrId)
REFERENCES dbo. Employees(empId)
);以下代码在TRY块中向Employees表插入一个新行,如果发生错误,则演示如何在CATCH块中检査ERROR_NUMBER函数,以识别发生了什么错误。代码也会打印输出其他错误函数的返回值,以简单地演示在发生错误时有什么可以利用的信息:
BEGIN TRY
INSERT INTO dbo.Employees(empId, empName, mgrId)
VALUES(1, 'Empl', NULL);
-- Also try with empId = 0, 'A', NULL
END TRY
BEGIN CATCH
IF ERROR_NUMBER() = 2627
BEGIN
PRINT ' Handling PK violation...';
END
ELSE IF ERROR_NUMBER() = 547
BEGIN
PRINT ' Handling CHECK/FK constraint violation...';
END
ELSE IF ERROR_NUMBER() = 515
BEGIN
PRINT ' Handling NULL violation...';
END
ELSE IF ERROR_NUMBER() = 245
BEGIN
PRINT ' Handling conversion error...';
END
ELSE
BEGIN
PRINT ' Handling unknown error...';
END
PRINT ' Error Number: ' + CAST(ERROR_NUMBER() AS VARCHAR(10));
PRINT ' Error Message: ' + ERROR_MESSAGE();
PRINT ' Error Severity: ' + CAST(ERROR_SEVERITY() AS VARCHAR(10));
PRINT 'Error State: ' + CAST(ERROR_STATE() AS VARCHAR(10));
PRINT 'Error Line: ' + CAST(ERROR_LINE() AS VARCHAR(10));
PRINT 'Error Proc: ' + COALESCE(ERROR_PROCEDURE(), 'Not within proc');
END CATCH当第一次运行这段代码时,新的行可以成功地插入到Employees表,因此将忽略CATCH 块。
当第二次运行同一段代码时,INSERT语句将会失败,流程控制转移到CATCH块,可以识别出发生的错误是主键冲突。
要査看其他错误的效果,可以用0、’A’、以及NULL作为雇员ID来运行这段代码。
出于演示的目的,当识别出错误以后,采用PRNT语句作为错误处理操作。当然,错误处理通常包含的不会仅仅只是打印输出一条消息,指示遇到了什么错误。
注意,可以创建一个存储过程,以封装可以重用的错误处理代码,如下所示:
IF OBJECT_ID('dbo.usp_err_messages', 'P') IS NOT NULL
DROP PROC dbo.usp_err_messages;
GO
CREATE PROC dbo.usp_err_messages
AS
SET NOCOUNT ON;
IF ERROR_NUMBER() = 2627
BEGIN
PRINT 'Hand]ing PK violation...';
END
ELSE IF ERROR_NUMBER() = 547
BEGIN
PRINT 'Handling CHECK/FK constraint violation...';
END
ELSE IF ERROR_NUMBER() = 515
BEGIN
PRINT 'Handling NULL violation...';
END
ELSE IF ERROR_NUMBER() = 245
BEGIN
PRINT 'Handling conversion error...';
END
ELSE
BEGIN
PRINT 'Handling unknown error...';
END
PRINT 'Error Number: ' + CAST(ERROR_NUMBER() AS VARCHAR(10));
PRINT 'Error Message: ' + ERROR_MESSAGE();
PRINT 'Error Severity: ' + CAST(ERROR_SEVERITY() AS VARCHAR(10));
PRINT 'Error State: ' + CAST(ERROR_STATE() AS VARCHAR(10));
PRINT 'Error Line: ' + CAST(ERROR_LINE() AS VARCHAR(10));
PRINT 'Error Proc: ' + COALESCE(ERROR_PROCEDURE(), 'Not within proc');
GO在 CATCH块中,只需要简单地执行这个存储过程:
BEGIN TRY
INSERT INTO dbo.Employees(empId, empName, mgrId)
VALUES(1, 'Empl', NULL);
END TRY
BEGIN CATCH
EXEC dbo.usp_err_messages;
END CATCH;这样一来,就可以只在数据库中的一个地方对可重用的错误处理代码进行维护。
SSMS使用技巧
- 如果在SQL Server Management Studio中编写代码时需要查找关于某个语法元素的帮助,则可以先确保光标位于该代码元素的某处,再按
Shift+F1组合键。这样将加载联机丛书,并为那个元素打开其语法页(假设存在这样 的帮助条目)。 - 当复制或剪切代码时,如果在突出选择代码之前,按下
ALt键,井在选择过程中ー直按住At键,则可以选择任意一个矩形区域,而不必非得从代码行的起始位置进行选择,这在代码注释行特别有用。 - 如果把一个表的 Columns(列)文件夹拖到查询窗口,SQL Server将列出这个表的所有列,列名之间用逗号隔开。