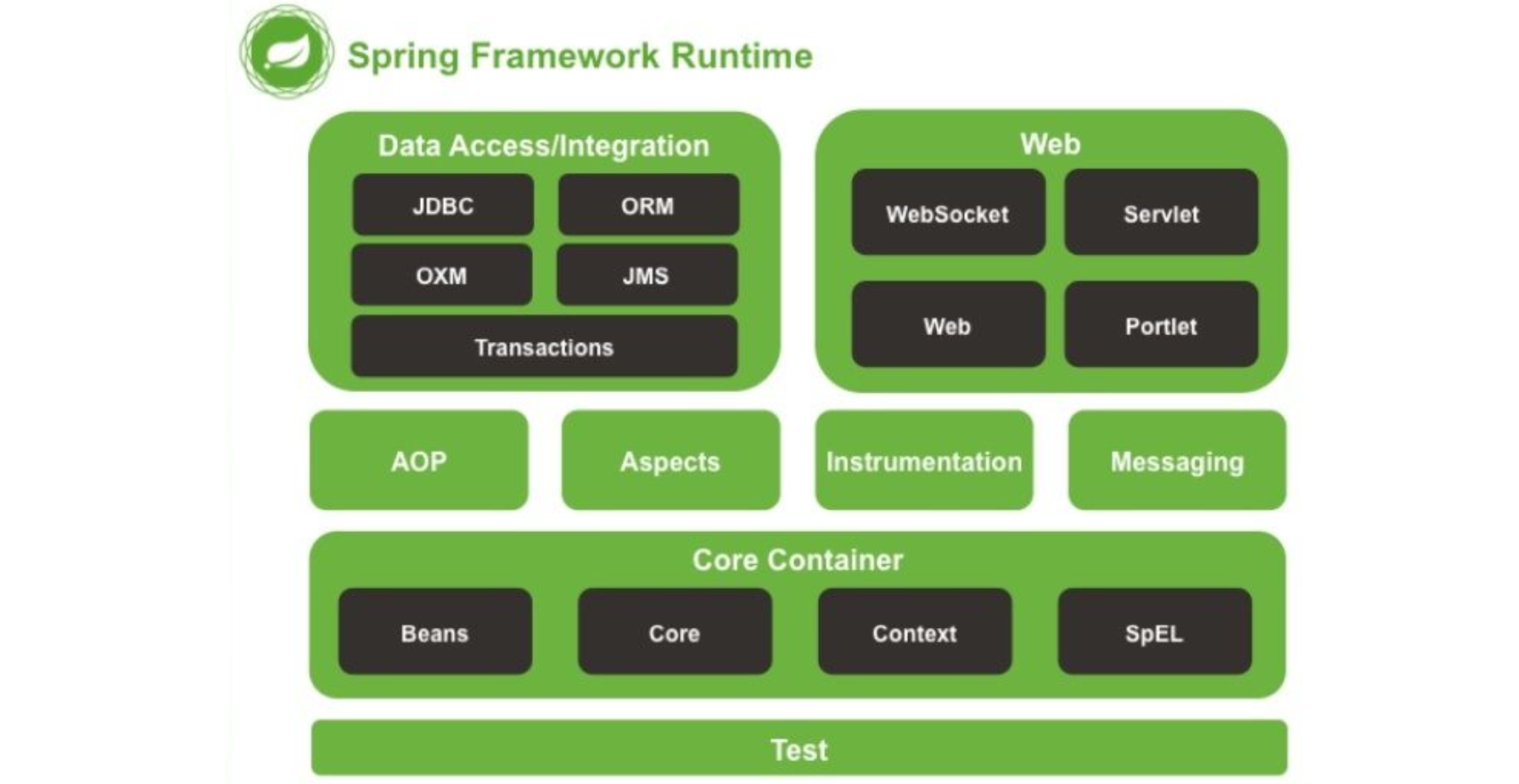
MyBatis与MyBatis-Plus
MyBatis
简介
MyBatis 是一款优秀的 持久层框架。它支持 定制化 SQL、存储过程以及高级映射。
MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或 注解 来配置和映射 原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为 数据库中的记录。
持久化
持久化就是将程序的数据在 持久状态 和 瞬时状态 转化的过程。
由于内存有断电之后数据就会丢失的特点,有一些对象不能丢失,需要将其持久化。
持久层
- 完成持久化工作的代码块就是持久层。
传统的 JDBC 代码太复杂,MyBatis 简化了将数据存入数据库这一过程。MyBatis 将 sql 和代码分离,提高了可维护性;提供了映射标签,支持对象与数据库的字段关系的映射(ORM,Object Relation Mapping);提供 xml 标签,支持编写动态 sql。
MVC三层架构
JavaBean
JavaBean是一个有如下特征的实体类:
- 必须有一个无参构造函数
- 属性必须私有化
- 必须有对应的
get/set方法
一般用于和数据库的字段做映射。
ORM(Object Relation Mapping,对象关系映射):
- 表 —-> 类
- 字段 —-> 属性
- 行记录 —-> 对象
什么是MVC架构
M:Model 模型
- 业务处理:Service层
- 数据持久化:DAO(Data Access Object)层
V:View 视图
JSP,用于展示数据,提供可供操作的请求。
C:Controller 控制器
Servlet,接收用户的请求,将请求交给业务层,控制视图的跳转。
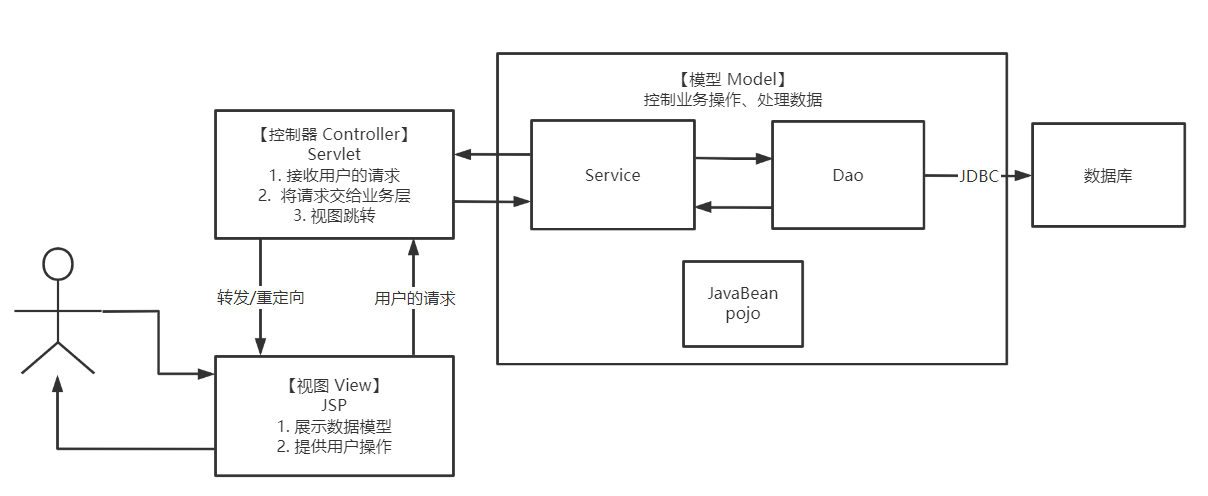
由架构示意图可知,由于JSP就是一种Servlet,因此控制器和视图会存在功能重合,为了易于维护和使用,做了人为规定:
- Servlet专注于处理请求,以及控制视图跳转
- JSP专注于展示数据
Cookie和Session
Cookie和Session是什么
Cookie和Session是两种会话数据的保存方式。其中,Cookie是客户端技术,Session是服务端技术。
两者具体的类封装在javax.servlet.httpjakarta.servlet.http包中,依赖jakarta.servlet-api包即可使用jakarta.servlet.http下的类。
Cookie
存储位置
存储在客户端,一般保存在本地用户目录下的appdata中。生命周期
默认会话结束后消失(存于内存中)。通过
setMaxAge(int time)可以设置cookie的有效期(单位是s,存到硬盘):- 默认值为
-1 - 如果设为
0,立即删除
- 默认值为
缺陷
大小和数量限制:一般每个站点大约能保存20个cookie,大小限制在4kb以内。浏览器一般有300个cookie上限。
**数据安全性问题:**http请求中的cookie是明文传递的。以存储网站的上次访问时间为例:
public class CookieDemo1 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 解决中文乱码
req.setCharacterEncoding("utf-8");
resp.setContentType("text/html");
PrintWriter out = resp.getWriter();
// 从客户端获取Cookie
Cookie[] cookies = req.getCookies();
// 判断cookies是否存在
if (cookies != null) {
out.write("你上次访问的时间是:");
for (Cookie cookie : cookies) {
if (cookie.getName().equals("lastLoginTime")) {
long lastLoginTime = Long.parseLong(cookie.getValue());
Date date = new Date(lastLoginTime);
SimpleDateFormat dateFormat = (SimpleDateFormat) DateFormat.getDateTimeInstance();
out.write(dateFormat.format(date));
break;
}
}
} else {
out.write("这是你第一次访问本站");
}
// 服务器给客户端响应一个cookie
Cookie cookie = new Cookie("lastLoginTime", Long.toString(System.currentTimeMillis()));
// 设置cookie过期时间,以秒为单位
cookie.setMaxAge(24 * 60 * 60);
resp.addCookie(cookie);
}
}Session
服务器会自动给每一个用户(浏览器)创建一个Session对象,一个Session独占一个浏览器,只要浏览器没有关闭,这个Session就存在。
服务器在自动创建Session的时候,会同时生成一个Cookie,存储sessionId:
Cookie cookie = new Cookie("JSESSIONID", sessionId);
resp.addCookie(cookie);存储位置
保存于服务端。使用场景
- 保存登录用户的信息
- 保存购物车信息
- 其他在整个网站中经常会使用的数据
生命周期
- 有效期30min,可以通过两种方式设置有效期:
setMaxInactiveTnterval(int time),单位是s- 在
web.xml中配置session有效期,单位是min
<session-config> <session-timeout>time</session-timeout> </session-config>- 还可以通过HttpSession的
invalidate()方法,手动使session失效。
- 有效期30min,可以通过两种方式设置有效期:
相关方法
Session也能和
ServletContext一样,实现不同Servlet之间的通信。并且该方式优于利用ServletContext。
String password = request.getParameter("password");
HttpSession session = request.getSession();
String name = (String)session.getAttribute("userName");
session.setMaxInactiveTnterval(30 * 60);
session.setAttribute("password", password);
session.removeAttribute("password");
session.invalidate();Servlet
Servlet是什么
Servlet(Server + Applet),一个Servlet就是一个Java类,并提供 基于请求-响应模式 的Web服务。
要使用servlet需要添加javax.servlet-apiJar包jakarta.servlet-api。
Servlet的处理流程
接收客户端的HTTP请求路径及请求内容
根据web.xml(属于web应用程序的一部分,部署描述符),找到请求路径对应的Servlet
... <servlet> <servlet-name>servlet名称(最好与类名相同)</servlet-name> <servlet-class>类路径</servlet-calss> </servlet> <servlet-mapping> <servlet-name>与<servlet>元素中的该元素内容相同</servlet-name> <url-pattern>映射路径</url-pattern> </servlet-mapping>将请求转发给Servlet对应的service方法(会传递HttpServletRequest对象和HttpServletResponse对象作为方法参数)
service方法根据请求是 get/post/… 转发给 doGet/doPost方法处理
通过HttpResponse对象,将响应返回给客户端
Servlet生命周期
init → service(doGet、doPost…) → destroy
管理Servlet的配置信息
通过ServletConfig对象获取配置
...
<servlet>
<init-param>
<param-name>参数名1</param-name>
<param-value>参数值1</param-value>
</init-param>
...
<servlet-name>servlet名称(最好与类名相同)</servlet-name>
<servlet-class>类名</servlet-calss>
</servlet>
<servlet-mapping>
<servlet-name>与<servlet>元素中的该元素内容相同</servlet-name>
<url-pattern>映射路径</url-pattern>
</servlet-mapping>每个Servlet支持设置多个<init-param>,Servlet初始化过程中,<init-param>参数将被封装到ServletConfig对象中。在Servlet中,通过调用ServletConfig对象,就可以利用配置信息:
ServletConfig config = this.getServletConfig();
String value1 = config.getParameter("参数名1");//根据查找参数名,获取参数值通过ServletContext共享Servlet的配置信息
Servlet容器在启动时,会为每个Web应用创建一个对应的ServletContext对象,它代表当前的Web应用。在一个Servlet中保存的数据,可以在另一个Servlet中获取。
<context-param>
<param-name>参数名1</param-name>
<param-value>参数值1</param-value>
</context-param>
...<context-param>是在各个具体的<servlet>元素之外的,同样可以设置多个<context-param>。在任意具体的Servlet中,通过调用ServletContext对象,就可以利用配置信息:
ServletContext context = this.getServletContext();
String globalValue1 = context.getInitParameter("参数名");通过ServletContext的属性(attribute)实现不同Servlet之间的通信
事先不知道,无法预先配置的信息,应该如何共享?(比如将购物车中的商品共享给结算页面)
在具体的Serlvet中,通过ServletContext对象的属性(attribute)设置希望共享的信息:
ServletContext context = this.getServletContext();
context.setAttribute("属性名","属性值");
String attribute = (String) context.getAttribute("属性名");//getAttribute的返回值是Object类型
context.removeAttribute("属性名");读取外部资源配置文件信息
通过ServletContext的方法读取。
Properties文件
在
java目录下新建的properties默认不会被打包,需要在
pom.xml文件中配置如下内容:<build> <resource> <directory>src/main/java</directory> <includes> <include>**/*.properties</include> <include>**/*.xml</include> </includes> <filtering>t</filtering> </resource> </build>在
resource目录下新建的properties默认会被打包到
classes路径下
都会被打包到
classes路径下,俗称这个路径为classpath
getResource(“外部资源配置文件的路径”)
ServletContext context = this.getServletContext();
URL url = context.getResource("外部资源配置文件的相对路径");
InputStream in = url.openStream();
/**
利用编写的一个工具类,读取属性值
String property1 = GeneralUtil.getProperty("属性名", in);
*/getResourceAsStream(“外部资源配置文件的路径”)
public class ServletDemo3 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 开头的"/"表示当前web项目,具体为target下的servlet-02-1.0-SNAPSHOT目录 (目录名根据pom.xml生成)
// 参数s 为相对路径
InputStream is = this.getServletContext().getResourceAsStream("/WEB-INF/classes/db.properties");
Properties prop = new Properties();
prop.load(is);
String username = prop.getProperty("username");
String passwd = prop.getProperty("passwd");
resp.getWriter().print(username + ": " + passwd);
}getRealPath(“外部资源配置文件的相对路径”)
获取外部资源配置文件的绝对路径
String realPath = context.getRealPath("外部资源配置文件的相对路径");HttpServletRequest类
常见应用
获取前端传递的参数
getParameter()getParameterValues()
请求转发
请求转发就是将当前的HttpServletRequest和HttpServletResponse对象交给指定的web组件处理。对客户端来说,是一次请求,一次响应,浏览器的URL不变。
步骤:
- 获取请求转发对象
即获取RequestDispatcher类的对象(由Servlet容器创建,封装由路径所标识的服务器资源)。
获取请求转发对象有两种方式:- 通过
HTTPServletRequest对象获取:
RequestDispatcher rd = request.getRequestDispatcher("绝对路径/相对路径"); - 通过
ServleContext对象获取:
RequestDispatcher rd = this.getServletContext().getNamedDispatcher("servlet-name");或者RequestDispatcher rd = this.getServletContext().getRequestDispatcher("绝对路径");
- 通过
- 调用转发对象的
forward(HttpServletRequest req, HttpServletResponse resp)方法
例子:
public class ServletDemo2 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
ServletContext context = this.getServletContext();
// 路径"/getInitParam"是在web.xml文件中配置的<servlet-mapping>的<url-pattern>
// 开头的"/"表示当前web项目,已涵盖tomcat设置的application context部分
// forward 实现请求转发
context.getRequestDispatcher("/getInitParam").forward(req, resp);
}
}HttpServletResponse类
向浏览器发送数据的方法
getOutputStream()getWriter()
向浏览器发送响应头的方法
void setCharacterEncoding(String var1);
void setContentLength(int var1);
void setContentLengthLong(long var1);
void setContentType(String var1);
void setDateHeader(String var1, long var2);
void addDateHeader(String var1, long var2);
void setHeader(String var1, String var2);
void addHeader(String var1, String var2);
void setIntHeader(String var1, int var2);
void addIntHeader(String var1, int var2);常见应用
向浏览器输出消息
public class GetServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
ServletContext context = this.getServletContext();
String username = (String) context.getAttribute("username");
// 设置响应内容的类型
resp.setContentType("text/html");
//resp.setCharacterEncoding("utf-8");
resp.getWriter().print("用户名:" + username);
}
}下载文件
public class FileServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 1. 获取下载文件的路径
String realPath = "C:\\Users\\Hunter\\IdeaProjects\\javaweb-02-servlet\\response\\src\\main\\resources\\20180422 卡特迈国家公园和自然保护区里午睡的灰熊幼崽,阿拉斯加州 1920x1080.jpg";
System.out.println("下载文件的路径:" + realPath);
// 2. 下载的文件名
String fileName = realPath.substring(realPath.lastIndexOf("\\") + 1);
// 3. 让浏览器能够支持下载,支持中文文件名编码
resp.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(fileName, "utf-8"));
// 4. 获取下载文件的输入流
FileInputStream fis = new FileInputStream(realPath);
// 5. 创建缓冲输入流
BufferedInputStream bis = new BufferedInputStream(fis);
// 6. 获取Outputstream对象
ServletOutputStream sos = resp.getOutputStream();
// 7. 将FileOutputStream流写入到缓冲区数组,使用OutputStream将缓冲区中的数据输出到客户端
byte[] bytes = new byte[1024]; // 存储每次读取的数据
int len = 0; // 记录每次读取的字节个数
while ((len = bis.read(bytes)) != -1) {
sos.write(bytes, 0, len);
}
bis.close(); // 关闭缓冲流,基本流也会被自动关闭
sos.close();
}
}验证码功能
实现方式:
- 前端实现
- 后端实现,需要用到java的图片类,产生一个图片
实现重定向
请求重定向就是通过HttpServletResponse对象发送给客户端一个新的URL地址,让其重新请求。对客户端来说,是两次请求,两次响应。
请求重定向的方法:resp.sendRedirect("绝对路径");,其中路径需要写明tomcat设置的application context前缀,可用req.getContextPath()获取绝对路径前缀。