概述
Java的I/O大概可以分成以下几类:
- 磁盘操作:File
- 字节操作:InputStream 和 OutputStream
- 字符操作:Reader 和 Writer
- 对象操作:Serializable
- 网络操作:Socket
- 新的输入/输出:NIO
File 类
java.io.FileFile类可以用于表示文件和目录路径名,但是不表示文件的内容。
静态成员变量
绝对路径和相对路径
绝对路径:一个完整地址
相对路径:简化的路径,将当前地址作为根目录
构造方法
File(String pathname):将给定的路径名字符串转换为抽象路径名来创建一个新File实例。
pathname可以以文件结尾,也可以以文件夹结尾;可以是相对路径,也可以是绝对路径;可以存在,也可以不存在。创建File对象,只是把字符串路径封装为File对象,无需考虑路径真假。
File(String parent, String child)
参数把路径分成了两部分,父路径和子路径可以单独书写,使用起来非常灵活。
File(File parent, String child)
父路径是File类型,可以使用File类的方法对路径进行一些操作。
常用方法
获取方法
String getAbsolutePath():返回此File的绝对路径名字符串
String getPath():将此File转换为路径名字符串(创建File时的pathname是什么样,就是什么样)
使用toString方法有相同的效果(调用了getPath方法)
String getName():返回File的构造方法传递的结尾部分(文件或目录的名称)
long length():返回File表示的文件的大小,以字节为单位
文件夹没有大小的概念,因此获取文件夹的大小会返回0;如果构造方法中给出的路径不存在,返回0。
判断方法
boolean exists():File表示的文件或者目录当前是否存在boolean isDirectory():File对象是否是目录boolean isFile():File对象是否是文件
isDirectory()和isFile()方法的正确发挥作用的前提是路径已存在,否则都会返回false。可以通过exist()先做判断:
File f = new File("C:\\download\\xx.torrent");
if(f.exists()) {
System.out.println(f.isFile());
}
创建和删除方法
boolean createNewFile():当且仅当具有该名称的文件不存在时,创建一个新的空文件。
boolean delete():删除由此File表示的文件或目录。
文件夹中有内容,则不会删除;路径不存在,会返回false。
delete方法是直接在硬盘删除文件/文件夹,不走回收站(直接永久删除),要慎用。
boolean mkdir():创建由此File表示的目录。
boolean mkdirs():创建由此File表示的目录,包括任何必需但不存在的父目录(相对于mkdir(),适用范围更广,推荐)。
遍历目录
String[] list():返回一个String数组,表示该File目录中的所有子文件或目录(子目录下的内容不会获取)。File[] listFiles():返回一个File数组,表示该File目录中的所有子文件或目录。
如果目录的路径不存在,或者路径不是一个目录,都会抛出空指针异常。
文件搜索
递归地列出一个目录下的所有文件:
public static void listAllFiles(File dir) {
if (dir == null || !dir.exists()) {
return;
}
if (dir.isFile()) {
System.out.println(dir.getName());
return;
}
for (File file : dir.listFiles()) {
listAllFiles(file);
}
}
文件过滤器
java.io.FileFilter是一个接口,是File的过滤器。该接口的对象可以传递给File类的listFiles(FileFilter)作为参数。
接口中的唯一方法:boolean accept(File pathname):测试指定文件对象是否应该包含在当前File目录中。
listFiles方法会调用参数传递的过滤器中的方法accept。
java.io.FilenameFilter是文件名称的过滤器。
接口中的唯一方法:boolean accept(File dir, String name):测试指定文件是否应该包含在某一文件列表中。
两个过滤器接口没有实现类,需要自己写实现类,重写accept方法,自定义过滤规则。
IO 流概述
数据的传输可以看作是一种数据的流动,根据数据的流向,可以分为输入流和输出流。根据数据的类型,可以分为字节流和字符流。
|
输入流 |
输出流 |
| 字节流 |
InputStream |
OutputStream |
| 字符流 |
Reader |
Writer |
字节流
字节输出流 OutputStream
java.io.OutputStream是一个抽象类,定义了一些成员方法如下:
void close():关闭输出流,并释放相关的系统资源void flush():刷新输出流,并强制任何缓冲的输出字节被写出void write(byte[] b):将指定的字节数组写入此输出流void write(byte[] b, int off, int len):从指定的字节数组写入len字节,从偏移量off开始输出到输出流abstract void write(int b):将指定的字节输出流
文件字节输出流 FileOutputStream
构造方法
FileOutputStream(String name):创建一个向具有指定名称的文件中写入数据的文件输出流
FileOutputStream(File file):创建一个向File对象表示的文件中写入数据的文件输出流
FileOutputStream(String name, boolean append)
append:追加写开关
true:创建对象不会覆盖源文件,在末尾追加写数据false:创建新文件,覆盖源文件(默认)
使用步骤
创建一个FileOutputStream对象,构造方法中传递写入数据的目的地
调用FileOutputStream对象中的write方法,把数据写入到文件中
当1次写多个字节时,写入的字节最后的显示:
- 如果写的第一个字节是正数(0-127),那么显示的时候会查询ASCII表。
- 如果写的第一个字节是负数,则第一个字节会和第二个字节组成一个中文显示,查询系统默认码表(GBK)。
释放资源(提高程序的效率)
写入字符的方法
可以使用String类中的方法byte[] getBytes(),把字符串转换为字节数组(默认编码方式一般为UTF-8)。
FileOutputStream fos = new FileOutputStream("C:\\download\\xx.md");
byte[] bytes = "Hellow World!".getBytes();
System.out.println(Arrays.toString(bytes));
System.out.println(new String(bytes));
fos.write(bytes);
fos.close();
换行写入
通过写换行符完成换行写入:
- windows:
\r\n
- linux:
/n
- mac:
/r
fos.write("\r\n".getBytes());
缓冲流有更跨平台的换行写入方式。
java.io.InputStream是一个抽象类,定义了一些成员方法如下:
void close(): 关闭输入流,并释放相关的系统资源
int read(): 从输入流读取并返回输入的下一个字节
返回-1时,表示读取到了eof(end of file)
int read(byte[] b): 从输入流读取多个字节,并存储到字节数组b中
- 数组b起到了缓冲作用,存储读取到的多个字节,能提高读取效率
- 数组的大小一般定义为1024(1kb)的整数倍
- 返回每次读取的有效字节个数(返回-1时,表示读取到了eof(end of file))
构造方法
FileInputStream(String name)FileInputStream(File file)
使用步骤
- 创建FileInputStream对象,构造方法中绑定要读取的数据源
- 使用FileInputStream对象中的read方法,读取文件
- 释放资源(提高程序的效率)
FileInputStream fis = new FileInputStream("C:\\download\\xx.md");
int len;
while ((len = fis.read()) != -1) {
System.out.print((char)len);
}
fis.close();
实现文件复制
public static void copyFile(String src, String dist) throws IOException {
FileInputStream fis = new FileInputStream(src);
FileOutputStream fos = new FileOutputStream(dist);
byte[] buffer = new byte[20 * 1024];
int cnt;
while ((cnt = fis.read(buffer)) != -1) {
fos.write(buffer, 0, cnt);
}
fis.close();
fos.close();
}
字符流
字节流读取中文的问题
字节流读取中文字符时,可能不会显示完整的字符,因为一个中文字符可能占用多个字节存储。所以Java提供了一些字符流类,以字符为单位读写数据,专门用于处理文本文件。
Reader 与 Writer
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符。但是在程序中操作的通常是字符形式的数据,因此需要提供对字符进行操作的方法。
InputStreamReader 实现从字节流解码成字符流OutputStreamWriter 实现字符流编码成字节流
字符输出流 Writer
java.io.Writer抽象类表示用于字符输出流的所有类的超类,可以将字符信息从内存存入磁盘。
void close():关闭输出流,并释放相关的系统资源void flush():刷新输出流,并强制任何缓冲的输出字符被写出void write(char[] cbuf):将指定的字符数组写入此输出流void write(char[] cbuf, int off, int len):从指定的字符数组写入len字节,从偏移量off开始输出到输出流void write(String str):将字符串写入输出流void write(String str, int off, int len):将子字符串写入输出流abstract void write(int b):将指定的字符输出流
文件字符输出流 FileWriter
java.io.FileWriterextends OutputStreamWriter extends Writer
构造方法
FileWriter(String name):创建一个向具有指定名称的文件中写入数据的文件输出流
FileWriter(File file):创建一个向File对象表示的文件中写入数据的文件输出流
FileWriter(String name, boolean append)
append:追加写开关
true:创建对象不会覆盖源文件,在末尾追加写数据false:创建新文件,覆盖源文件(默认)
使用步骤
- 创建一个FileWriter对象,构造方法中传递写入数据的目的地
- 调用FileWriter对象中的write方法,把数据写入到内存缓冲区中(有一个字符转换为字节的过程)
- 使用FileWriter对象中的flush方法,把内存缓冲区中的数据刷新到文件中
- 释放资源(也会执行把内存缓冲区中的数据刷新到文件中的操作,故第3步可以不显式写出来)
FileWriter fw = new FileWriter("C:\\download\\xx.md");
fw.write(97);
fw.flush();
fw.close();
换行写入
通过写换行符完成换行写入:
- windows:
\r\n
- linux:
/n
- mac:
/r
fw.writer("\r\n");
缓冲流有更跨平台的换行写入方式。
字符输入流 Reader
java.io.Reader抽象类表示用于字符输入流的所有类的超类,可以读取字符信息到内存中。
void close():关闭输入流,并释放相关的系统资源
int read():从输入流读取一个字符
返回-1时,表示读取到了eof(end of file)
int read(char[] cbuf):从输入流中读取多个字符,并将它们存储到字符数组cbuf中。
- 数组cbuf起到了缓冲作用,存储读取到的多个字符,能提高读取效率
- 数组的大小一般定义为1024(1kb)的整数倍
- 返回每次读取的有效字符个数(返回-1时,表示读取到了eof(end of file))
文件字符输入流 FileReader
java.io.FileReader extends InputStreamReader extends Reader
构造方法
FileReader(String fileName)FileReader(File file)
使用步骤
- 创建FileReader对象,构造方法中绑定要读取的数据源
- 使用FileReader对象中的read方法,读取文件
- 释放资源(提高程序的效率)
FileReader fr = new FileReader("C:\\download\\xx.md");
int len;
while ((len = fr.read()) != -1) {
System.out.print((char)len);
}
char[] chars = new char[2 * 1024];
len = 0;
while((len = fr.read(chars) != -1)) {
System.out.println(new String(chars, 0, len));
}
fr.close();
IO 异常的处理
JDK 7 之前的处理
实际开发中不应该直接抛出异常,而应该使用try...catch...finally代码块对异常进行处理。
FileWriter fw = null;
try {
fw = new FileWriter("C:\\download\\xx.md", true);
for (int i = 0; i < 10; i++) {
fw.write("Hellow world!" + i + "\r\n");
}
fw.close();
} catch (IOException e) {
System.,out.println(e);
} finally {
if(fw != null) {
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
JDK 7 的处理
JDK 7的新特性:在try后边可以增加一个(),在括号中可以定义流对象,则这个流对象的作用域就在try中有效,try中的代码执行完毕,会自动把流对象释放,不用写finally。
try (
FileInputStream fis = new FileInputStream("C:\\download\\xx.md");
FileOutputStream fos = new FileOutputStream("D:\\download\\1.jpg")) {
int len = 0;
while((len = fis.read()) != 1) {
fos.write(len);
}
} catch (IOException e) {
System.out.println(e);
}
属性集 Properties
java.util.Properties继承于HashTable,虽然HashTable是一个遗留类,但Properties作为唯一和IO流相结合的集合依然活跃着。Properties表示一个持久的属性集。它使用键值对存储数据,每个键和值都是字符串,因此Properties有一些操作字符串的特有方法:
Object setProperty(String key, String value)
String getProperty(String key)
Set<String> stringPropertyNames()
返回此属性列表中的键集。
Properties prop = new Properties();
prop.setProperty("邓肯", "21");
prop.setProperty("吉诺比利", "20");
prop.setProperty("吉诺比利", "9");
Set<String> set = prop.stringPropertyNames();
for (String key : set) {
String value = prop.getProperty(key);
System.out.println(key + "=" + value);
}
可以使用Properties集合中的store方法,把集合中的临时数据持久化写入到硬盘中。
void store(OutputStream out, String comments)
- OutputStream是字节输出流,不能写中文
- comments是注释,用来解释保存的文件的作用。(不能使用中文,会产生乱码,默认是Unicode编码)一般使用空字符串
""。
void store(Writer writer, String comments)
使用步骤:
- 创建Properties集合对象,添加数据
- 创建字节输出流/字符输出流对象
- 使用Properties集合的store方法,将集合中的临时数据持久化写入硬盘
- 释放资源
Properties prop = new Properties();
prop.setProperty("邓肯", "21");
prop.setProperty("吉诺比利", "20");
prop.setProperty("吉诺比利", "9");
FileWriter fw = new FileWriter("C:\\download\\xx.md");
prop.store(fw, "save data");
fw.close();
可以使用Properties集合中的load方法,把硬盘中保存的文件(键值对)读取到集合中使用。
使用步骤:
- 创建Properties集合对象
- 使用Properties集合的load方法,读取存储键值对的文件
- 键值对文件,键与值默认的连接符可以用
=、空格以及一些其他符号
- 文件中可以使用
#进行注释
- 文件中的键和值默认都是字符串,无需加引号
- 遍历Properties集合
- 释放资源
Properties prop = new Properties();
prop.load(new FileReader("C:\\download\\xx.md"));
for (String key : set) {
String value = prop.getProperty(key);
System.out.println(key + "=" + value);
}
fw.close();
缓冲流
缓冲流也叫高效流,是对4个基本的FileXxx流的增强,所以也是4个流。缓冲流的基本原理,是在创建流对象时,创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少IO次数,从而提高读写的效率。
缓冲字节输出流 BufferedOutputStream
java.io.BufferedOutputStream extends OutputStream
构造方法
BufferedOutputStream(OutputStream out)
创建一个缓冲输出流,将数据写入指定的底层输出流
BufferedOutputStream(OutputStream out, int size)
创建一个缓冲输出流,将具有指定缓冲区大小的数据写入指定的底层输出流
使用步骤
- 创建FileOutputSream对象,构造方法中绑定要输出的目的地
- 创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象,提高FileOutputStream对象的效率
- 使用BufferedOutputStream对象的write方法,将数据写入内部缓冲区
- 使用BufferedOutputStream对象的flush方法,将内部缓冲区中的数据刷新到文件中
- 释放资源(也会执行把内存缓冲区中的数据刷新到文件中的操作,故第4步可以不显式写出来)
FileOutputStream fos = new FileOutputStream("C:\\download\\xx.md");
BufferedOutputStream bos = new BufferedOutputStream(fos);
bos.write("把数据写入到内部缓冲区中".getBytes());
bos.flush();
bos.close();
java.io.BufferedInputStream extends InputStream
构造方法
BufferedInputStream(InputStream in)
创建一个缓冲输入流,并保存输入流in,以便将来使用
BufferedInputStream(InputStream in, int size)
创建一个缓冲输入流,将具有指定缓冲区大小的数据写入指定的底层输入流
使用步骤
- 创建FileInputSream对象,构造方法中绑定要读取的数据源
- 创建BufferedInputStream对象,构造方法中传递FileInputStream对象,提高FileInputStream对象的效率
- 使用BufferedInputStream对象的read方法,将数据存入缓冲区数组
- 释放资源
FileInputStream fis = new FileInputStream("C:\\download\\xx.md");
BufferedInputStream bis = new BufferedInputStream(fis);
byte[] bytes = new byte[1024];
int len = 0;
while((len = bis.read(bytes)) != -1) {
System.out.println(new String(bytes, 0 ,len));
}
bis.close();
实现文件复制
和使用基本字节流进行文件复制相比,效率明显提升(1次读取单个字节或多个字节都是如此)。
long s = System.currentTimeMills();
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("C:\\download\\xx.md"));
BufferedOutStream bos = new BufferedOutputStream(new FileOutputStream("C:\\download\\yy.md"));
byte[] bytes = new byte[1024];
int len = 0;
while((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
}
bis.close();
bos.close();
long e = System.currentTimeMills();
System.out.println("程序共耗时:" + (e - s) + "毫秒");
缓冲字符输出流 BufferedWriter
java.io.BufferedWriter extends Writer
构造方法
特有的成员方法
void newLine():写入一个行分隔符(根据不同的操作系统,获取不同的行分隔符)
使用步骤
- 创建缓冲字符输出流对象,构造方法中传递字符输出流
- 调用缓冲字符输出流的write方法,把数据写入到内存缓冲区中
- 调用缓冲字符输出流的flush方法,把内存缓冲区中的数据刷新到文件中
- 释放资源
BufferedWriter bw = new BufferedWriter(new FileWriter("C:\\download\\xx.md"));
for(int i = 0; i < 10; i++) {
bw.write("机智医生生活");
bw.newLine();
}
bw.flush();
bw.close();
缓冲字符输入流 BufferedReader
java.io.BufferedReader extends Reader
构造方法
BufferedReader(Reader in)BufferedReader(Reader in, int size)
特有的成员方法
String ReadLine():读取一个文本行(根据不同的操作系统,获取不同的行分隔符)
返回该行内容的字符串,不包含任何行分隔符。如果已到达流末尾,则返回null。
逐行读取文本文件的内容
BufferedReader br = new BufferedReader(new FileReader("C:\\download\\xx.md"));
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
编码与解码
编码就是把字符转换为字节,而解码是把字节重新组合成字符。如果编码和解码过程使用不同的编码方式那么就出现了乱码。
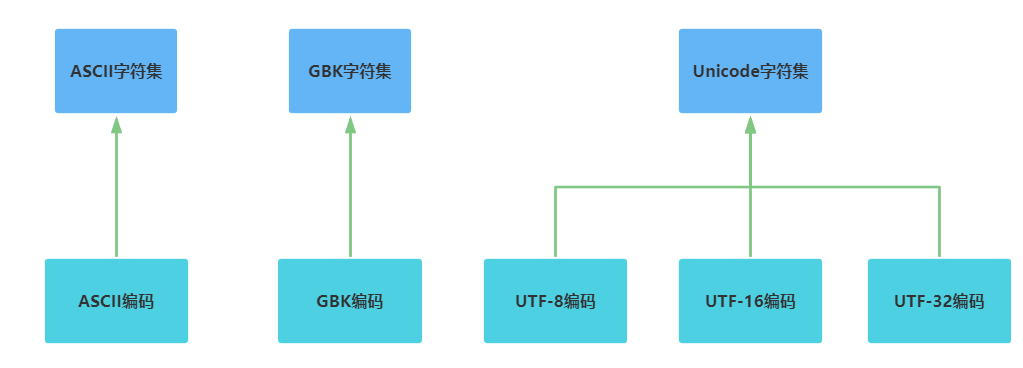
字符集 charset
字符集也叫编码表。是一个系统支持的所有字符的集合,包括文字、标点符号、图形符号、数字等。常见的字符集有ASCII、GBK、Unicode等。
大端模式:高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
(符合直观上认为的模式)
小端模式:低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
从软件的角度理解端模式:
不同端模式的处理器进行数据传递时必须要考虑端模式的不同。在Socket接口编程中,以下几个函数用于大小端字节序的转换
#define ntohs(n)
#define htons(n)
#define ntohl(n)
#define htonl(n)
其中互联网使用的网络字节顺序采用大端模式进行编址,而主机字节顺序根据处理器的不同而不同,如PowerPC处理器使用大端模式,而Pentuim处理器使用小端模式。
Java 的内存编码使用双字节编码 UTF-16be,这不是指 Java 只支持这一种编码方式,而是说 char 这种类型使用 UTF-16be 进行编码。char 类型占 16 位,也就是两个字节,Java 使用这种双字节编码是为了让一个中文或者一个英文都能使用一个 char 来存储。
String的编码方式
String可以看成一个字符序列,可以指定一个编码方式将它编码为字节序列,也可以指定一个编码方式将一个字节序列解码为String。
String str1 = "中文";
byte[] bytes = str1.getBytes("UTF-8");
String str2 = new String(bytes, "UTF-8");
System.out.println(str2);
在调用无参数 getBytes() 方法时,默认的编码方式不是 UTF-16be。双字节编码的好处是可以使用一个 char 存储中文和英文,而将 String 转为 bytes[] 字节数组就不再需要这个好处,因此也就不再需要双字节编码。getBytes() 的默认编码方式与平台有关,一般为 UTF-8。
编码引起的问题
在IDEA中,使用FileReader读取项目中的文本文件。由于IDEA的设置,都是默认UTF-8编码,所以没有任何问题。但是,当读取Windows系统中创建的文本文件时,由于Windows系统默认的是GBK编码,所以会出现乱码。那么该如何读取GBK编码的文件?
转换流
OutputStreamWriter 类
转换流java.io.OutputStreamWriter是Writer的子类,是从字符流到字节流的桥梁。它读取字符,并使用指定的字符集将其编码为字节。
构造方法:
OutputStreamWriter(OutputStream out)
OutputStreamWriter(OutputStream out, String charsetName)
charsetName用于指定字符集,不区分大小写。
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("C:\\download\\xx.md"), "GBK");
osw.write("机智医生生活");
osw.flush();
osw.close();
转换流java.io.InputStreamReader是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。
构造方法:
InputStreamReader(InputStream in)
InputStreamReader(InputStream in, String charsetName):
charsetName用于指定字符集,不区分大小写。
InputStreamReader isr = new InputStreamReader(new FileInputStream("C:\\download\\xx.md"), "GBK");
int len = 0;
while((len = isr.read() != -1)) {
System.out.println((char)len);
}
char[] chars = new char[2 * 1024];
len = 0;
while((len = isr.read(chars) != -1)) {
System.out.println(new String(chars, 0, len));
}
isr.close();
转换文件编码
将GBK编码的文本文件,转换为UTF-8编码的文本文件。
- 指定GBK编码的转换流,读取文本文件
- 指定UTF-8编码的转换流,写入文本文件
InputStreamReader isr = new InputStreamReader(new FileInputStream("C:\\download\\xx.md"), "GBK");
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("C:\\download\\yy.md"), "UTF-8");
int len = 0;
while((len = isr.read() != -1)) {
osw.write(len);
}
装饰者模式
以InputStream为例,
序列化
序列化就是将一个对象转换成字节序列,该字节序列包含对象的数据、对象的类型以及对象中存储的属性。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
- 序列化:
void ObjectOutputStream.writeObject()
- 反序列化:
Object ObjectInputStream.readObject()
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
Serializable 接口
序列化的类需要实现Serializable接口,它只是一个标准,没有任何方法需要实现。但如果不去实现它的话,会抛出异常。
public static void main(String[] args) throws IOException, ClassNotFoundException {
A a1 = new A(123, "abc");
String objectFile = "C:\\download\\a1.md";
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(objectFile));
oos.writeObject(a1);
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(objectFile));
A a2 = (A) ois.readObject();
ois.close();
System.out.println(a2);
}
private static class A implements Serializable {
private int x;
private String y;
A(int x, String y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return "x = " + x + " " + "y = " + y;
}
}
InvalidClassException 异常
当JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个InvalidClassException异常。
发生该异常的原因有:
- 该类的序列版本号与从流中读取的类描述符的版本号不一致
- 该类包含未知数据类型
- 该类没有可访问的无参数构造方法
Serializable接口给需要序列化的类提供了一个序列版本号serialVersionUID,用于验证序列化的对象和对应类是否版本匹配。
解决方案:
无论是否对类的定义进行修改,都不重新生成新的序列号。可序列化的类通过声明static final long serialVersionUID来显式声明自己的序列号。
public class A implements Serializable {
private static final long serialVersionUID = 20L;
private int x;
private String y;
A(int x, String y) {
this.x = x;
this.y = y;
}
@Override
public String toString() {
return "x = " + x + " " + "y = " + y;
}
}
IDEA自动生成序列号
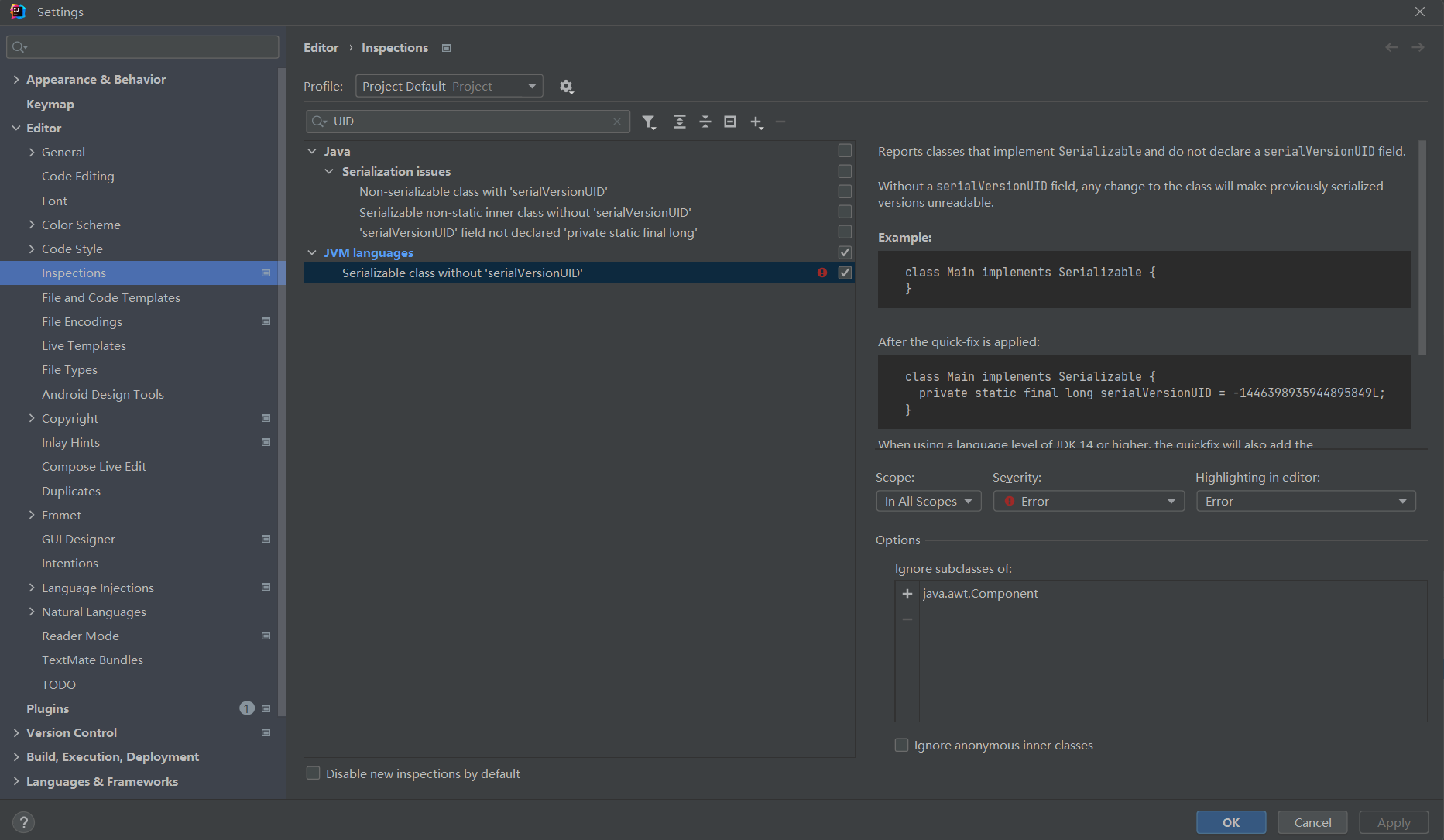
Settings - Editor - Inspections - 搜索UID - Serializable class without ‘serialVersionUID’ 右侧勾选,修改Severity为Error。
transient 关键字
transient(瞬态)关键字可以使一些属性不会被序列化。
ArrayList中存储数据的数组elementData是用transient修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就不需要所有的内容都被序列化。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
序列化集合
当想在文件中保存多个对象的时候,可以把对象存储到一个集合中,对集合进行序列化和反序列化。
ArrayList<A> list = new ArrayList<>();
list.add(new A(20, "吉诺比利"));
list.add(new A(21, "邓肯"));
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("C:\\download\\Spurs.md"));
oos.writeObject(list);
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("C:\\download\\Spurs.md"));
ArrayList<A> list2 = (ArrayList<A>)ois.readObject();
for (A a : list2) {
System.out.println(a);
}
ois.close();
打印流
java.io.PrintStream extends OutputStream与其他输出流不同,永远不会抛出IOException。
特有的方法:
void print(任意类型的值)void println(任意类型的值)
构造方法:
PrintStream(File file):输出至文件PrintStream(OutputStream out):输出至字节输出流PrintStream(String fileName):输出至指定的文件路径
注意:
如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表97 -> a;如果使用自己特有的print/println方法写数据,原样输出97 -> 97。
打印流还可以改变输出语句System.out.print/println的目的地:
static void System.setOut(PrintStream out)
System.out.println("默认在控制台输出");
PrintStream ps = new PrintStream("C:\\download\\Spurs.md");
System.setOut(ps);
System.out.println("在打印流的目的地中输出");
ps.close();