Spring Boot
概念
图床是一个网络术语,指的是一种用于存储和托管图片的在线服务。用户可以上传图片文件,并获得一个唯一的链接或嵌入代码,方便在网页、博客、论坛等地方分享和展示这些图片。
七牛云
将七牛云作为图床,实际上是使用了七牛云的对象存储服务(OSS)。
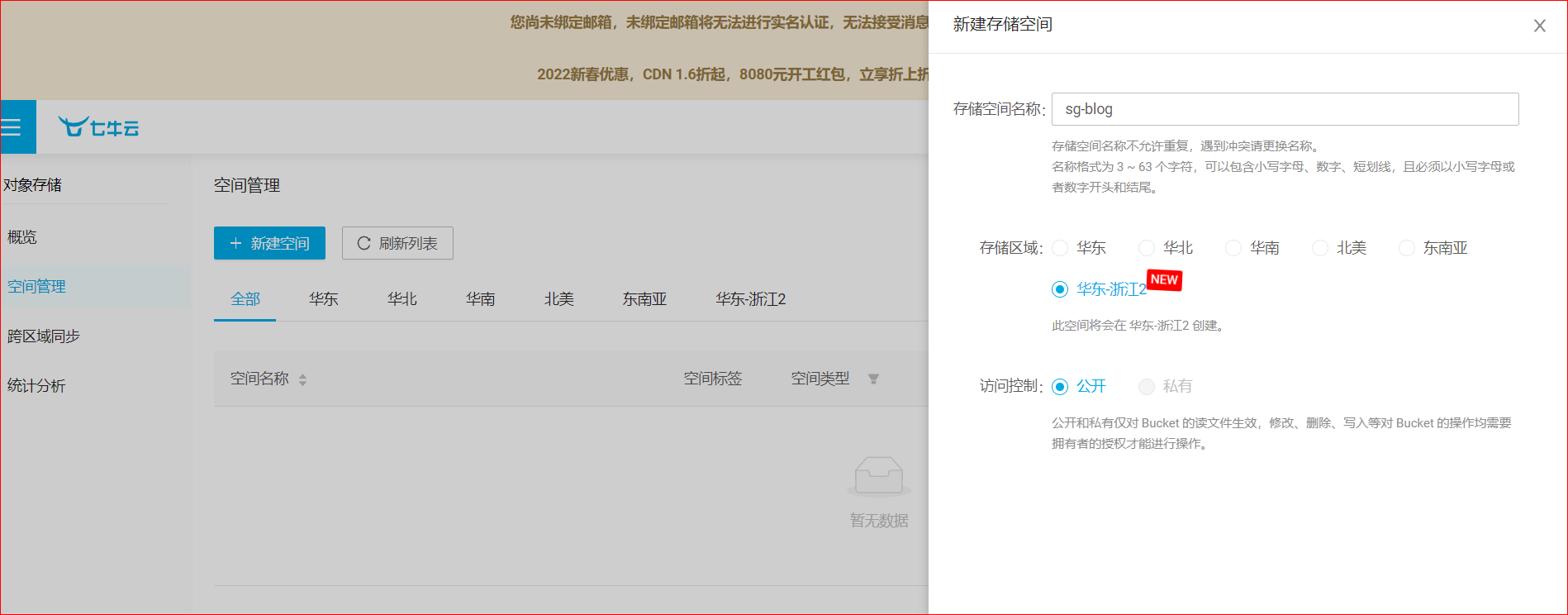
新建存储空间
获取密钥(AK、SK)
通过Java进行文件上传
官方开发文档:Java SDK_SDK 下载_对象存储 - 七牛开发者中心
首先添加依赖:
<dependency>
<groupId>com.qiniu</groupId>
<artifactId>qiniu-java-sdk</artifactId>
<version>7.17.0</version>
</dependency>注意:
7.17.0版本,qiniu-java-sdk自身依赖的gson的scope为runtime,在编译 main 目录下的 Java 类时,编译器会无法找到 gson 库,需要显式添加gson的依赖:
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.11.0</version>
</dependency>将密钥和目标桶 添加到配置文件中
qiniu:
accessKey: "实际的ak"
secretKey: "实际的sk"
bucket: "目标存储空间名称"编写文件上传测试代码
import com.qiniu.common.QiniuException;
import com.qiniu.http.Response;
import com.qiniu.storage.Configuration;
import com.qiniu.storage.Region;
import com.qiniu.storage.UploadManager;
import com.qiniu.storage.model.DefaultPutRet;
import com.qiniu.util.Auth;
import org.springframework.beans.factory.annotation.Value;
@SpringBootTest
@Slf4j
public class OSSTest {
@Value("${qiniu.accessKey}")
private String accessKey;
@Value("${qiniu.secretKey}")
private String secretKey;
@Value("${qiniu.bucket}")
private String bucket;
@Test
public void testOSS() {
// 构造一个带指定 Region 对象的配置类
Configuration cfg = new Configuration(Region.autoRegion());
cfg.resumableUploadAPIVersion = Configuration.ResumableUploadAPIVersion.V2;// 指定分片上传版本
UploadManager uploadManager = new UploadManager(cfg);
// 默认不指定key的情况下,以文件内容的hash值作为文件名
String key = "hunter.jpg";
Auth auth = Auth.create(accessKey, secretKey);
String upToken = auth.uploadToken(bucket);
try {
InputStream inputStream = new FileInputStream("C:\\Users\\Hunter\\Pictures\\Saved " +
"Pictures\\Rukawa-Sara-Sakuragi-Hanamichi-Slam-Dunk-slum-dunk.jpg");
Response response = uploadManager.put(inputStream, key, upToken, null, null);
// 解析上传成功的结果
DefaultPutRet putRet = new Gson().fromJson(response.bodyString(), DefaultPutRet.class);
System.out.println(putRet.key);
System.out.println(putRet.hash);
} catch (QiniuException ex) {
ex.printStackTrace();
if (ex.response != null) {
System.err.println(ex.response);
try {
String body = ex.response.toString();
System.err.println(body);
} catch (Exception ignored) {
}
}
} catch (FileNotFoundException ex) {
ex.printStackTrace();
System.err.println("file not found");
}
}
}实际应用代码
实际应用,需要获取图片上传至图床后的访问链接。
七牛云提供了临时的外链域名:

qiniu:
accessKey: "实际的ak"
secretKey: "实际的sk"
bucket: "目标存储空间名称"
domain: "http://外链域名/"- 为了便于后期管理上传的图片,以
当前的 年份/月份/日期 + 随机数 + 文件类型的形式作为文件名,实际会以/为分隔,按多级目录进行存储。 - 上传文件后,返回文件访问链接
${qiniu.domain} + 文件名
@Service
@Slf4j
public class UploadServiceImpl implements UploadService {
@Value("${qiniu.accessKey}")
private String accessKey;
@Value("${qiniu.secretKey}")
private String secretKey;
@Value("${qiniu.bucket}")
private String bucket;
/**
* 域名
*/
@Value("${qiniu.domain}")
private String domain;
@Override
public ResponseResult<String> uploadImg(MultipartFile img) throws IOException {
// 判断文件类型
String originalFilename = img.getOriginalFilename();
assert originalFilename != null;
String fileType = originalFilename.substring(originalFilename.lastIndexOf("."));
if (!".jpg".equals(fileType) && !".jpeg".equals(fileType)
&& !".png".equals(fileType)) {
throw new GlobalException(HttpCodeEnum.FILE_TYPE_ERROR);
}
// “当前的 年份/月份/日期 + 随机数 + 文件类型”作为文件名
String fileName =
LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy/MM/dd/"))
+ UUID.randomUUID()
+ fileType;
// 上传文件到七牛云,返回链接地址
String url = uploadToQiniu(img, fileName);
return ResponseResult.success(url);
}
/**
* 上传文件到七牛云
*
* @param img 上传的文件
* @param fileName 文件名
* @return 文件存储的地址
*/
private String uploadToQiniu(MultipartFile img, String fileName) throws IOException {
// 构造一个带指定 Region 对象的配置类
Configuration cfg = new Configuration(Region.autoRegion());
// 指定分片上传版本
cfg.resumableUploadAPIVersion = Configuration.ResumableUploadAPIVersion.V2;
Auth auth = Auth.create(accessKey, secretKey);
String upToken = auth.uploadToken(bucket);
try {
UploadManager uploadManager = new UploadManager(cfg);
InputStream inputStream = img.getInputStream();
// 默认不指定key的情况下,以文件内容的hash值作为文件名
Response response = uploadManager.put(inputStream, fileName, upToken, null, null);
// 解析上传成功的结果
DefaultPutRet putRet = new Gson().fromJson(response.bodyString(), DefaultPutRet.class);
log.info("文件成功上传到七牛云,key: {}, hash: {}", putRet.key, putRet.hash);
return domain + putRet.key;
} catch (QiniuException ex) {
log.error("上传文件到七牛云失败: {}", ex.getMessage(), ex);
throw ex;
} catch (FileNotFoundException ex) {
log.error("文件不存在: {}", ex.getMessage(), ex);
throw ex;
}
}
}